Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution
作者: Yucheng Ruan, Xiang Lan, Jingying Ma, Yizhi Dong, Kai He, Mengling Feng
分类: cs.CL
发布日期: 2024-08-20
🔗 代码/项目: GITHUB
💡 一句话要点
综述表格数据语言建模:回顾基础、技术与演进
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 语言建模 Transformer 预训练语言模型 大型语言模型
📋 核心要点
- 表格数据具有异构性和复杂结构关系,传统分析方法难以兼顾高性能和鲁棒性。
- 借鉴自然语言处理的Transformer架构,将表格数据转化为序列,利用语言模型进行建模。
- 综述回顾了表格数据语言建模的演进,从预训练Transformer到利用大型语言模型。
📝 摘要(中文)
表格数据作为一种普遍存在的数据类型,因其异构性和复杂的结构关系而面临独特的挑战。在表格数据分析中实现高预测性能和鲁棒性,对于众多应用具有重要意义。受自然语言处理(特别是Transformer架构)最新进展的影响,表格数据建模的新方法不断涌现。早期技术侧重于从头开始预训练Transformer,但常遇到可扩展性问题。随后,开发了利用预训练语言模型(如BERT)的方法,这些方法需要更少的数据并产生更高的性能。最近,大型语言模型(如GPT和LLaMA)的出现进一步革新了该领域,通过最少的微调促进了更高级和多样化的应用。尽管人们对此越来越感兴趣,但仍然缺乏对表格数据语言建模技术的全面综述。本文填补了这一空白,系统地回顾了表格数据语言建模的发展,包括:(1) 不同表格数据结构和数据类型的分类;(2) 模型训练中使用的关键数据集和评估任务的回顾;(3) 建模技术的总结,包括广泛采用的数据处理方法、流行的架构和训练目标;(4) 从适应传统预训练/预训练语言模型到利用大型语言模型的演变;(5) 识别表格数据分析语言建模中持续存在的挑战和潜在的未来研究方向。
🔬 方法详解
问题定义:表格数据分析面临异构性和复杂结构关系的挑战,传统方法难以充分利用这些信息。现有方法在处理大规模表格数据时,可能存在可扩展性问题,且对于不同类型表格数据的泛化能力有限。
核心思路:将表格数据视为一种特殊的“语言”,利用自然语言处理中的语言模型来学习表格数据的内在结构和关系。通过将表格数据转换为序列形式,可以利用Transformer等架构强大的序列建模能力。
技术框架:该综述涵盖了表格数据语言建模的整个流程,包括数据预处理(例如,数据类型识别、缺失值处理、特征编码),模型架构选择(例如,Transformer、BERT、GPT),以及训练目标设计(例如,掩码语言建模、对比学习)。重点关注了从传统预训练到利用大型语言模型的演进过程。
关键创新:核心在于将自然语言处理的技术应用于表格数据分析,利用预训练语言模型强大的表征学习能力,从而提升表格数据分析的性能和泛化能力。从最初的从头训练Transformer,到利用预训练的BERT等模型,再到最近利用大型语言模型,体现了技术发展的趋势。
关键设计:关键设计包括如何将表格数据转换为适合语言模型处理的序列形式,例如,将每一行或每一列视为一个句子。此外,还需要设计合适的训练目标,例如,掩码表格中的某些单元格,然后让模型预测这些被掩码的值。对于大型语言模型,如何进行高效的微调也是一个关键问题。
🖼️ 关键图片
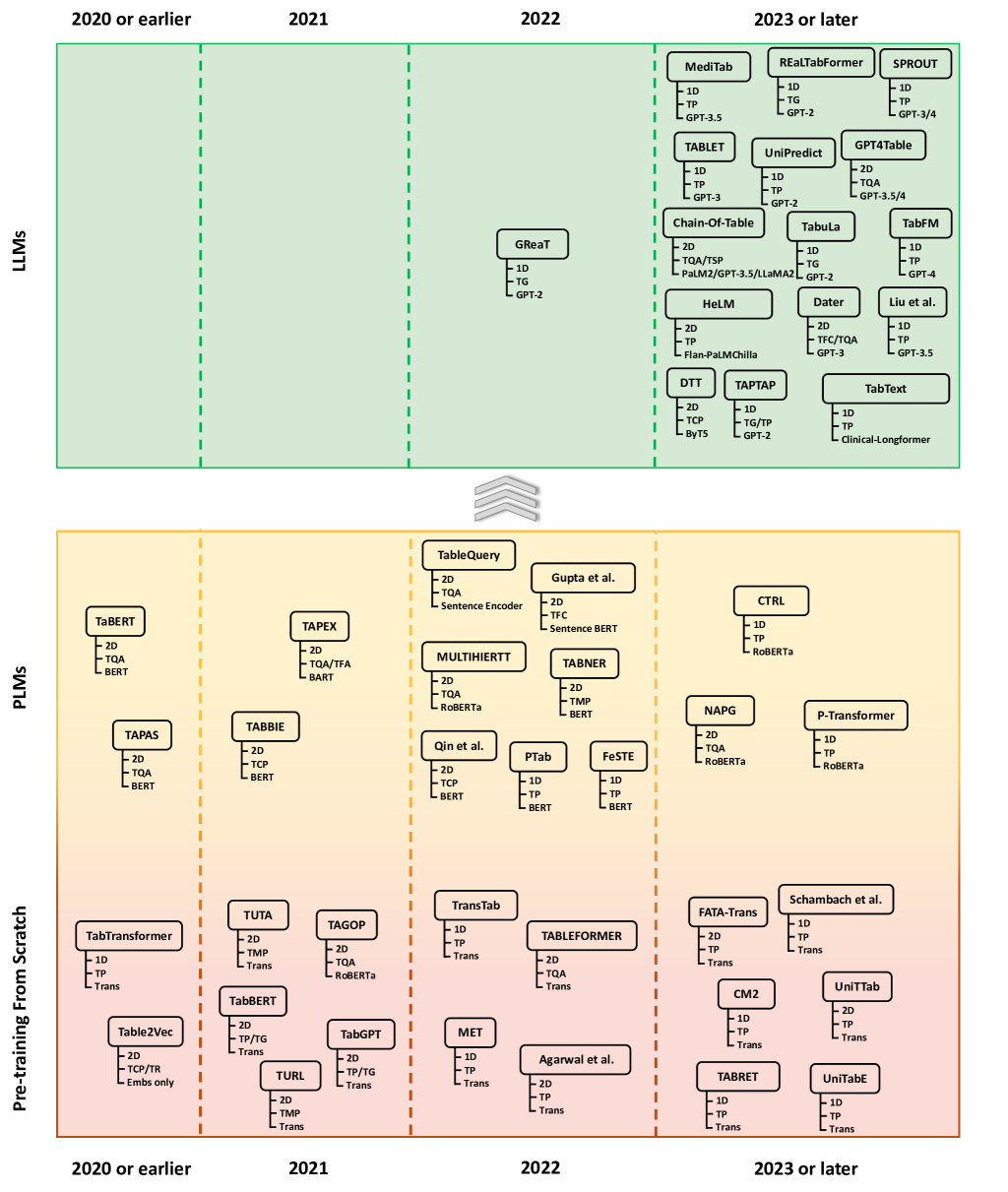


📊 实验亮点
该综述系统地回顾了表格数据语言建模的发展历程,总结了不同阶段的关键技术和方法,并指出了当前面临的挑战和未来的研究方向。通过对现有方法的分类和比较,为研究人员提供了有价值的参考,有助于推动该领域的发展。
🎯 应用场景
该研究成果可广泛应用于金融、医疗、电商等领域,提升表格数据分析的效率和准确性。例如,在金融领域,可以用于风险评估、信用评分;在医疗领域,可以用于疾病诊断、药物研发;在电商领域,可以用于用户行为分析、商品推荐。未来,随着大型语言模型的不断发展,表格数据语言建模的应用前景将更加广阔。
📄 摘要(原文)
