Importance Weighting Can Help Large Language Models Self-Improve
作者: Chunyang Jiang, Chi-min Chan, Wei Xue, Qifeng Liu, Yike Guo
分类: cs.CL, cs.AI
发布日期: 2024-08-19 (更新: 2024-12-12)
💡 一句话要点
提出基于重要性权重的LLM自提升方法,有效过滤高分布偏移样本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自提升 重要性权重 分布偏移 数据过滤 自洽性 推理能力
📋 核心要点
- 现有LLM自提升方法依赖答案正确性过滤,忽略了高分布偏移样本可能带来的负面影响。
- 论文提出DS权重来近似分布偏移程度,结合自洽性过滤,提升自生成数据的质量。
- 实验表明,仅用少量数据计算DS权重,即可显著提升LLM的推理能力,媲美外部监督方法。
📝 摘要(中文)
大型语言模型(LLM)在众多任务和应用中展现了卓越的能力。然而,使用高质量数据集在外部监督下微调LLM的成本仍然非常高昂。为了解决这个问题,LLM自提升方法最近得到了蓬勃发展。LLM自提升的典型范例包括在自我生成的数据上训练LLM,其中部分数据可能是有害的,由于数据质量不稳定,应该被过滤掉。虽然目前的工作主要采用基于答案正确性的过滤策略,但在本文中,我们证明了过滤掉正确但具有高分布偏移程度(DSE)的样本也有利于自提升的结果。鉴于实际样本分布通常无法访问,我们受到重要性权重方法的启发,提出了一种名为DS权重的的新指标来近似DSE。因此,我们将DS权重与自洽性相结合,以全面过滤自我生成的样本并微调语言模型。实验表明,仅使用一个很小的有效集(最多为训练集的5%大小)来计算DS权重,我们的方法可以显着提高当前LLM自提升方法的推理能力。由此产生的性能与依赖于来自预训练奖励模型的外部监督的方法相当。
🔬 方法详解
问题定义:现有的大语言模型自提升方法,在利用模型自身生成的数据进行训练时,通常会遇到数据质量不稳定的问题。虽然可以通过过滤掉错误答案来提高数据质量,但即使是正确的答案,如果其分布与真实数据分布存在较大偏差(高分布偏移),仍然会对模型的训练产生负面影响。因此,如何有效地识别并过滤掉这些高分布偏移的样本,是当前LLM自提升方法面临的一个重要挑战。
核心思路:论文的核心思路是借鉴重要性权重(Importance Weighting)的思想,利用少量验证集数据来估计自生成数据样本的分布偏移程度。具体来说,通过计算自生成数据样本在验证集上的重要性权重,来近似其分布偏移程度。然后,结合自洽性(Self-Consistency)方法,综合考虑答案的正确性和分布偏移程度,对自生成的数据进行过滤。
技术框架:该方法主要包含以下几个阶段:1) 使用LLM生成数据;2) 使用少量验证集计算生成数据的DS权重,DS权重用于近似分布偏移程度;3) 结合DS权重和自洽性,对生成的数据进行过滤;4) 使用过滤后的数据微调LLM。整体流程旨在提高自生成数据的质量,从而提升LLM的自提升效果。
关键创新:该论文的关键创新在于提出了DS权重这一概念,并将其应用于LLM自提升的数据过滤过程中。与以往仅关注答案正确性的过滤方法不同,该方法同时考虑了答案的分布偏移程度,从而能够更有效地识别并过滤掉对模型训练有害的样本。此外,该方法仅需要少量验证集数据即可计算DS权重,降低了对外部资源的依赖。
关键设计:DS权重的计算是该方法的一个关键设计。具体来说,对于每个自生成的数据样本,首先计算其在验证集上的概率密度,然后将其与验证集整体的概率密度进行比较,得到该样本的重要性权重。重要性权重越大,表示该样本的分布偏移程度越高。在数据过滤阶段,将DS权重与自洽性得分相结合,设定一个阈值,过滤掉DS权重较高且自洽性得分较低的样本。
