FuseChat: Knowledge Fusion of Chat Models
作者: Fanqi Wan, Longguang Zhong, Ziyi Yang, Ruijun Chen, Xiaojun Quan
分类: cs.CL
发布日期: 2024-08-15
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
FuseChat:通过轻量级持续训练融合多个聊天模型知识,提升性能并降低成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识融合 大型语言模型 聊天模型 轻量级微调 Token对齐 模型合并 指令遵循
📋 核心要点
- 从头训练LLM成本高昂且易导致能力冗余,知识融合旨在集成现有LLM,但如何有效融合不同架构和能力的聊天模型是一个挑战。
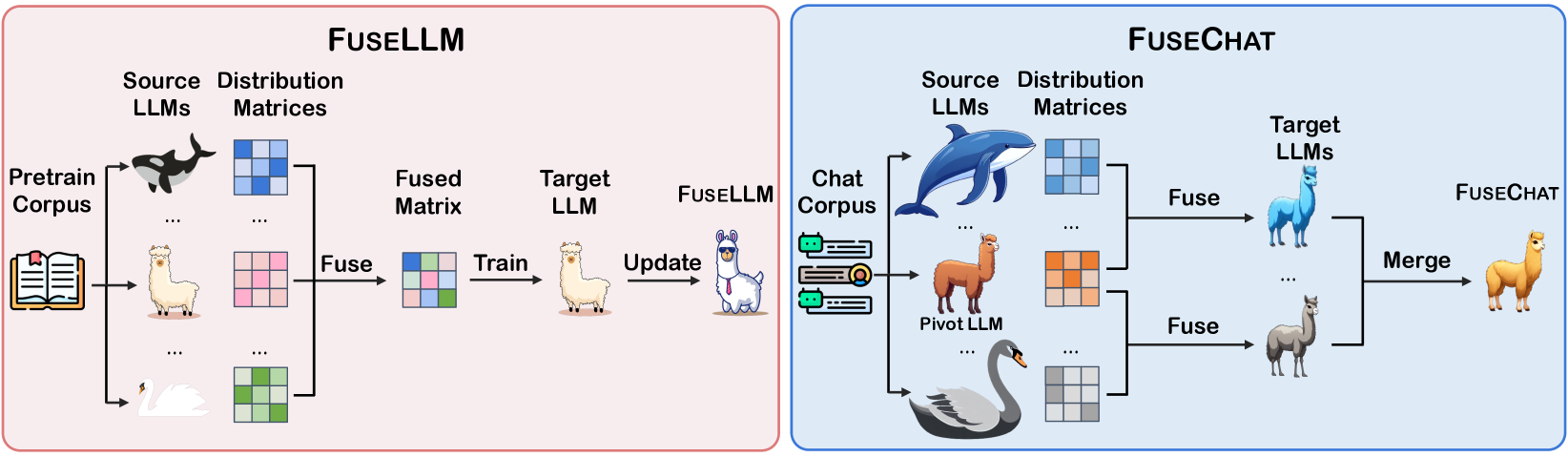
- FuseChat通过两阶段方法解决此问题:首先,成对融合不同LLM,并使用token对齐处理结构差异;其次,在参数空间中合并模型,并根据参数更新幅度确定合并系数。
- 实验表明,FuseChat-7B在指令遵循任务上优于多种基线模型,性能甚至可与更大的Mixtral-8x7B-Instruct媲美,接近GPT-3.5-Turbo-1106。
📝 摘要(中文)
从头训练大型语言模型(LLM)虽然可以产生具有独特能力和优势的模型,但成本高昂,并且可能导致能力冗余。知识融合旨在通过轻量级的持续训练,将具有不同架构和能力的现有LLM集成到一个更强大的LLM中,从而减少对昂贵LLM开发的需求。本文提出了一个用于聊天LLM知识融合的新框架FuseChat,该框架包含两个主要阶段。首先,我们对不同结构和规模的源聊天LLM进行成对知识融合,通过轻量级微调创建多个具有相同结构和规模的目标LLM。在此过程中,引入了一种基于统计的token对齐方法,作为融合具有不同结构的LLM的基石。其次,我们在参数空间中合并这些目标LLM,并提出了一种新方法,用于根据微调前后参数更新的幅度来确定合并系数。我们使用六个具有不同架构和规模的著名聊天LLM(包括OpenChat-3.5-7B、Starling-LM-7B-alpha、NH2-SOLAR-10.7B、InternLM2-Chat-20B、Mixtral-8x7B-Instruct和Qwen-1.5-Chat-72B)实施并验证了FuseChat。在AlpacaEval 2.0和MT-Bench两个指令遵循基准上的实验结果表明,FuseChat-7B优于各种规模的基线模型。我们的模型甚至可以与更大的Mixtral-8x7B-Instruct相媲美,并在MT-Bench上接近GPT-3.5-Turbo-1106。
🔬 方法详解
问题定义:现有的大型语言模型训练成本高昂,并且可能存在能力冗余。知识融合旨在利用已有的、具有不同架构和能力的LLM,通过轻量级的训练方式,构建一个更强大的LLM。然而,如何有效地融合这些异构的聊天模型,尤其是在模型结构差异显著的情况下,是一个关键的挑战。现有方法可能无法很好地处理不同模型之间的结构差异,导致融合后的模型性能提升有限。
核心思路:FuseChat的核心思路是通过两阶段的融合策略,首先进行成对的知识融合,将不同结构的源模型转化为结构一致的目标模型;然后,在参数空间中合并这些目标模型。这种分阶段的方法允许分别处理结构差异和知识合并,从而更有效地利用不同模型的优势。基于统计的token对齐方法解决了不同结构模型融合的难题,参数更新幅度指导的合并系数则保证了重要知识的保留。
技术框架:FuseChat框架包含两个主要阶段:1) 成对知识融合:选择两个源聊天LLM,通过轻量级微调,将其中一个模型的知识迁移到另一个模型上,生成多个具有相同结构和大小的目标LLM。此阶段的关键是token对齐。2) 模型合并:在参数空间中合并这些目标LLM,生成最终的FuseChat模型。合并系数的确定基于微调前后参数更新的幅度。
关键创新:FuseChat的主要创新点在于:1) 基于统计的Token对齐方法:该方法能够有效处理不同结构的LLM之间的知识迁移问题,是实现成对知识融合的关键。2) 基于参数更新幅度的合并系数确定方法:该方法能够更准确地评估不同模型的重要性,从而在模型合并过程中更好地保留重要知识。
