Chain of Thought Still Thinks Fast: APriCoT Helps with Thinking Slow
作者: Kyle Moore, Jesse Roberts, Thao Pham, Douglas Fisher
分类: cs.CL, cs.AI
发布日期: 2024-08-16 (更新: 2025-08-11)
备注: Final version. Published In Proceedings of the Annual Meeting of the Cognitive Science Society (Vol. 47) 2025
💡 一句话要点
提出APriCoT方法,缓解语言模型在MMLU任务中的偏差,提升推理的稳健性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 思维链 反事实提示 偏差缓解 MMLU 不可知先验 推理 公平性
📋 核心要点
- 现有语言模型在MMLU等任务中存在偏差,导致其决策受统计规律影响,而非语义理解。
- APriCoT方法通过不可知先验的CoT反事实提示,旨在减少模型对训练数据偏差的依赖。
- 实验表明,APriCoT能有效降低偏差,提高模型在MMLU任务中的准确率,提升推理稳健性。
📝 摘要(中文)
语言模型容易从训练数据中吸收偏差,导致预测受统计规律而非语义相关性驱动。本文研究了这些偏差对MMLU任务中答案选择偏好的影响。研究发现,即使使用思维链(CoT)推理,这些偏差也能预测模型的偏好,并反映人类的应试策略。为了解决这个问题,本文提出了一种基于不可知先验CoT的反事实提示方法(APriCoT)。实验表明,单独使用基于CoT的反事实提示不足以减轻偏差,而APriCoT能有效降低基础概率的影响,同时提高整体准确率。研究结果表明,减轻偏差需要一个缓慢的思考过程,而CoT本身可能无法提供,因为它倾向于在某些提示方法下加强快速思考模型的偏差。APriCoT是朝着开发更稳健和公平的、能够缓慢思考的语言模型迈出的一步。
🔬 方法详解
问题定义:论文旨在解决语言模型在MMLU(Massive Multi-Task Language Understanding)任务中存在的偏差问题。现有方法,特别是思维链(CoT)推理,虽然能提升性能,但仍然受到训练数据中偏差的影响,导致模型倾向于基于统计规律而非真正的语义理解进行决策。这种偏差会降低模型的泛化能力和公平性。
核心思路:论文的核心思路是通过引入“不可知先验”的CoT提示,并结合反事实提示,来引导模型进行更深入、更缓慢的思考。这种方法旨在减少模型对训练数据中固有偏差的依赖,使其能够基于更可靠的语义信息进行推理。
技术框架:APriCoT方法主要包含以下几个阶段:1) 使用“不可知先验”生成CoT推理过程,即在生成CoT时,避免引入任何可能导致偏差的信息。2) 使用反事实提示,即构造与原始问题相反或不同的情景,迫使模型重新评估其推理过程。3) 将上述两种提示方法结合,形成APriCoT提示,输入到语言模型中进行推理。4) 对模型的输出进行评估,判断其是否受到偏差的影响,并计算准确率。
关键创新:APriCoT的关键创新在于将“不可知先验”的CoT提示与反事实提示相结合。传统的CoT方法可能会强化模型已有的偏差,而APriCoT通过引入“不可知先验”来避免这种情况,并利用反事实提示来迫使模型进行更深入的思考。这种组合能够更有效地减少偏差,提高模型的推理能力。
关键设计:APriCoT的关键设计在于如何生成“不可知先验”的CoT提示。这通常需要仔细设计提示语,避免引入任何可能导致偏差的信息。例如,可以使用更抽象、更通用的语言,或者使用随机化的方法来生成CoT推理过程。此外,反事实提示的设计也需要考虑如何构造与原始问题相关但又不同的情景,以有效地迫使模型重新评估其推理过程。具体的参数设置和损失函数的使用情况在论文中未明确说明,属于未知信息。
🖼️ 关键图片
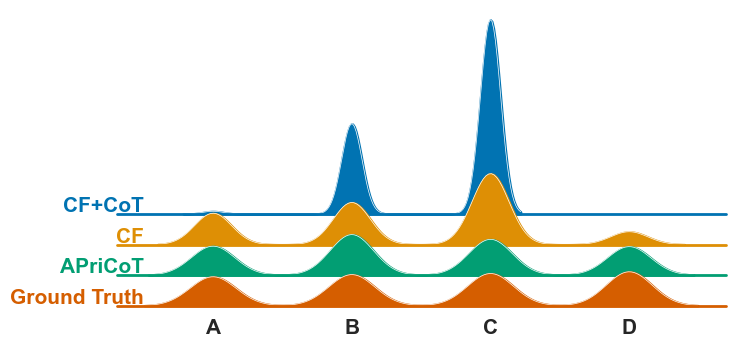


📊 实验亮点
实验结果表明,单独使用CoT的反事实提示不足以减轻偏差,而APriCoT能有效降低基础概率的影响,同时提高整体准确率。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。但整体而言,APriCoT在减轻偏差方面表现出显著优势。
🎯 应用场景
该研究成果可应用于各种需要语言模型进行复杂推理和决策的场景,例如智能客服、医疗诊断、金融分析等。通过减少模型偏差,可以提高决策的公平性和可靠性,避免因模型偏差导致的不良后果。未来,该方法可以进一步推广到其他自然语言处理任务中,提升模型的整体性能。
📄 摘要(原文)
Language models are known to absorb biases from their training data, leading to predictions driven by statistical regularities rather than semantic relevance. We investigate the impact of these biases on answer choice preferences in the Massive Multi-Task Language Understanding (MMLU) task. Our findings show that these biases are predictive of model preference and mirror human test-taking strategies even when chain of thought (CoT) reasoning is used. To address this issue, we introduce Counterfactual Prompting with Agnostically Primed CoT (APriCoT). We demonstrate that while Counterfactual Prompting with CoT alone is insufficient to mitigate bias, APriCoT effectively reduces the influence of base-rate probabilities while improving overall accuracy. Our results suggest that mitigating bias requires a slow thinking process which CoT alone may not provide as it tends to reinforce fast thinking model bias under some prompting methodologies. APriCoT is a step toward developing more robust and fair language models that can think slow.