🖼️ 关键图片


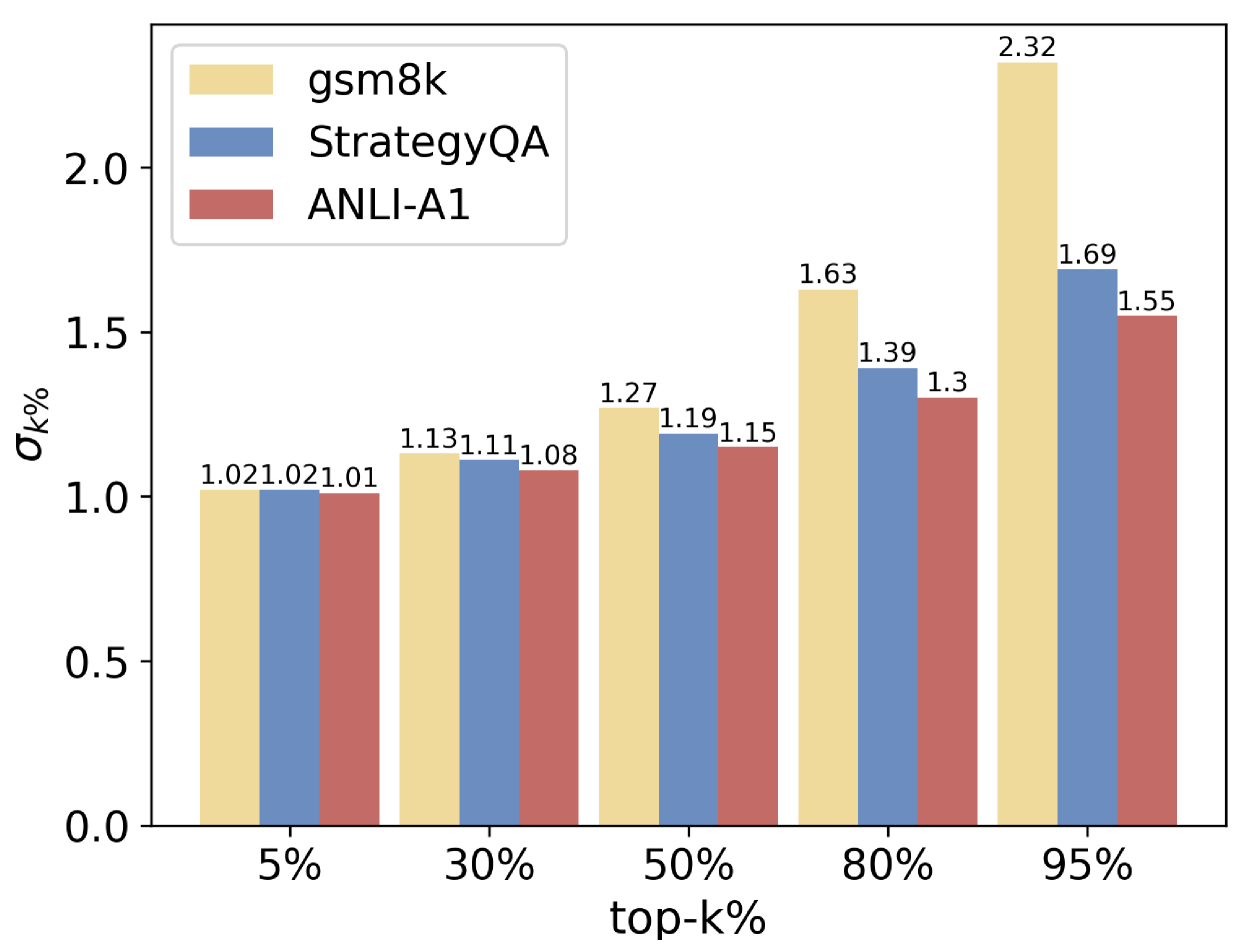
📊 实验亮点
实验结果表明,该方法仅使用训练集5%大小的验证集计算DS权重,即可显著提升LLM的推理能力,性能与依赖外部监督的方法相当。该方法在多个基准测试上均取得了显著的提升,证明了其有效性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要利用LLM自生成数据进行模型优化的场景,例如:问答系统、文本摘要、代码生成等。通过有效过滤自生成数据中的噪声,提高模型训练效率和性能,降低对高质量标注数据的依赖,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable capability in numerous tasks and applications. However, fine-tuning LLMs using high-quality datasets under external supervision remains prohibitively expensive. In response, LLM self-improvement approaches have been vibrantly developed recently. The typical paradigm of LLM self-improvement involves training LLM on self-generated data, part of which may be detrimental and should be filtered out due to the unstable data quality. While current works primarily employs filtering strategies based on answer correctness, in this paper, we demonstrate that filtering out correct but with high distribution shift extent (DSE) samples could also benefit the results of self-improvement. Given that the actual sample distribution is usually inaccessible, we propose a new metric called DS weight to approximate DSE, inspired by the Importance Weighting methods. Consequently, we integrate DS weight with self-consistency to comprehensively filter the self-generated samples and fine-tune the language model. Experiments show that with only a tiny valid set (up to 5\% size of the training set) to compute DS weight, our approach can notably promote the reasoning ability of current LLM self-improvement methods. The resulting performance is on par with methods that rely on external supervision from pre-trained reward models.