Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions
作者: Chenming Tang, Zhixiang Wang, Hao Sun, Yunfang Wu
分类: cs.CL
发布日期: 2024-08-16 (更新: 2025-09-06)
备注: EMNLP 2025 Findings. 23 pages, 23 figures, 7 tables
💡 一句话要点
提出集成提示框架,发现大语言模型对提示描述内容不敏感,提示格式更重要。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 提示工程 集成提示 机器翻译
📋 核心要点
- 现有研究对上下文学习中描述性指令的作用探索不足,难以充分发挥大语言模型的潜力。
- 提出集成提示框架,通过集成多个上下文示例的选择标准,优化提示格式。
- 实验表明,大语言模型对提示格式比描述内容更敏感,集成格式能有效提升性能。
📝 摘要(中文)
借助上下文学习(ICL),大型语言模型(LLM)在各种任务中取得了令人瞩目的性能。然而,描述性指令在ICL中的作用仍未得到充分探索。本文提出了一个集成提示框架,用于描述多个上下文示例的选择标准。在六个翻译方向上的机器翻译(MT)初步实验证实,该框架可以提高ICL性能。但令人惊讶的是,LLM可能并不关心描述的实际内容,性能提升主要由集成格式引起,即使使用随机描述性名词也能带来改进。我们进一步将这种新的集成框架应用于一系列常识、数学、逻辑推理和幻觉任务,并使用三个LLM取得了可喜的成果,再次表明设计合适的提示格式比在特定描述上投入精力更有效。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在上下文学习(ICL)中,描述性指令作用不明确的问题。现有方法往往侧重于优化描述性指令的内容,而忽略了提示格式的重要性。这导致大语言模型无法充分利用上下文信息,影响了其在各种任务中的性能。
核心思路:论文的核心思路是,与其花费大量精力优化描述性指令的具体内容,不如设计一个更有效的提示格式。具体而言,论文提出了一个集成提示框架,通过集成多个上下文示例的选择标准,来引导大语言模型更好地理解和利用上下文信息。
技术框架:该集成提示框架的核心是集成多个上下文示例的描述信息。具体流程如下:首先,为每个上下文示例定义一个描述性指令,用于描述该示例的选择标准。然后,将这些描述性指令集成到一个提示中,作为大语言模型的输入。大语言模型根据这个集成的提示,选择合适的上下文示例,并生成最终的输出。
关键创新:该论文最重要的技术创新点在于,它发现大语言模型对提示格式的敏感度高于提示内容。换句话说,即使使用随机的描述性名词,只要保持集成提示的格式,也能获得性能提升。这与现有方法侧重于优化描述性指令内容的思路截然不同。
关键设计:该论文的关键设计在于集成提示的格式。具体而言,论文采用了以下设计:1) 使用多个描述性指令,每个指令对应一个上下文示例;2) 将这些指令集成到一个提示中,形成一个统一的输入;3) 使用特定的分隔符,将不同的指令分隔开来。这些设计旨在引导大语言模型更好地理解和利用上下文信息。
🖼️ 关键图片
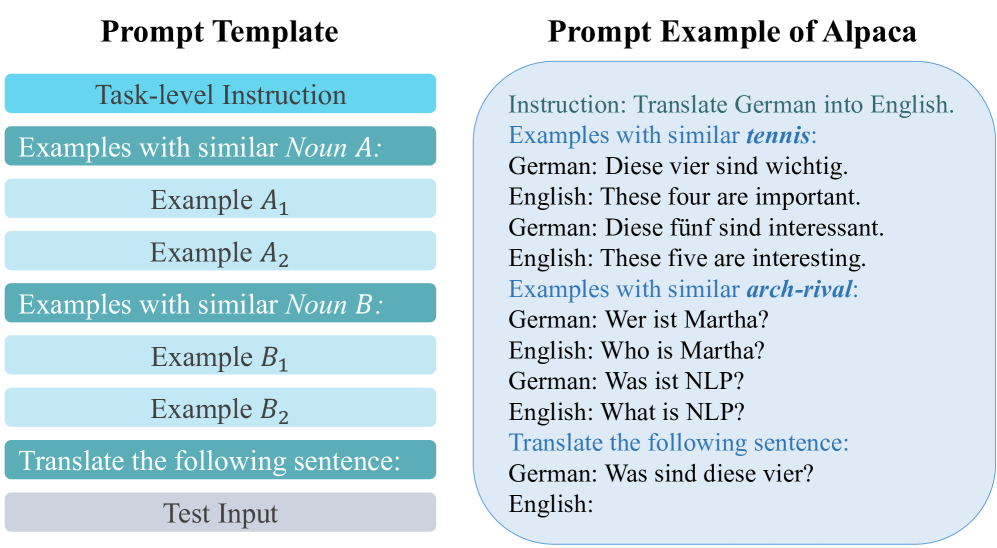


📊 实验亮点
在机器翻译任务中,该集成提示框架在六个翻译方向上均取得了性能提升。更令人惊讶的是,即使使用随机描述性名词,该框架也能带来改进,表明提示格式比描述内容更重要。此外,该框架在常识、数学、逻辑推理和幻觉任务中也取得了可喜的成果,进一步验证了其有效性。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型的场景,例如机器翻译、常识推理、数学问题求解等。通过优化提示格式,可以显著提升大语言模型在这些任务中的性能,降低对特定描述性指令的依赖,从而提高模型的泛化能力和鲁棒性。该研究也为未来提示工程的研究方向提供了新的思路。
📄 摘要(原文)
With the help of in-context learning (ICL), large language models (LLMs) have achieved impressive performance across various tasks. However, the function of descriptive instructions during ICL remains under-explored. In this work, we propose an ensemble prompt framework to describe the selection criteria of multiple in-context examples, and preliminary experiments on machine translation (MT) across six translation directions confirm that this framework boosts ICL performance. But to our surprise, LLMs might not care what the descriptions actually say, and the performance gain is primarily caused by the ensemble format, since it could lead to improvement even with random descriptive nouns. We further apply this new ensemble framework on a range of commonsense, math, logical reasoning and hallucination tasks with three LLMs and achieve promising results, suggesting again that designing a proper prompt format would be much more effective and efficient than paying effort into specific descriptions.