P/D-Serve: Serving Disaggregated Large Language Model at Scale
作者: Yibo Jin, Tao Wang, Huimin Lin, Mingyang Song, Peiyang Li, Yipeng Ma, Yicheng Shan, Zhengfan Yuan, Cailong Li, Yajing Sun, Tiandeng Wu, Xing Chu, Ruizhi Huan, Li Ma, Xiao You, Wenting Zhou, Yunpeng Ye, Wen Liu, Xiangkun Xu, Yongsheng Zhang, Tiantian Dong, Jiawei Zhu, Zhe Wang, Xijian Ju, Jianxun Song, Haoliang Cheng, Xiaojing Li, Jiandong Ding, Hefei Guo, Zhengyong Zhang
分类: cs.DC, cs.CL, cs.LG
发布日期: 2024-08-15
💡 一句话要点
P/D-Serve:大规模解耦LLM服务系统,优化预填充和解码性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模LLM服务 解耦架构 预填充优化 解码优化 RDMA KVCache传输 分布式系统
📋 核心要点
- 现有LLM服务方法难以有效处理多样化的请求,导致预填充和解码阶段的性能瓶颈,尤其是在大规模部署场景下。
- P/D-Serve通过细粒度的P/D组织、按需转发和优化的D2D传输,实现了对LLM服务性能的端到端优化。
- 实验结果表明,P/D-Serve在吞吐量、TTFT SLO和D2D传输时间方面均有显著提升,并在实际商业环境中成功部署。
📝 摘要(中文)
在大规模xPU设备(GPU或NPU)上服务解耦的大型语言模型(LLM)面临诸多挑战。现有方法忽略了多样性(各种前缀和潮汐请求),混合处理所有提示不充分。为了促进每个场景的相似性并最小化预填充(P)和解码(D)处理的内部不匹配,需要细粒度的组织,动态调整P/D比例以获得更好的性能。此外,由于对工作负载(队列状态或维护的连接)的估计不准确,全局调度器容易在预填充中导致不必要的超时。块固定的设备到设备(D2D)KVCache传输在集群级RDMA(远程直接内存访问)上未能达到预期的D2D利用率。为了克服上述问题,本文提出了一个端到端系统P/D-Serve,符合MLOps(机器学习运营)范例,该系统对端到端(E2E)P/D性能进行建模,并实现:1)细粒度的P/D组织,根据需要将服务与RoCE(基于融合以太网的RDMA)映射,以促进相似的处理和动态调整P/D比例;2)根据拒绝情况按需转发以实现空闲预填充,将调度器与常规不准确的报告和本地队列分离,以避免预填充中的超时;3)通过优化的D2D访问实现高效的KVCache传输。P/D-Serve基于Ascend和MindSpore实现,已在数万个NPU上商业部署超过八个月,并在E2E吞吐量、首个token时间(TTFT)SLO(服务级别目标)和D2D传输时间方面分别实现了60%、42%和46%的改进。作为具有优化的E2E系统,与聚合LLM相比,P/D-Serve在吞吐量上实现了6.7倍的增长。
🔬 方法详解
问题定义:现有的大型语言模型服务系统,尤其是在大规模分布式部署环境下,面临着请求多样性、调度不准确以及数据传输效率低下的问题。具体来说,不同的请求具有不同的前缀和长度,传统的混合处理方式无法充分利用相似性,导致预填充和解码效率低下。同时,全局调度器难以准确估计工作负载,容易造成预填充超时。此外,传统的块固定D2D KVCache传输方式在集群级别的RDMA上无法达到理想的利用率。
核心思路:P/D-Serve的核心思路是通过细粒度的P/D组织、按需转发和优化的D2D传输,实现对LLM服务性能的端到端优化。通过细粒度组织,将相似的请求进行分组处理,动态调整P/D比例,提高处理效率。通过按需转发,避免因调度不准确导致的预填充超时。通过优化的D2D传输,提高数据传输效率,从而提升整体服务性能。
技术框架:P/D-Serve是一个端到端的系统,其主要模块包括:细粒度的P/D组织模块、按需转发模块和优化的D2D传输模块。细粒度的P/D组织模块负责将相似的请求进行分组,并动态调整P/D比例。按需转发模块负责在预填充资源空闲时,将请求转发到空闲资源上,避免预填充超时。优化的D2D传输模块负责高效地进行KVCache传输。整体流程是:接收到请求后,首先进行细粒度的P/D组织,然后进行预填充和解码,如果预填充资源不足,则进行按需转发,最后通过优化的D2D传输进行数据传输。
关键创新:P/D-Serve的关键创新在于其端到端的优化策略,以及针对大规模分布式部署环境下的特定问题所提出的解决方案。与现有方法相比,P/D-Serve更加注重请求的多样性,并能够根据实际情况动态调整P/D比例。此外,P/D-Serve通过按需转发机制,有效避免了预填充超时问题。最后,P/D-Serve通过优化的D2D传输,提高了数据传输效率。
关键设计:P/D-Serve的关键设计包括:1) 细粒度的P/D组织策略,需要设计合适的相似度度量方法和分组算法;2) 按需转发策略,需要设计合适的资源调度算法和转发机制;3) 优化的D2D传输策略,需要设计合适的传输协议和数据布局。
🖼️ 关键图片
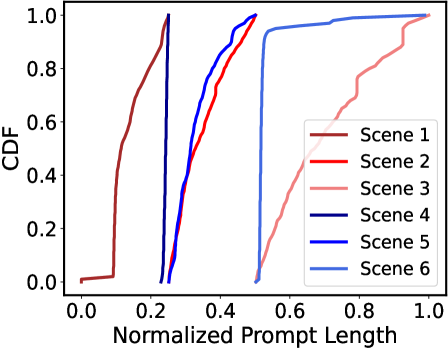
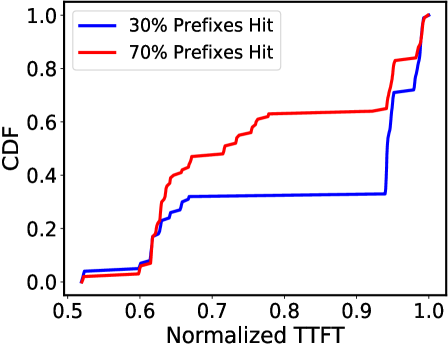

📊 实验亮点
P/D-Serve在数万个NPU上进行了商业部署,并取得了显著的性能提升。与聚合LLM相比,P/D-Serve在吞吐量上实现了6.7倍的增长。此外,P/D-Serve在E2E吞吐量、TTFT SLO和D2D传输时间方面分别实现了60%、42%和46%的改进。这些实验结果表明,P/D-Serve能够有效提升大规模LLM服务的性能。
🎯 应用场景
P/D-Serve适用于需要大规模部署LLM服务的场景,例如在线问答、智能客服、内容生成等。该系统能够显著提升LLM服务的吞吐量和响应速度,降低服务成本,具有重要的实际应用价值。未来,P/D-Serve可以进一步扩展到支持更多类型的LLM模型和硬件平台,并与其他优化技术相结合,以实现更高的性能。
📄 摘要(原文)
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.