Continual Dialogue State Tracking via Reason-of-Select Distillation
作者: Yujie Feng, Bo Liu, Xiaoyu Dong, Zexin Lu, Li-Ming Zhan, Albert Y. S. Lam, Xiao-Ming Wu
分类: cs.CL
发布日期: 2024-08-19 (更新: 2024-10-16)
备注: Accepted to ACL 2024 Findings
💡 一句话要点
提出基于选择理由蒸馏的持续对话状态跟踪方法,解决灾难性遗忘和值选择难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对话状态跟踪 持续学习 知识蒸馏 元推理 灾难性遗忘 值选择难题 多领域对话
📋 核心要点
- 现有对话状态跟踪方法在持续学习新任务时,面临灾难性遗忘和“值选择难题”,即难以从多个候选中选择正确的值。
- 论文提出“选择理由(RoS)蒸馏”方法,通过元推理能力增强小模型,利用领域知识片段缓解遗忘,并提升多值选择能力。
- 实验结果表明,该方法具有卓越的性能和泛化能力,能够有效应对持续学习中的挑战,并提供了可复现的源代码。
📝 摘要(中文)
理想的对话系统需要持续的技能获取和适应新任务,同时保留先前的知识。对话状态跟踪(DST)在这些系统中至关重要,它通常涉及学习新的服务并面临灾难性遗忘,以及被称为“值选择难题”的关键能力损失。为了应对这些挑战,我们引入了选择理由(RoS)蒸馏方法,通过一种新颖的“元推理”能力来增强较小的模型。元推理采用增强的多领域视角,在持续学习期间结合来自领域特定对话的元知识片段。这超越了传统的单视角推理。领域引导过程增强了模型从多个可能的值中剖析复杂对话的能力。其领域无关的特性使不同领域的数据分布对齐,有效缓解了遗忘。此外,两项新的改进,“多值解析”策略和语义对比推理选择方法,通过生成特定于DST的选择链并减轻教师推理中的幻觉,显著增强了RoS,确保了有效和可靠的知识转移。广泛的实验验证了我们方法的卓越性能和强大的泛化能力。提供了源代码以供重现。
🔬 方法详解
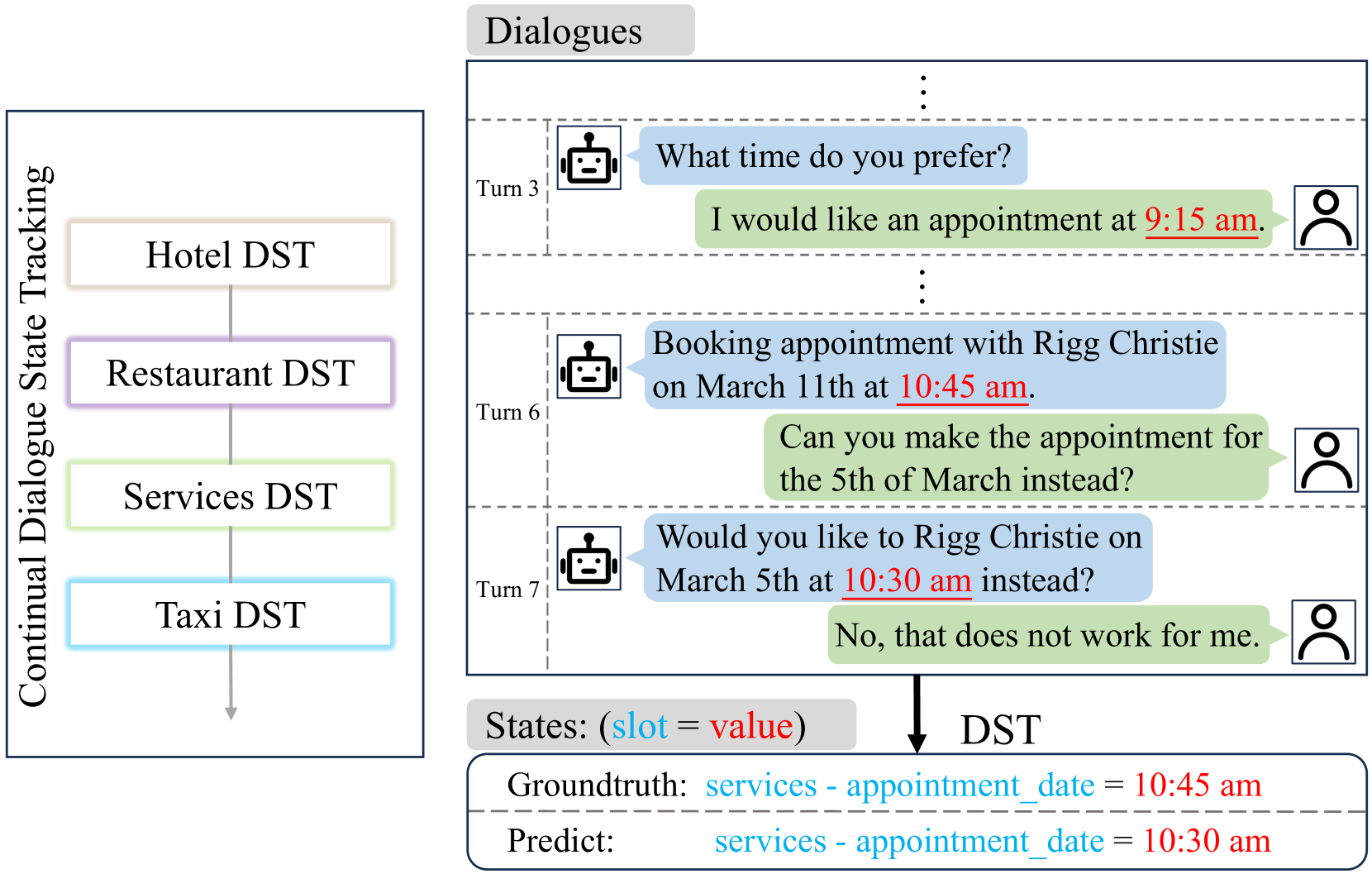
问题定义:对话状态跟踪(DST)旨在跟踪用户在对话过程中的意图,是对话系统中的关键环节。在持续学习场景下,DST模型需要不断学习新的服务和领域,但容易发生灾难性遗忘,即忘记之前学习的知识。此外,模型还面临“值选择难题”,即在多个候选值中选择正确的对话状态。
核心思路:论文的核心思路是利用知识蒸馏,将一个预训练好的教师模型(teacher model)的知识迁移到一个更小的学生模型(student model)上。特别地,论文提出了“选择理由(RoS)蒸馏”方法,通过让学生模型学习教师模型选择对话状态的理由,从而提高学生模型的性能和泛化能力。这种方法旨在缓解灾难性遗忘,并解决值选择难题。
