How to Make the Most of LLMs' Grammatical Knowledge for Acceptability Judgments
作者: Yusuke Ide, Yuto Nishida, Justin Vasselli, Miyu Oba, Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
分类: cs.CL, cs.AI
发布日期: 2024-08-19 (更新: 2025-02-07)
备注: NAACL 2025 main
💡 一句话要点
利用提示工程提升大型语言模型在可接受性判断任务中的语法知识评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语法知识评估 可接受性判断 提示工程 语言学最小对
📋 核心要点
- 现有方法直接比较LLMs的句子概率来评估语法知识,但LLMs的原始概率可能无法充分反映其语法能力。
- 论文提出利用提示和模板,从LLMs中导出更准确的可接受性判断,从而更有效地评估其语法知识。
- 实验表明,模板内语言模型概率读取和基于提示的Yes/No概率计算方法优于传统方法,且集成两种方法效果更佳。
📝 摘要(中文)
本文旨在提升大型语言模型(LLMs)在可接受性判断任务中的表现,该任务通常使用语言学最小对来评估模型的语法知识。传统方法直接比较LLMs分配的句子概率,但由于LLMs通过提示进行任务训练,原始概率可能无法完全反映其语法知识。本研究尝试通过提示和模板从LLMs中获得更准确的可接受性判断。通过在英语和汉语上的大量实验,比较了九种判断方法,发现其中两种方法——模板内语言模型概率读取(in-template LP)和基于提示的Yes/No概率计算——比传统方法实现了更高的准确率。分析表明,这些方法擅长不同的语言现象,表明它们访问了LLMs知识的不同方面。此外,两种方法的集成优于单一方法。因此,我们推荐这些技术,无论是单独使用还是集成使用,作为评估LLMs语法知识的更有效替代方案。
🔬 方法详解
问题定义:论文旨在解决如何更准确地评估大型语言模型(LLMs)的语法知识的问题。现有方法,即直接比较LLMs给出的句子概率,存在局限性,因为LLMs通常通过提示进行训练,其原始概率可能受到任务形式的影响,无法真实反映其内在的语法能力。因此,需要一种更有效的方法来提取LLMs中蕴含的语法知识,并进行准确的评估。
核心思路:论文的核心思路是利用提示工程(Prompt Engineering)来引导LLMs,使其更明确地表达其语法判断。通过设计不同的提示和模板,引导LLMs以更结构化的方式输出信息,从而更好地提取和利用其语法知识。具体而言,论文探索了多种基于提示的方法,旨在克服直接比较句子概率的局限性,并挖掘LLMs更深层的语法理解能力。
技术框架:论文的技术框架主要包括以下几个步骤:1) 构建语言学最小对数据集,包含可接受和不可接受的句子对;2) 设计不同的提示和模板,用于引导LLMs进行可接受性判断;3) 使用不同的判断方法,包括传统的概率比较方法以及基于提示的新方法,对LLMs的输出进行处理;4) 在英语和汉语数据集上进行实验,比较不同方法的准确率;5) 分析不同方法在不同语言现象上的表现,并探讨其原因;6) 探索集成不同方法的策略,以进一步提高准确率。
关键创新:论文的关键创新在于提出了两种新的基于提示的方法:模板内语言模型概率读取(in-template LP)和基于提示的Yes/No概率计算。这两种方法通过不同的方式利用提示工程,更有效地提取了LLMs的语法知识。与传统方法相比,它们能够更好地适应LLMs的训练方式,并减少任务形式对结果的影响。此外,论文还发现这两种方法擅长不同的语言现象,表明它们访问了LLMs知识的不同方面,为进一步理解LLMs的语法能力提供了新的视角。
