Benchmarking Large Language Models for Math Reasoning Tasks
作者: Kathrin Seßler, Yao Rong, Emek Gözlüklü, Enkelejda Kasneci
分类: cs.CL, cs.LG
发布日期: 2024-08-20 (更新: 2024-12-19)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
数学推理任务LLM基准测试:比较不同模型和上下文学习算法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 基准测试 上下文学习 模型评估
📋 核心要点
- 现有数学推理LLM研究缺乏跨数据集的全面基准,难以针对特定任务选择合适的模型。
- 论文提出一个基准测试,比较不同LLM和上下文学习算法在数学问题求解上的性能。
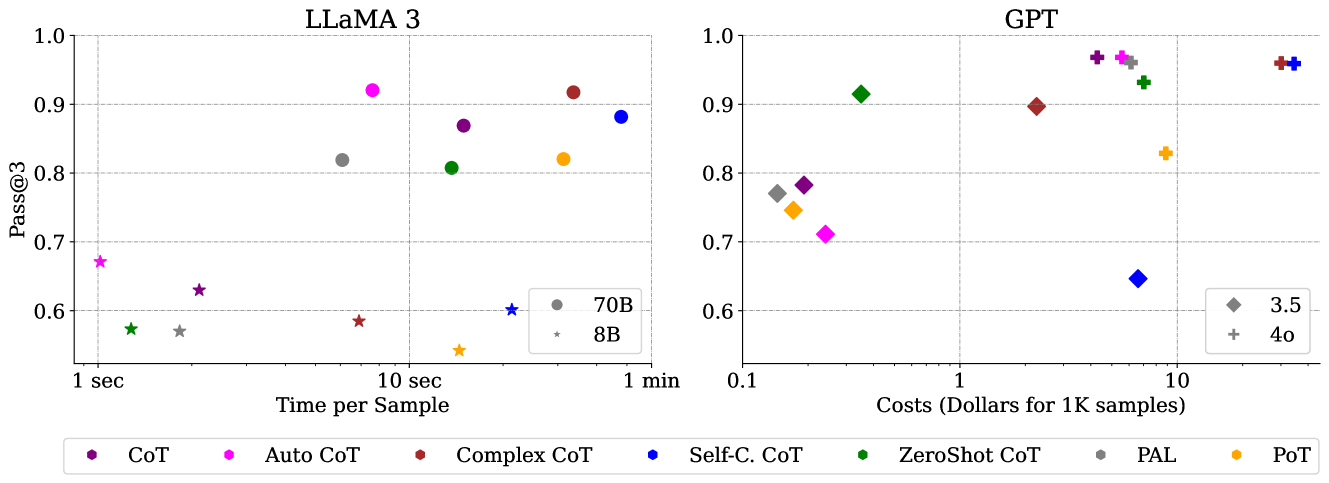
- 实验结果表明,大型模型如GPT-4o和LLaMA 3-70B对提示策略不敏感,小型模型则依赖上下文学习。
📝 摘要(中文)
大型语言模型(LLM)在数学推理中的应用已成为相关研究的基石,展示了这些模型的智能,并通过其先进的性能实现了潜在的实际应用,例如在教育环境中。尽管有各种数据集和上下文学习算法旨在提高LLM自动化解决数学问题的能力,但缺乏跨不同数据集的全面基准测试使得为特定任务选择合适的模型变得复杂。本项目提出了一个基准,在四个强大的基础模型上,公平地比较了七种最先进的上下文学习算法在五个广泛使用的数学数据集上的数学问题求解能力。此外,我们还探讨了效率和性能之间的权衡,突出了LLM在数学推理中的实际应用。结果表明,像GPT-4o和LLaMA 3-70B这样更大的基础模型可以独立于具体的提示策略解决数学推理问题,而对于较小的模型,上下文学习方法会显著影响性能。此外,最佳提示取决于所选择的基础模型。我们开源了我们的基准测试代码,以支持未来研究中集成更多模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在数学推理任务中,由于缺乏统一的评估标准和基准测试,导致难以选择合适的模型和上下文学习算法的问题。现有方法缺乏对不同模型和算法在不同数据集上的性能进行全面比较,使得实际应用中模型选择缺乏依据。