关键设计:在成对知识融合阶段,使用轻量级微调策略,避免过度拟合。Token对齐方法基于源模型和目标模型在大量文本上的token共现统计信息。在模型合并阶段,合并系数α的计算公式为:α = |Δθ1| / (|Δθ1| + |Δθ2|),其中Δθ1和Δθ2分别表示两个模型在微调前后的参数更新幅度。损失函数采用标准的交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FuseChat-7B在AlpacaEval 2.0和MT-Bench两个指令遵循基准上均取得了显著的性能提升,超越了多种不同规模的基线模型。尤其值得注意的是,FuseChat-7B的性能甚至可以与更大的Mixtral-8x7B-Instruct模型相媲美,并在MT-Bench上接近GPT-3.5-Turbo-1106的水平,证明了该方法的有效性。
🎯 应用场景
FuseChat技术可应用于快速构建定制化聊天机器人,尤其是在资源有限的情况下。通过融合现有模型,可以避免从头训练的巨大开销,并快速获得性能优异的聊天模型。该技术还可用于持续学习,不断融合新的知识和能力,提升聊天机器人的智能化水平。此外,该方法可以推广到其他类型的LLM融合场景,具有广泛的应用前景。
📄 摘要(原文)
While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, it incurs substantial costs and may lead to redundancy in competencies. Knowledge fusion aims to integrate existing LLMs of diverse architectures and capabilities into a more potent LLM through lightweight continual training, thereby reducing the need for costly LLM development. In this work, we propose a new framework for the knowledge fusion of chat LLMs through two main stages, resulting in FuseChat. Firstly, we conduct pairwise knowledge fusion on source chat LLMs of varying structures and scales to create multiple target LLMs with identical structure and size via lightweight fine-tuning. During this process, a statistics-based token alignment approach is introduced as the cornerstone for fusing LLMs with different structures. Secondly, we merge these target LLMs within the parameter space, where we propose a novel method for determining the merging coefficients based on the magnitude of parameter updates before and after fine-tuning. We implement and validate FuseChat using six prominent chat LLMs with diverse architectures and scales, including OpenChat-3.5-7B, Starling-LM-7B-alpha, NH2-SOLAR-10.7B, InternLM2-Chat-20B, Mixtral-8x7B-Instruct, and Qwen-1.5-Chat-72B. Experimental results on two instruction-following benchmarks, AlpacaEval 2.0 and MT-Bench, demonstrate the superiority of FuseChat-7B over baselines of various sizes. Our model is even comparable to the larger Mixtral-8x7B-Instruct and approaches GPT-3.5-Turbo-1106 on MT-Bench. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/FuseAI}.