Crossing New Frontiers: Knowledge-Augmented Large Language Model Prompting for Zero-Shot Text-Based De Novo Molecule Design
作者: Sakhinana Sagar Srinivas, Venkataramana Runkana
分类: cs.CL, cs.AI, cs.LG, q-bio.BM
发布日期: 2024-08-18
备注: Paper was accepted at R0-FoMo: Robustness of Few-shot and Zero-shot Learning in Foundation Models, NeurIPS-2023. Please find the links: https://sites.google.com/view/r0-fomo/accepted-papers?authuser=0 and https://neurips.cc/virtual/2023/workshop/66517
💡 一句话要点
提出知识增强的大语言模型提示方法,用于零样本文本驱动的分子设计。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分子设计 大语言模型 提示工程 零样本学习 知识增强 文本生成 药物发现
📋 核心要点
- 现有分子设计方法依赖大量计算和实验,耗时耗力,文本驱动的分子设计面临分布偏移的挑战。
- 论文提出知识增强的LLM提示方法,通过任务特定指令和少量演示,引导LLM生成符合文本描述的分子。
- 实验结果表明,该框架在基准数据集上优于当前最先进的分子设计模型,验证了方法的有效性。
📝 摘要(中文)
分子设计是一个多方面的方法,它利用计算方法和实验来优化分子性质,从而加速新药发现、创新材料开发和更高效的化学过程。最近,受类似于基础视觉-语言模型的下一代人工智能任务的启发,出现了基于文本的分子设计。本研究探索了使用知识增强的大语言模型(LLM)提示方法,用于零样本文本条件下的从头分子生成任务。我们的方法使用特定于任务的指令和一些演示,以解决在构建增强提示以查询LLM生成与技术描述一致的分子时遇到的分布偏移挑战。我们的框架被证明是有效的,在基准数据集上优于最先进(SOTA)的基线模型。
🔬 方法详解
问题定义:论文旨在解决零样本文本驱动的从头分子设计问题。现有方法,尤其是直接使用大型语言模型的方法,在处理技术描述等专业文本时,由于数据分布的差异,难以生成符合要求的分子结构。这种分布偏移导致生成分子的性质与目标描述不一致,限制了其在实际应用中的价值。
核心思路:论文的核心思路是利用知识增强的提示工程来引导大型语言模型。通过精心设计的任务特定指令和少量示例演示,让LLM更好地理解分子设计的任务目标和约束条件。这种方法旨在缩小LLM预训练数据与分子设计任务之间的差距,从而提高生成分子的质量和相关性。
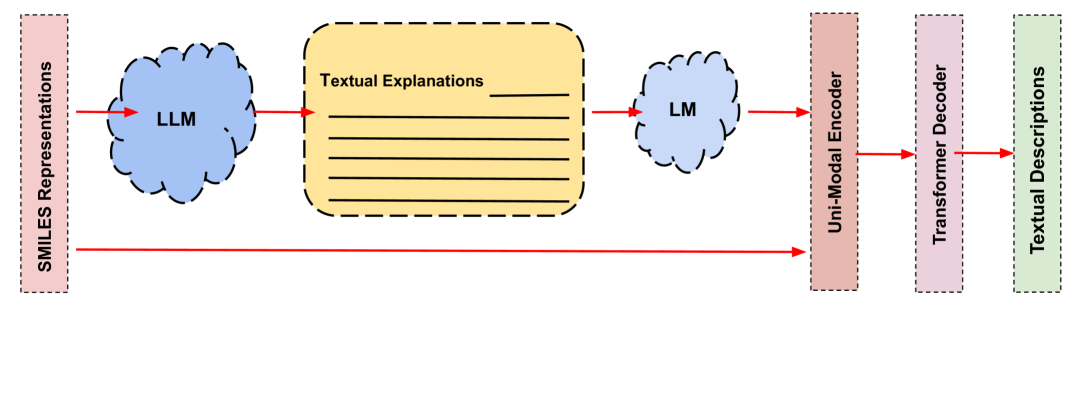
技术框架:该框架主要包含以下几个阶段:1) 任务定义:明确分子设计的具体目标,例如生成具有特定性质的分子。2) 提示构建:设计包含任务指令和少量示例的提示,用于引导LLM生成分子。3) LLM推理:将构建好的提示输入LLM,生成候选分子结构。4) 分子验证与评估:对生成的分子进行验证,评估其性质是否符合目标要求。
关键创新:该方法最重要的创新在于知识增强的提示工程。与直接使用LLM进行分子设计不同,该方法通过任务特定指令和少量示例,将分子设计领域的知识融入到LLM的推理过程中。这种方法能够有效缓解分布偏移问题,提高生成分子的质量和相关性。
关键设计:关键设计包括:1) 任务特定指令的设计,需要清晰地描述分子设计的具体目标和约束条件。2) 少量示例的选择,需要选择具有代表性的示例,帮助LLM理解分子设计的任务。3) LLM的选择,可以选择具有较强文本生成能力的LLM,例如GPT-3或LaMDA。4) 分子验证与评估方法,需要选择合适的分子性质预测模型,评估生成分子的质量。
🖼️ 关键图片

📊 实验亮点
该研究在零样本文本驱动的分子设计任务上取得了显著进展,提出的知识增强提示方法优于当前最先进的基线模型。实验结果表明,该方法能够有效缓解分布偏移问题,提高生成分子的质量和相关性,为分子设计领域提供了一种新的思路。
🎯 应用场景
该研究成果可应用于药物发现、材料科学和化学工程等领域。通过文本描述即可快速生成具有特定性质的分子,加速新药研发和新材料设计过程,降低研发成本,提高研发效率。未来可进一步扩展到其他领域,例如蛋白质设计和基因工程。
📄 摘要(原文)
Molecule design is a multifaceted approach that leverages computational methods and experiments to optimize molecular properties, fast-tracking new drug discoveries, innovative material development, and more efficient chemical processes. Recently, text-based molecule design has emerged, inspired by next-generation AI tasks analogous to foundational vision-language models. Our study explores the use of knowledge-augmented prompting of large language models (LLMs) for the zero-shot text-conditional de novo molecular generation task. Our approach uses task-specific instructions and a few demonstrations to address distributional shift challenges when constructing augmented prompts for querying LLMs to generate molecules consistent with technical descriptions. Our framework proves effective, outperforming state-of-the-art (SOTA) baseline models on benchmark datasets.