技术框架:整体框架包含一个教师模型和一个学生模型。教师模型是一个预训练好的、能力较强的DST模型。学生模型是一个较小的模型,需要通过知识蒸馏来学习教师模型的知识。RoS蒸馏过程包括以下几个阶段:1)领域引导:利用领域知识片段来增强模型的多领域视角;2)多值解析:设计策略来处理多个候选值;3)语义对比推理选择:减轻教师模型推理中的幻觉,确保知识转移的有效性。
关键创新:论文的关键创新在于提出了“选择理由(RoS)蒸馏”方法,并引入了“元推理”能力。传统的知识蒸馏方法通常只关注输出结果的匹配,而RoS蒸馏则关注教师模型选择结果的理由,从而使学生模型能够更好地理解对话状态的内在逻辑。此外,论文还提出了“多值解析”策略和“语义对比推理选择”方法,进一步提高了RoS蒸馏的性能。
关键设计:在“多值解析”策略中,论文设计了一种方法来处理多个候选值,例如,可以采用排序或分类的方式来选择最合适的对话状态。在“语义对比推理选择”方法中,论文设计了一种损失函数,用于衡量教师模型推理的合理性,并减轻教师模型推理中的幻觉。具体的参数设置和网络结构在论文中有详细描述,源代码也已公开。
🖼️ 关键图片
📊 实验亮点
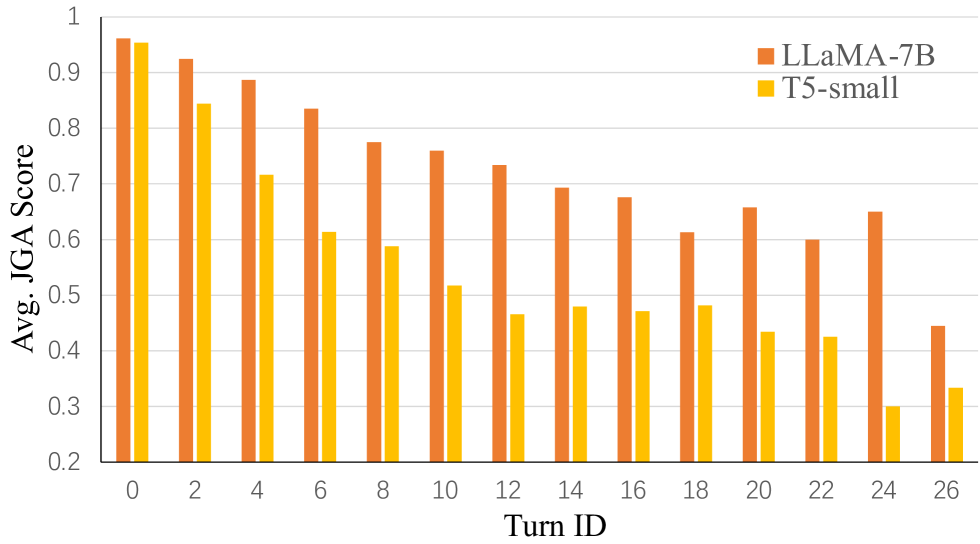
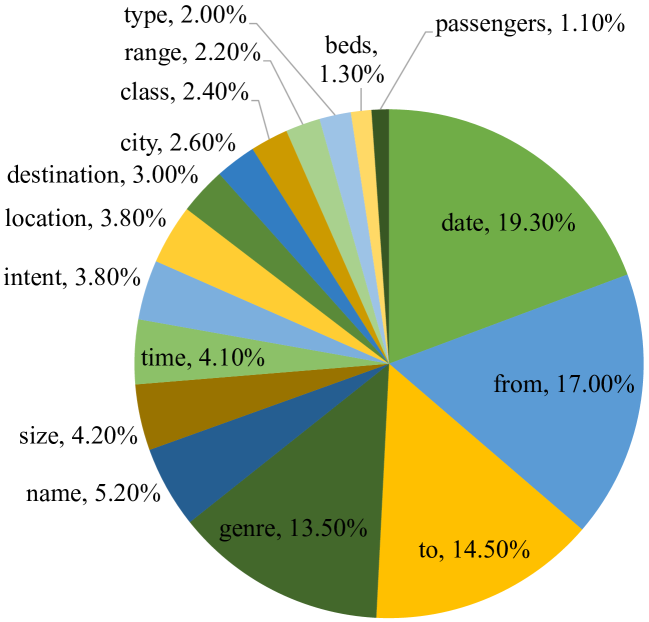
实验结果表明,提出的RoS蒸馏方法在持续对话状态跟踪任务上取得了显著的性能提升。与现有的知识蒸馏方法相比,RoS蒸馏能够更好地缓解灾难性遗忘,并解决值选择难题。具体的性能数据和对比基线在论文中有详细描述,实验结果验证了该方法的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于各种对话系统,例如智能客服、虚拟助手等。通过持续学习新的服务和领域,对话系统可以不断提升其智能化水平,更好地满足用户的需求。该方法尤其适用于需要处理多领域对话的场景,例如旅游咨询、医疗问诊等。未来的研究方向包括探索更有效的知识蒸馏方法,以及将该方法应用于其他自然语言处理任务。
📄 摘要(原文)
An ideal dialogue system requires continuous skill acquisition and adaptation to new tasks while retaining prior knowledge. Dialogue State Tracking (DST), vital in these systems, often involves learning new services and confronting catastrophic forgetting, along with a critical capability loss termed the "Value Selection Quandary." To address these challenges, we introduce the Reason-of-Select (RoS) distillation method by enhancing smaller models with a novel 'meta-reasoning' capability. Meta-reasoning employs an enhanced multi-domain perspective, combining fragments of meta-knowledge from domain-specific dialogues during continual learning. This transcends traditional single-perspective reasoning. The domain bootstrapping process enhances the model's ability to dissect intricate dialogues from multiple possible values. Its domain-agnostic property aligns data distribution across different domains, effectively mitigating forgetting. Additionally, two novel improvements, "multi-value resolution" strategy and Semantic Contrastive Reasoning Selection method, significantly enhance RoS by generating DST-specific selection chains and mitigating hallucinations in teachers' reasoning, ensuring effective and reliable knowledge transfer. Extensive experiments validate the exceptional performance and robust generalization capabilities of our method. The source code is provided for reproducibility.