Tabular data, a prevalent data type across various domains, presents unique challenges due to its heterogeneous nature and complex structural relationships. Achieving high predictive performance and robustness in tabular data analysis holds significant promise for numerous applications. Influenced by recent advancements in natural language processing, particularly transformer architectures, new methods for tabular data modeling have emerged. Early techniques concentrated on pre-training transformers from scratch, often encountering scalability issues. Subsequently, methods leveraging pre-trained language models like BERT have been developed, which require less data and yield enhanced performance. The recent advent of large language models, such as GPT and LLaMA, has further revolutionized the field, facilitating more advanced and diverse applications with minimal fine-tuning. Despite the growing interest, a comprehensive survey of language modeling techniques for tabular data remains absent. This paper fills this gap by providing a systematic review of the development of language modeling for tabular data, encompassing: (1) a categorization of different tabular data structures and data types; (2) a review of key datasets used in model training and tasks used for evaluation; (3) a summary of modeling techniques including widely-adopted data processing methods, popular architectures, and training objectives; (4) the evolution from adapting traditional Pre-training/Pre-trained language models to the utilization of large language models; (5) an identification of persistent challenges and potential future research directions in language modeling for tabular data analysis. GitHub page associated with this survey is available at: https://github.com/lanxiang1017/Language-Modeling-on-Tabular-Data-Survey.git.