Performance Law of Large Language Models
作者: Chuhan Wu, Ruiming Tang
分类: cs.CL, cs.LG
发布日期: 2024-08-19 (更新: 2024-09-13)
备注: Personal opinions of the authors
💡 一句话要点
提出“性能定律”,通过少量超参数精确预测大语言模型的MMLU得分。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 性能预测 MMLU得分 规模定律 经验公式
📋 核心要点
- 现有规模定律仅能定性估计LLM的损失,无法准确预测实际应用中的性能表现。
- 论文提出“性能定律”,通过模型架构的关键超参数和训练数据量直接预测MMLU得分。
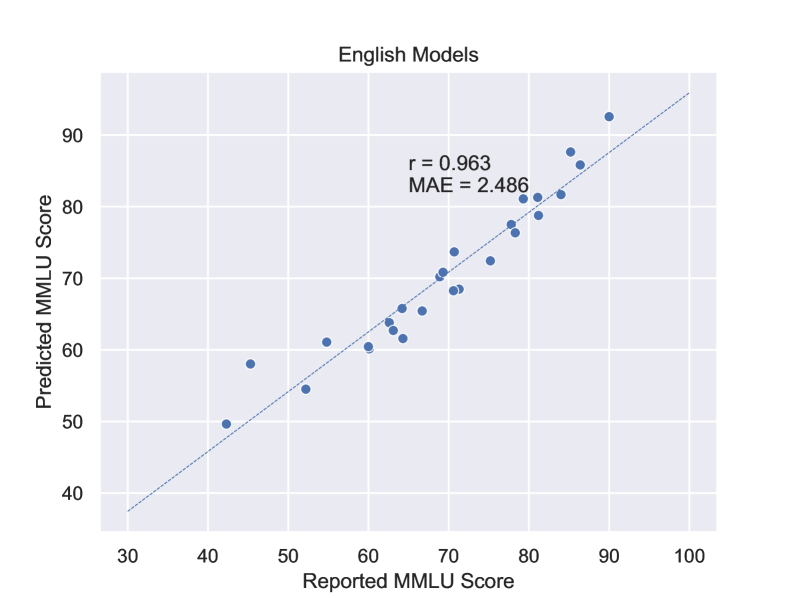
- 实验表明,该定律能准确预测不同机构开发的多种LLM的MMLU得分,指导资源分配。
📝 摘要(中文)
近年来,在大规模定律的指导下,大型语言模型(LLMs)取得了令人瞩目的性能。然而,规模定律仅对损失进行定性估计,而损失受多种因素影响,如模型架构、数据分布、分词器和计算精度。因此,估计具有不同训练设置的LLM的实际性能(而非损失)在实际开发中可能非常有用。在本文中,我们提出了一个名为“性能定律”的经验公式,用于直接预测LLM的MMLU得分,MMLU得分是广泛使用的指标,用于指示LLM在实际对话和应用中的通用能力。仅基于LLM架构的几个关键超参数和训练数据的大小,我们就获得了对不同组织在不同年份开发的不同大小和架构的各种LLM的相当准确的MMLU预测。性能定律可用于指导LLM架构的选择和计算资源的有效分配,而无需进行广泛的实验。
🔬 方法详解
问题定义:论文旨在解决如何准确预测大语言模型(LLM)在实际应用中的性能问题,特别是MMLU得分。现有方法依赖于规模定律,但该定律只能定性估计损失,无法考虑模型架构、数据分布等多种因素的影响,导致预测精度不足。现有方法需要大量的实验才能确定最佳的模型架构和资源分配方案,成本高昂。
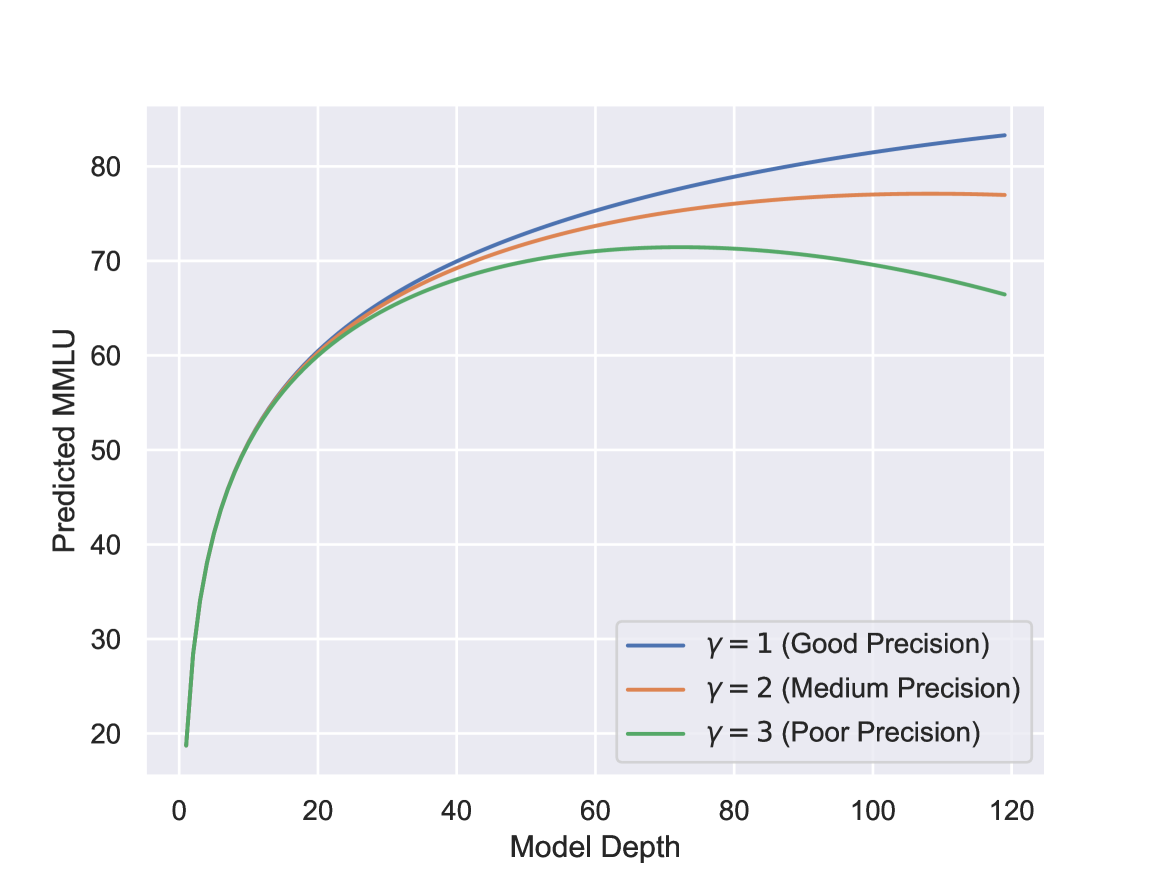
核心思路:论文的核心思路是建立一个经验公式,即“性能定律”,该公式能够直接根据LLM的几个关键超参数(例如模型大小、参数量)和训练数据量来预测其MMLU得分。这种方法避免了复杂的损失估计和大量的实验,从而能够快速评估不同LLM配置的性能。
技术框架:论文提出的“性能定律”是一个经验公式,具体形式未知(论文中未明确给出公式的具体形式,需要查阅原文)。该公式以LLM的架构超参数和训练数据大小作为输入,直接输出MMLU得分的预测值。整体流程简单直接,无需复杂的训练或推理过程。
关键创新:该方法最重要的创新在于,它提供了一种直接预测LLM性能的途径,而无需依赖于传统的损失估计或大规模实验。这种方法能够显著降低LLM开发和部署的成本,并加速LLM的迭代过程。与现有方法相比,该方法更加高效、实用,能够更好地指导LLM的架构选择和资源分配。
关键设计:论文的关键设计在于如何选择合适的超参数和训练数据量作为输入,以及如何构建能够准确反映这些因素与MMLU得分之间关系的经验公式。具体的参数设置、损失函数和网络结构等技术细节未知,需要查阅原文以获取更详细的信息。
