The ShareLM Collection and Plugin: Contributing Human-Model Chats for the Benefit of the Community
作者: Shachar Don-Yehiya, Leshem Choshen, Omri Abend
分类: cs.CL
发布日期: 2024-08-15 (更新: 2025-03-03)
💡 一句话要点
提出ShareLM数据集与插件,促进人机对话数据共享,助力开源社区模型发展。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机对话 大型语言模型 数据集 Web插件 数据共享 开源社区 用户隐私
📋 核心要点
- 商业公司垄断人机对话数据,开源社区缺乏高质量的训练资源,限制了开源模型的发展。
- ShareLM通过Web插件收集用户自愿分享的人机对话数据,构建统一的数据集,促进数据共享。
- ShareLM插件允许用户评分和删除对话,保障用户隐私,鼓励用户积极参与数据贡献。
📝 摘要(中文)
人机对话能够反映用户的真实场景、行为和需求,是模型开发和研究的宝贵资源。虽然商业公司通过其模型的API收集用户数据,并内部使用这些数据来改进自身模型,但开源和研究社区在这方面相对滞后。我们推出了ShareLM数据集,这是一个统一的人类与大型语言模型对话集合,以及配套的插件,一个用于自愿贡献用户-模型对话的Web扩展。在少数平台共享其聊天记录的情况下,ShareLM插件增加了此功能,从而允许用户共享来自大多数平台的对话。该插件允许用户在对话和响应级别对他们的对话进行评分,并在对话离开用户的本地存储之前删除他们希望保密的对话。我们将插件对话作为ShareLM集合的一部分发布,并呼吁社区在开放的人机对话数据领域做出更多努力。代码、插件和数据均已发布。
🔬 方法详解
问题定义:现有的大型语言模型公司通过自身平台收集用户与模型的对话数据,用于改进其模型。然而,这些数据通常是私有的,开源社区难以获取。这导致开源社区在模型开发和研究方面落后于商业公司,缺乏足够的人机交互数据来训练和评估模型。因此,论文旨在解决开源社区缺乏高质量人机对话数据的问题。
核心思路:论文的核心思路是创建一个用户友好的Web插件,鼓励用户自愿分享他们与大型语言模型的对话。通过收集这些对话,构建一个公开可用的数据集,从而促进开源社区在人机对话领域的研究和发展。这种方法的核心在于利用社区的力量,共同构建一个共享的数据资源。
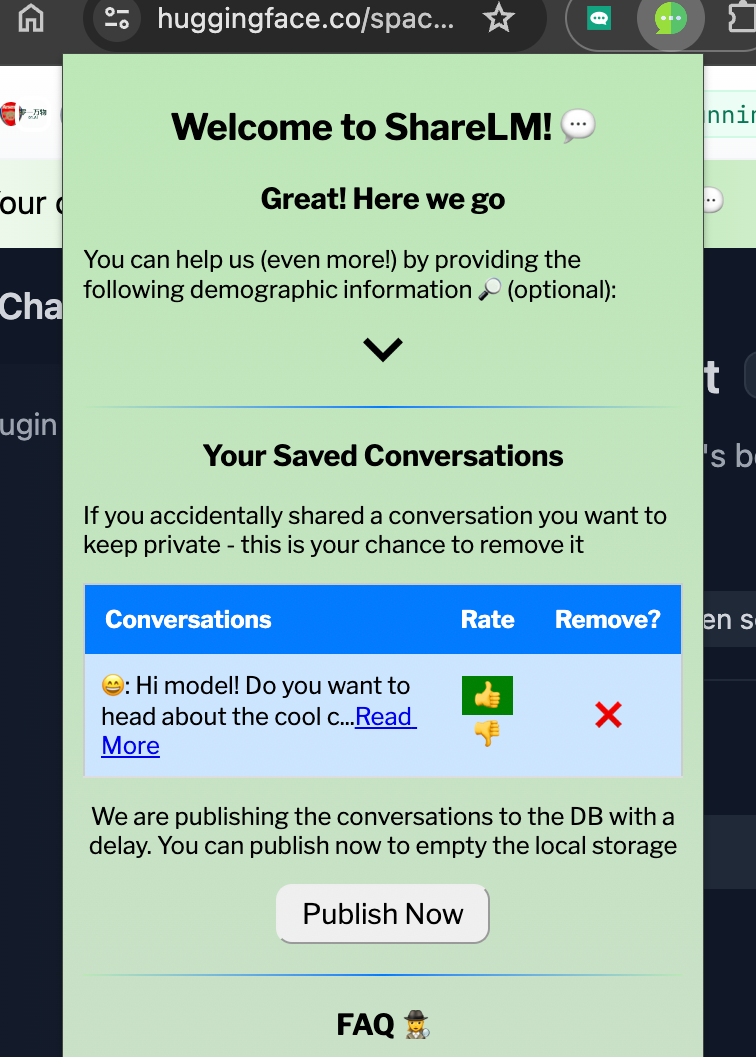
技术框架:ShareLM的技术框架主要包含两个部分:ShareLM数据集和ShareLM插件。ShareLM插件是一个Web浏览器扩展,用户安装后可以选择分享他们与各种大型语言模型的对话。插件允许用户在分享前对对话进行评分和编辑,以保护隐私。收集到的对话数据被整理成ShareLM数据集,供研究人员使用。
关键创新:ShareLM的关键创新在于其数据收集方式。与传统的由公司主导的数据收集方式不同,ShareLM采用了一种去中心化的、用户驱动的方法。这种方法能够收集到更广泛、更真实的用户数据,并且能够更好地保护用户隐私。此外,ShareLM插件支持多种平台,使得用户可以方便地分享来自不同平台的对话数据。
关键设计:ShareLM插件的关键设计包括:1) 用户隐私保护机制,允许用户在分享前删除敏感信息;2) 对话和回复级别的评分机制,用于评估对话质量;3) 支持多种平台的兼容性设计,确保插件可以在不同的Web浏览器和大型语言模型平台上运行。此外,数据集的构建过程中,需要对收集到的数据进行清洗和标注,以提高数据质量。
🖼️ 关键图片
📊 实验亮点
ShareLM插件成功收集了大量来自不同平台的人机对话数据,构建了一个公开可用的数据集。初步分析显示,该数据集包含了各种主题和对话风格,能够为研究人员提供丰富的数据资源。用户对ShareLM插件的反馈积极,表明用户愿意参与数据共享,为开源社区做出贡献。具体的性能数据和对比基线将在后续研究中进一步分析。
🎯 应用场景
ShareLM数据集和插件可广泛应用于人机对话系统研究、大型语言模型训练和评估、用户行为分析等领域。通过分析用户与模型的对话,可以更好地理解用户的需求和偏好,从而改进模型的性能和用户体验。此外,ShareLM还可以用于开发更智能的聊天机器人、虚拟助手等应用,并促进人机交互技术的进步。
📄 摘要(原文)
Human-model conversations provide a window into users' real-world scenarios, behavior, and needs, and thus are a valuable resource for model development and research. While for-profit companies collect user data through the APIs of their models, using it internally to improve their own models, the open source and research community lags behind. We introduce the ShareLM collection, a unified set of human conversations with large language models, and its accompanying plugin, a Web extension for voluntarily contributing user-model conversations. Where few platforms share their chats, the ShareLM plugin adds this functionality, thus, allowing users to share conversations from most platforms. The plugin allows the user to rate their conversations, both at the conversation and the response levels, and delete conversations they prefer to keep private before they ever leave the user's local storage. We release the plugin conversations as part of the ShareLM collection, and call for more community effort in the field of open human-model data. The code, plugin, and data are available.