关键设计:在模板内语言模型概率读取方法中,关键在于设计合适的模板,使得LLMs能够更自然地输出句子概率。例如,可以使用类似“The probability of this sentence is [MASK]”的模板,然后利用LLMs预测[MASK]位置的概率。在基于提示的Yes/No概率计算方法中,关键在于设计明确的Yes/No问题,并计算LLMs回答Yes和No的概率。例如,可以使用类似“Is this sentence grammatically correct? (Yes/No)”的提示,然后比较LLMs回答Yes和No的概率。此外,论文还探索了集成两种方法的策略,例如简单平均或加权平均,以进一步提高准确率。具体参数设置和损失函数未知。
🖼️ 关键图片

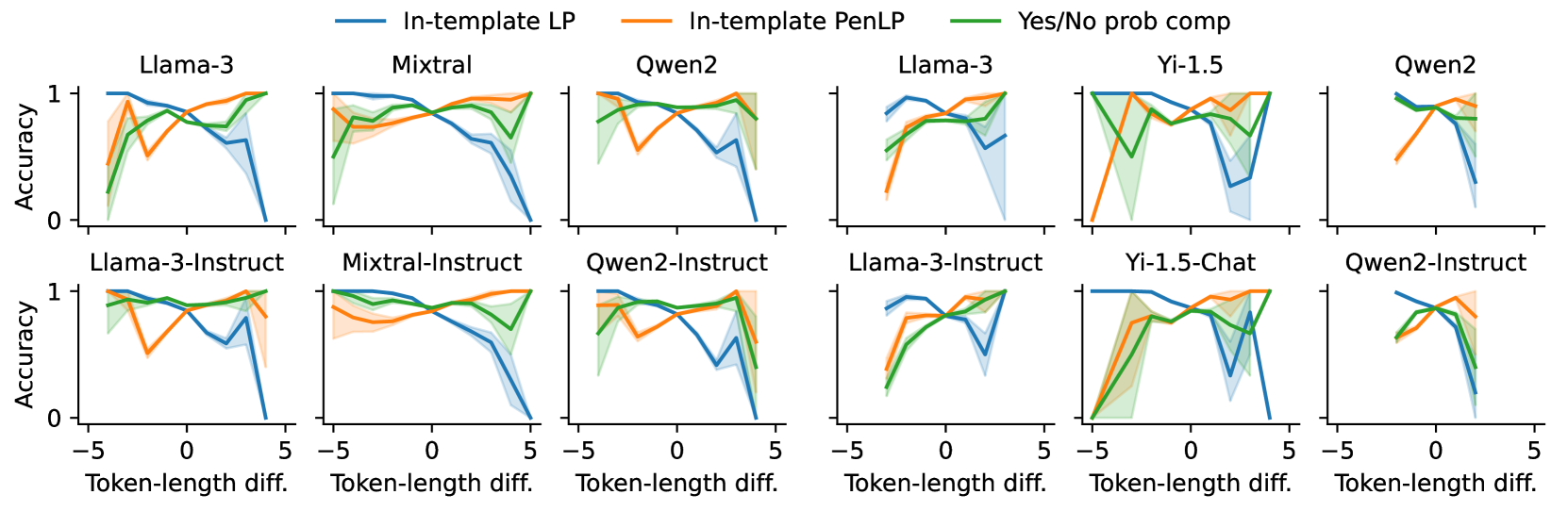

📊 实验亮点
实验结果表明,模板内语言模型概率读取和基于提示的Yes/No概率计算方法在英语和汉语数据集上均优于传统的概率比较方法。具体而言,这两种方法在某些语言现象上表现出显著的优势,并且通过集成两种方法可以进一步提高准确率。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于提升自然语言处理系统的语法纠错能力,例如在机器翻译、文本生成和语法检查等领域。更准确的语法知识评估方法有助于更好地理解和利用大型语言模型的语言能力,从而开发更智能、更可靠的自然语言处理应用。此外,该研究也为未来设计更有效的提示工程方法提供了借鉴。
📄 摘要(原文)
The grammatical knowledge of language models (LMs) is often measured using a benchmark of linguistic minimal pairs, where the LMs are presented with a pair of acceptable and unacceptable sentences and required to judge which is more acceptable. Conventional approaches directly compare sentence probabilities assigned by LMs, but recent large language models (LLMs) are trained to perform tasks via prompting, and thus, the raw probabilities they assign may not fully reflect their grammatical knowledge. In this study, we attempt to derive more accurate acceptability judgments from LLMs using prompts and templates. Through extensive experiments in English and Chinese, we compare nine judgment methods and find two of them, a probability readout method -- in-template LP and a prompt-based method -- Yes/No probability computing, achieve higher accuracy than the conventional ones. Our analysis reveals that these methods excel in different linguistic phenomena, suggesting they access different aspects of LLMs' knowledge. We also find that ensembling the two methods outperforms single methods. Consequently, we recommend these techniques, either individually or ensembled, as more effective alternatives to conventional approaches for assessing grammatical knowledge in LLMs.