🖼️ 关键图片

📊 实验亮点
论文提出的“性能定律”能够准确预测不同机构开发的多种LLM的MMLU得分。实验结果表明,该定律能够有效地指导LLM架构的选择和计算资源的分配,而无需进行大量的实验。具体的性能数据和提升幅度未知,需要查阅原文以获取更详细的信息。
🎯 应用场景
该研究成果可广泛应用于大语言模型的开发和部署过程中。开发者可以利用“性能定律”快速评估不同模型架构和训练数据规模下的性能表现,从而选择最优的配置方案。此外,该定律还可以用于指导计算资源的分配,避免不必要的浪费,提高开发效率。该研究有望加速大语言模型在各个领域的应用,例如智能客服、文本生成、机器翻译等。
📄 摘要(原文)
Guided by the belief of the scaling law, large language models (LLMs) have achieved impressive performance in recent years. However, scaling law only gives a qualitative estimation of loss, which is influenced by various factors such as model architectures, data distributions, tokenizers, and computation precision. Thus, estimating the real performance of LLMs with different training settings rather than loss may be quite useful in practical development. In this article, we present an empirical equation named "Performance Law" to directly predict the MMLU score of an LLM, which is a widely used metric to indicate the general capability of LLMs in real-world conversations and applications. Based on only a few key hyperparameters of the LLM architecture and the size of training data, we obtain a quite accurate MMLU prediction of various LLMs with diverse sizes and architectures developed by different organizations in different years. Performance law can be used to guide the choice of LLM architecture and the effective allocation of computational resources without extensive experiments.