Reward Difference Optimization For Sample Reweighting In Offline RLHF
作者: Shiqi Wang, Zhengze Zhang, Rui Zhao, Fei Tan, Cam Tu Nguyen
分类: cs.CL, cs.AI
发布日期: 2024-08-18 (更新: 2024-10-30)
备注: EMNLP 2024 findings
💡 一句话要点
提出奖励差异优化RDO,提升离线RLHF中LLM对人类偏好的对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线RLHF 人类偏好对齐 奖励差异优化 大型语言模型 排序学习
📋 核心要点
- 现有离线RLHF方法仅关注响应的序数关系,忽略了偏好程度的差异,导致优化不充分。
- 提出奖励差异优化(RDO)方法,通过奖励差异系数重新加权样本对,更精确地建模人类偏好。
- 实验结果表明,RDO在自动指标和人工评估中均优于现有方法,有效提升了LLM对人类偏好的对齐。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,将LLMs与人类偏好对齐变得越来越重要。虽然基于人类反馈的强化学习(RLHF)已被证明是有效的,但它既复杂又耗费大量资源。因此,离线RLHF作为一种替代解决方案被引入,它直接利用固定的偏好数据集上的排序损失来优化LLMs。当前的离线RLHF只捕捉到响应之间的“序数关系”,忽略了一个关键方面,即一个响应比另一个响应更受偏好的程度。为了解决这个问题,我们提出了一种简单而有效的解决方案,称为奖励差异优化(Reward Difference Optimization),简称RDO。具体来说,我们引入奖励差异系数来重新加权离线RLHF中的样本对。然后,我们开发了一个差异模型,该模型捕获一对响应之间丰富的交互,用于预测这些差异系数。在HH和TL;DR数据集上使用7B LLMs进行的实验证实了我们的方法在自动指标和人工评估中的有效性,从而突出了其在将LLMs与人类意图和价值观对齐方面的潜力。
🔬 方法详解
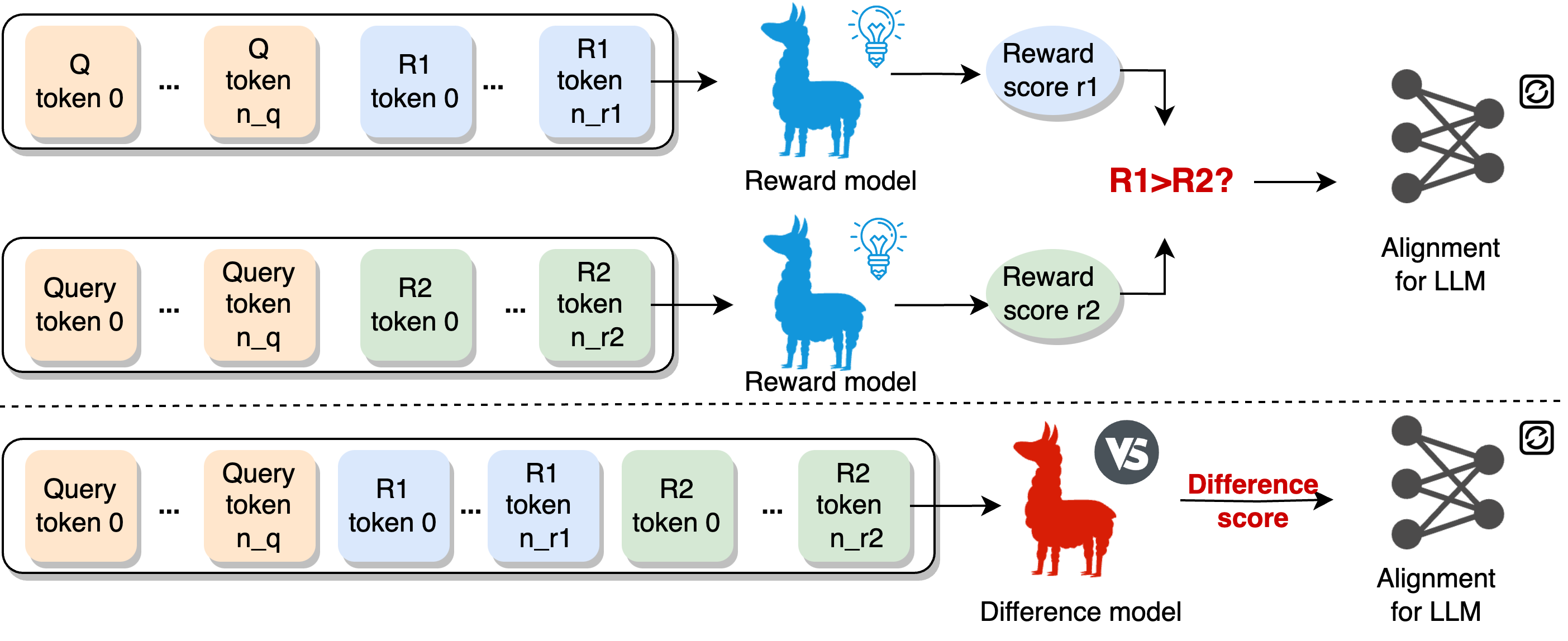
问题定义:现有的离线RLHF方法主要依赖于排序损失,仅关注不同回复之间的相对排序关系,而忽略了人类对不同回复偏好程度的差异。例如,两个回复的排序相同,但人类可能对其中一个回复的偏好程度远高于另一个,这种偏好程度的差异信息在现有方法中被忽略,导致模型无法充分学习人类的偏好。
核心思路:RDO的核心思路是引入奖励差异系数,用于重新加权离线RLHF中的样本对。该系数反映了人类对不同回复偏好程度的差异。通过差异模型预测这些系数,并将其用于调整损失函数中不同样本对的权重,从而使模型更加关注那些人类偏好程度差异较大的样本对,更有效地学习人类偏好。
技术框架:RDO方法主要包含两个模块:奖励差异系数预测模块和加权损失优化模块。奖励差异系数预测模块使用一个差异模型,该模型以一对回复作为输入,预测它们之间的奖励差异系数。加权损失优化模块使用预测的奖励差异系数来重新加权排序损失函数中的样本对,然后使用梯度下降等优化算法来更新LLM的参数。
关键创新:RDO的关键创新在于引入了奖励差异系数来建模人类偏好程度的差异。与传统的离线RLHF方法相比,RDO不仅关注回复之间的相对排序关系,还关注人类对不同回复偏好程度的差异,从而更精确地建模人类偏好。此外,差异模型的引入使得RDO能够自动学习奖励差异系数,无需人工标注。