核心思路:论文的核心思路是构建一个全面的基准测试平台,通过在多个数据集上评估不同LLM和上下文学习算法的性能,从而为用户提供模型选择的参考。通过系统性的实验,揭示不同模型和算法的优缺点,以及它们在不同任务上的适用性。
技术框架:该基准测试框架主要包含以下几个模块:1)数据集模块:收集并整理了五个广泛使用的数学推理数据集。2)模型模块:集成了四个强大的基础模型,包括GPT-4o和LLaMA 3-70B等。3)上下文学习算法模块:实现了七种最先进的上下文学习算法。4)评估模块:设计了统一的评估指标,用于衡量模型在不同数据集上的性能。5)结果分析模块:对实验结果进行统计分析,并可视化展示不同模型和算法的性能对比。
关键创新:论文的关键创新在于构建了一个全面的、可扩展的数学推理LLM基准测试平台。该平台不仅提供了多种模型和算法的性能对比,还开源了基准测试代码,方便其他研究者集成更多模型和算法。此外,论文还深入分析了不同模型和算法的优缺点,以及它们在不同任务上的适用性,为用户提供了有价值的参考。
关键设计:论文的关键设计包括:1)选择了五个广泛使用的数学推理数据集,保证了基准测试的代表性。2)集成了四个强大的基础模型,覆盖了不同规模和架构的LLM。3)实现了七种最先进的上下文学习算法,涵盖了不同的提示策略。4)设计了统一的评估指标,包括准确率、召回率等,用于衡量模型在不同数据集上的性能。5)开源了基准测试代码,方便其他研究者进行扩展和改进。
🖼️ 关键图片
📊 实验亮点
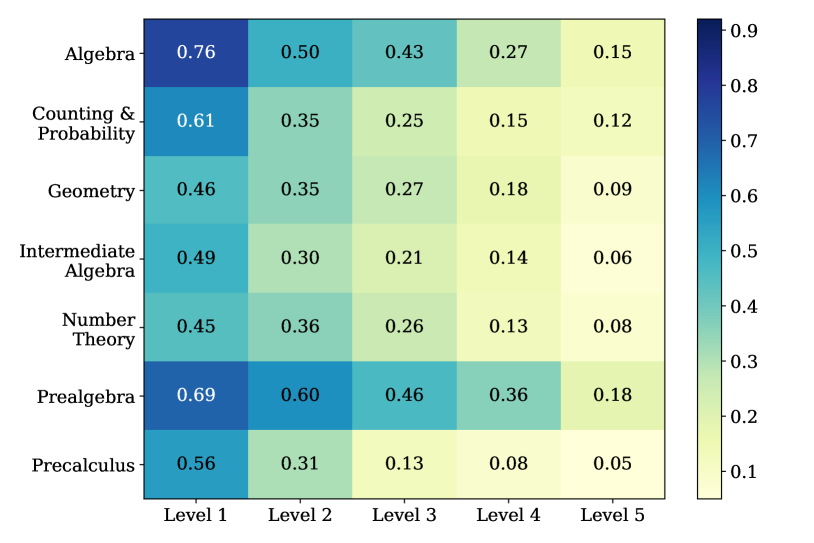
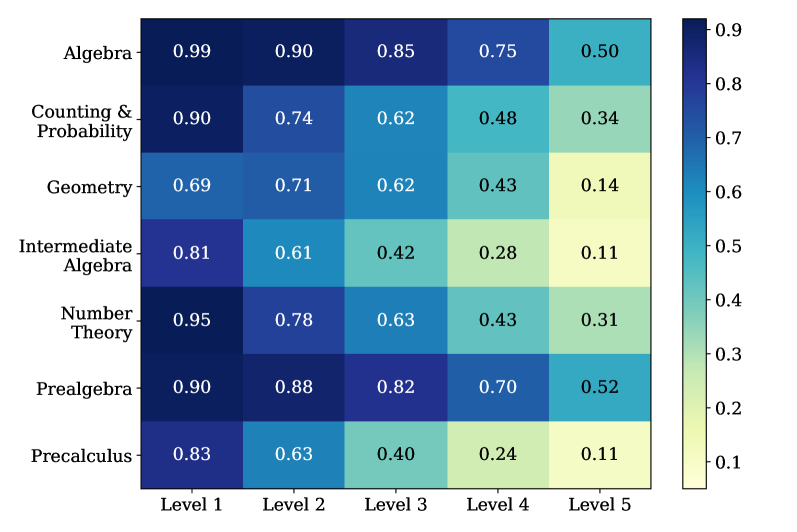
实验结果表明,大型模型如GPT-4o和LLaMA 3-70B在数学推理任务中表现出色,且对提示策略的依赖性较低。对于较小的模型,上下文学习方法对性能有显著影响。此外,最佳提示策略取决于所选择的基础模型。该基准测试为选择合适的LLM和上下文学习算法提供了重要参考。
🎯 应用场景
该研究成果可广泛应用于教育、科研等领域。在教育领域,可以帮助学生和教师选择合适的LLM辅助学习和教学。在科研领域,可以为研究者提供一个评估和比较不同LLM在数学推理任务上的性能的平台,促进相关研究的进展。此外,该研究还可以应用于智能客服、金融分析等需要数学推理能力的场景。
📄 摘要(原文)
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.