FLEXTAF: Enhancing Table Reasoning with Flexible Tabular Formats
作者: Xuanliang Zhang, Dingzirui Wang, Longxu Dou, Baoxin Wang, Dayong Wu, Qingfu Zhu, Wanxiang Che
分类: cs.CL
发布日期: 2024-08-16 (更新: 2024-08-27)
💡 一句话要点
FLEXTAF:通过灵活表格格式增强表格推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格推理 大型语言模型 灵活表格格式 WikiTableQuestions TabFact
📋 核心要点
- 现有表格推理方法采用固定表格格式,忽略了实例和模型间的差异性,限制了性能。
- FLEXTAF通过训练分类器预测最佳表格格式(FLEXTAF-Single)或整合不同格式结果(FLEXTAF-Vote)来提升性能。
- 在WikiTableQuestions和TabFact数据集上,FLEXTAF相比固定格式方法,平均提升了2.3%和4.8%。
📝 摘要(中文)
表格推理任务旨在根据给定的表格回答问题。目前,使用大型语言模型(LLMs)是表格推理的主要方法。大多数现有方法采用固定的表格格式来表示表格,这可能会限制性能。鉴于每个实例都需要不同的能力,并且模型具有不同的能力,我们认为不同的实例和模型适合不同的表格格式。我们通过对实验结果的定量分析证明了上述观点,其中不同的实例和模型在使用不同的表格格式时实现了不同的性能。在此基础上,我们提出了FLEXTAF-Single和FLEXTAF-Vote,通过采用灵活的表格格式来提高表格推理性能。具体来说,(i) FLEXTAF-Single训练一个分类器来预测基于实例和LLM的最合适的表格格式。(ii) FLEXTAF-Vote整合了不同格式的结果。我们在WikiTableQuestions和TabFact上的实验显示出显著的改进,与使用贪婪解码和自洽解码的固定表格格式所能达到的最佳性能相比,平均增益分别为2.3%和4.8%,从而验证了我们方法的有效性。
🔬 方法详解
问题定义:现有表格推理方法通常采用固定的表格格式,没有考虑到不同实例和不同模型之间存在差异,导致模型无法充分利用表格信息,限制了表格推理的性能。因此,如何根据实例和模型选择合适的表格格式是一个关键问题。
核心思路:论文的核心思路是采用灵活的表格格式,即针对不同的实例和模型,选择最合适的表格格式进行推理。作者认为,不同的实例可能需要不同的表格格式才能更好地表达其内在信息,而不同的模型也可能更擅长处理特定格式的表格。
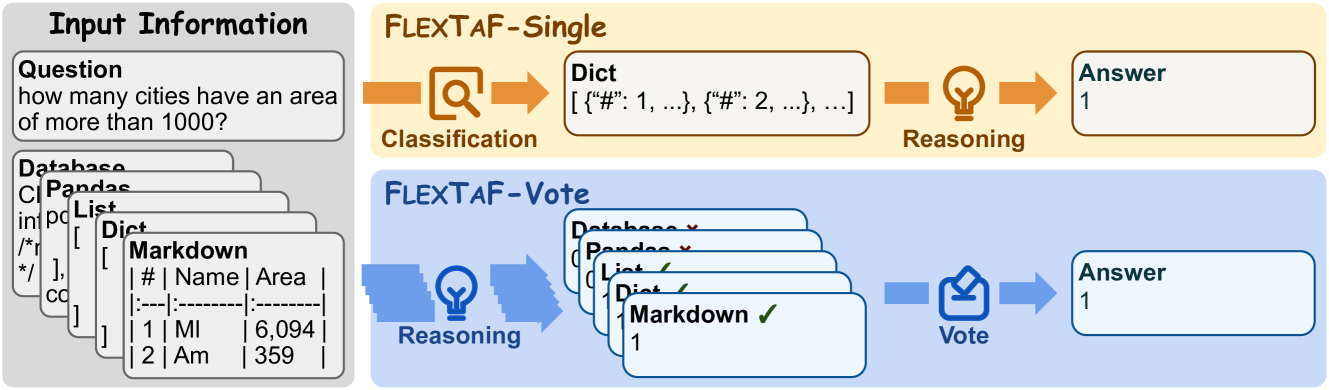
技术框架:FLEXTAF包含两种方法:FLEXTAF-Single和FLEXTAF-Vote。FLEXTAF-Single首先训练一个分类器,该分类器以实例和LLM为输入,预测最合适的表格格式。然后,使用预测的表格格式进行推理。FLEXTAF-Vote则使用多种表格格式进行推理,然后整合不同格式的推理结果。
关键创新:该论文的关键创新在于提出了灵活表格格式的思想,并将其应用于表格推理任务中。与现有方法相比,FLEXTAF能够根据实例和模型自适应地选择表格格式,从而更好地利用表格信息,提高推理性能。
关键设计:FLEXTAF-Single的关键设计在于表格格式分类器的训练。分类器的输入包括实例特征和模型信息,输出是表格格式的类别。具体实现细节(如特征提取方式、分类器类型等)在论文中可能没有详细说明,属于未知信息。FLEXTAF-Vote的关键设计在于如何整合不同格式的推理结果,具体整合方法(如投票、加权平均等)在论文中可能也没有详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FLEXTAF在WikiTableQuestions和TabFact数据集上取得了显著的提升。与使用固定表格格式的最佳性能相比,FLEXTAF-Single和FLEXTAF-Vote分别实现了平均2.3%和4.8%的性能提升,验证了灵活表格格式的有效性。
🎯 应用场景
该研究成果可应用于智能问答系统、数据分析、知识图谱构建等领域。通过灵活选择表格格式,可以提升模型对表格数据的理解和推理能力,从而提高相关应用的性能和用户体验。未来,该方法可以扩展到其他结构化数据推理任务中。
📄 摘要(原文)
The table reasoning task aims to answer the question according to the given table. Currently, using Large Language Models (LLMs) is the predominant method for table reasoning. Most existing methods employ a fixed tabular format to represent the table, which could limit the performance. Given that each instance requires different capabilities and models possess varying abilities, we assert that different instances and models suit different tabular formats. We prove the aforementioned claim through quantitative analysis of experimental results, where different instances and models achieve different performances using various tabular formats. Building on this discussion, we propose FLEXTAF-Single and FLEXTAF-Vote to enhance table reasoning performance by employing flexible tabular formats. Specifically, (i) FLEXTAF-Single trains a classifier to predict the most suitable tabular format based on the instance and the LLM. (ii) FLEXTAF-Vote integrates the results across different formats. Our experiments on WikiTableQuestions and TabFact reveal significant improvements, with average gains of 2.3% and 4.8% compared to the best performance achieved using a fixed tabular format with greedy decoding and self-consistency decoding, thereby validating the effectiveness of our methods.