关键设计:差异模型可以使用各种神经网络结构,例如Transformer或MLP。模型的输入是一对回复,输出是它们之间的奖励差异系数。损失函数可以使用排序损失或回归损失,目标是使模型预测的奖励差异系数与人类的偏好程度一致。奖励差异系数可以用于调整排序损失函数中不同样本对的权重,例如,对于奖励差异系数较大的样本对,可以赋予更高的权重。
🖼️ 关键图片

📊 实验亮点
在HH和TL;DR数据集上,使用7B LLM进行的实验表明,RDO在自动指标和人工评估中均优于现有方法。具体来说,RDO在HH数据集上的胜率比基线方法提高了显著百分比(具体数值未知),并且在TL;DR数据集上也取得了类似的提升。这些结果表明,RDO能够更有效地将LLM与人类偏好对齐。
🎯 应用场景
RDO方法可广泛应用于各种需要将LLM与人类偏好对齐的场景,例如对话系统、文本摘要、代码生成等。通过更精确地建模人类偏好,RDO可以帮助LLM生成更符合人类意图和价值观的回复,从而提高用户满意度和使用体验。该方法尤其适用于离线RLHF场景,可以有效利用已有的偏好数据集,降低训练成本。
📄 摘要(原文)
With the rapid advances in Large Language Models (LLMs), aligning LLMs with human preferences become increasingly important. Although Reinforcement Learning with Human Feedback (RLHF) proves effective, it is complicated and highly resource-intensive. As such, offline RLHF has been introduced as an alternative solution, which directly optimizes LLMs with ranking losses on a fixed preference dataset. Current offline RLHF only captures the "ordinal relationship" between responses, overlooking the crucial aspect of how much one is preferred over the others. To address this issue, we propose a simple yet effective solution called Reward Difference Optimization, shorted as RDO. Specifically, we introduce reward difference coefficients to reweigh sample pairs in offline RLHF. We then develop a difference model which captures rich interactions between a pair of responses for predicting these difference coefficients. Experiments with 7B LLMs on the HH and TL;DR datasets substantiate the effectiveness of our method in both automatic metrics and human evaluation, thereby highlighting its potential for aligning LLMs with human intent and values