Towards Efficient Large Language Models for Scientific Text: A Review
作者: Huy Quoc To, Ming Liu, Guangyan Huang
分类: cs.CL, cs.AI
发布日期: 2024-08-20
💡 一句话要点
针对科学文本的高效大型语言模型研究综述:模型小型化与数据质量提升
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科学文本 模型小型化 数据质量 知识蒸馏 模型剪枝 领域自适应 计算效率
📋 核心要点
- 现有科学领域的大型语言模型面临计算资源需求高、训练成本昂贵的挑战,阻碍了其广泛应用。
- 本文综述了通过模型小型化和数据质量提升两种主要策略,降低科学LLM成本的研究进展。
- 该综述旨在为科学领域开发经济高效的LLM解决方案提供指导,并探讨了未来发展方向。
📝 摘要(中文)
大型语言模型(LLMs)的出现为处理包括科学在内的各个领域的复杂信息开创了一个新时代。 越来越多的科学文献使得这些模型能够有效地获取和理解科学知识,从而提高它们在各种任务中的性能。 鉴于LLMs的强大能力,它们需要极其昂贵的计算资源、大量的数据和训练时间。 因此,近年来,研究人员提出了各种方法来降低科学LLMs的成本。 最著名的两种方法主要集中在两个方向:模型规模的缩小和数据质量的提升。 目前,尚未对这两类方法进行全面的综述。 在本文中,我们(I)总结了LLMs新兴能力方面的最新进展,将其转化为更易于使用的科学AI解决方案,以及(II)研究了使用LLMs为科学领域开发经济实惠的解决方案所面临的挑战和机遇。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在科学文本处理方面表现出色,但其庞大的模型规模导致计算资源需求高昂,训练时间长,成本巨大。这限制了它们在资源有限的科研机构和个人研究者中的应用。因此,如何降低科学LLMs的计算成本,使其更易于访问和使用,是一个亟待解决的问题。
核心思路:本文的核心思路是对现有降低科学LLMs成本的方法进行系统性的综述和分类,主要聚焦于两个方向:一是模型小型化,即通过各种技术手段减少模型参数量,降低计算复杂度;二是数据质量提升,即通过优化训练数据,提高模型的学习效率和泛化能力。通过分析这两种策略的优缺点和适用场景,为研究人员提供选择和改进方向的参考。
技术框架:本文的综述框架主要包含以下几个部分:首先,介绍大型语言模型在科学文本处理中的应用和优势;其次,详细阐述模型小型化的各种技术,例如知识蒸馏、模型剪枝、量化等;然后,深入探讨数据质量提升的方法,包括数据增强、数据清洗、领域自适应预训练等;最后,总结当前研究的挑战和机遇,并展望未来发展方向。
关键创新:本文的创新之处在于对科学LLMs的经济性问题进行了全面的综述,并将其归纳为模型小型化和数据质量提升两个主要方向。此前,虽然有针对特定技术(如知识蒸馏)的综述,但缺乏对整个领域系统性的分析和总结。本文填补了这一空白,为研究人员提供了一个更广阔的视角,帮助他们更好地理解和解决科学LLMs的经济性问题。
关键设计:本文的关键设计在于对现有方法的分类和组织方式。通过将研究方向归纳为模型小型化和数据质量提升,可以更清晰地呈现不同方法之间的联系和区别。此外,本文还关注了不同方法在不同科学领域的适用性,以及它们在降低计算成本和提高模型性能之间的权衡。
🖼️ 关键图片
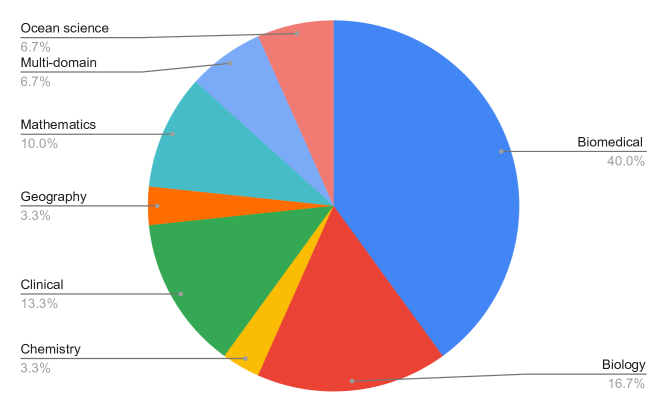
📊 实验亮点
本文对现有降低科学LLM成本的方法进行了系统性综述,重点关注模型小型化和数据质量提升两大方向。通过对各种方法的优缺点进行分析,为研究人员提供了选择和改进方向的参考。该综述有助于推动科学LLM在资源有限的环境下的应用。
🎯 应用场景
该研究成果可应用于科学文献检索、科学知识抽取、科学问题回答、科研辅助工具开发等领域。通过降低科学LLM的使用成本,可以促进其在科研领域的广泛应用,加速科学研究的进程,并为科研人员提供更智能、更高效的工具。
📄 摘要(原文)
Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.