Coupling without Communication and Drafter-Invariant Speculative Decoding
作者: Majid Daliri, Christopher Musco, Ananda Theertha Suresh
分类: cs.DS, cs.CL, cs.LG
发布日期: 2024-08-15 (更新: 2025-08-20)
备注: 18 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Gumbel采样的无通信耦合方法,提升推测解码性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无通信耦合 Gumbel采样 推测解码 语言生成 分布式计算
📋 核心要点
- 现有无通信耦合方法(如Weighted MinHash)在最坏情况下性能受限,存在改进空间。
- 提出基于Gumbel采样的无通信耦合协议,理论上证明其性能优于或等于Weighted MinHash。
- 将该协议应用于推测解码,构建了与起草者无关的方案,并在实验中验证了其有效性。
📝 摘要(中文)
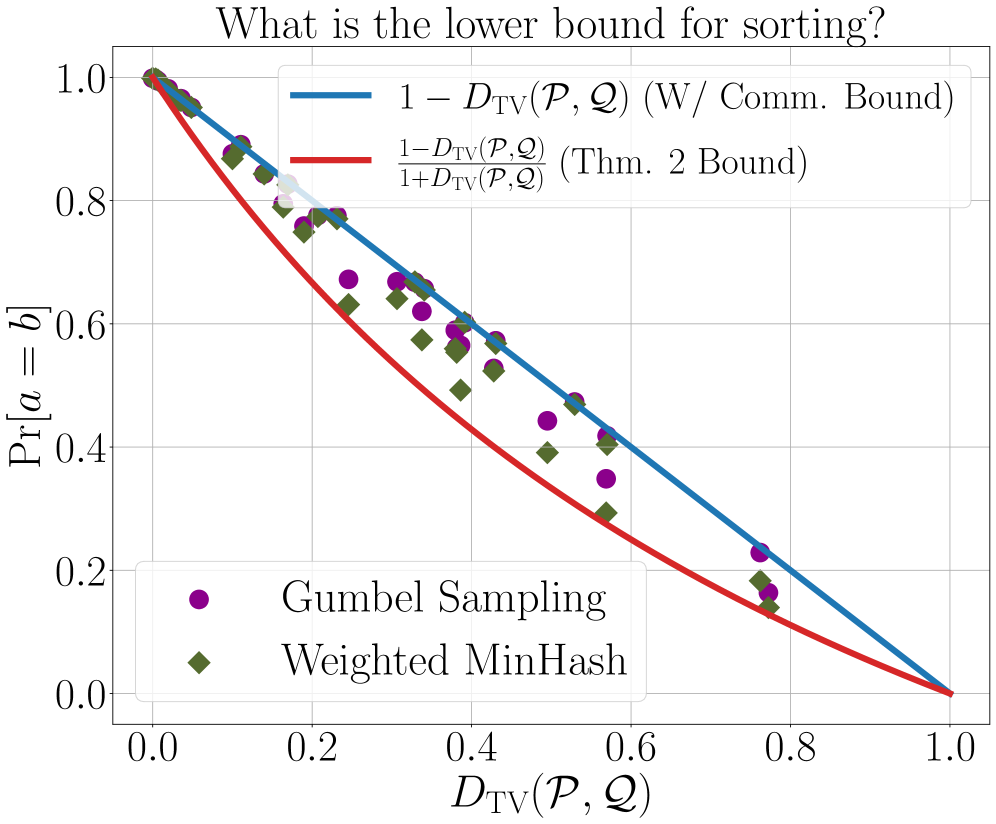
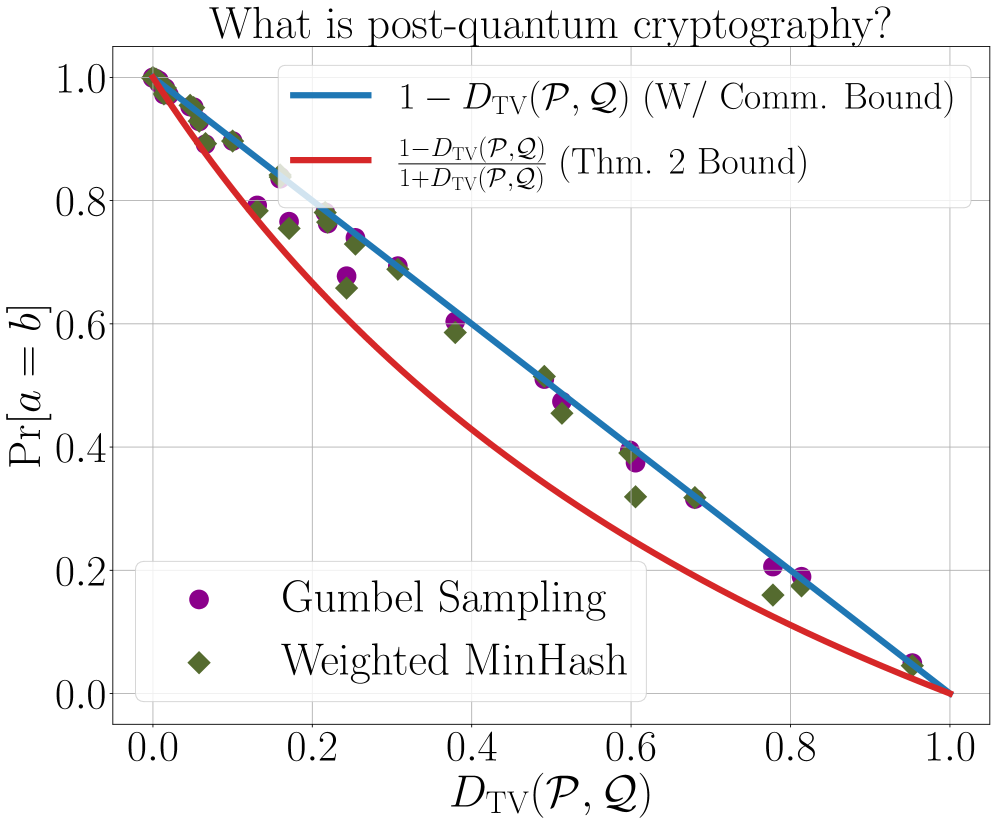
本文研究了无通信耦合问题,即Alice和Bob分别拥有分布P和Q,在不进行任何通信的情况下,如何采样a~P和b~Q,使得a=b的概率尽可能高。虽然Weighted MinHash算法已被证明在最坏情况下是最优的,但本文提供了一个更简单的最优性证明,并提出了一种基于Gumbel采样的协议,该协议在所有分布对上均优于或等于Weighted MinHash。重要的是,这种改进可以转化为实践。本文将无通信耦合应用于推测解码,构建了与起草者无关的推测解码方案。实验结果表明,在语言生成任务中,Gumbel采样优于Weighted MinHash。代码已开源。
🔬 方法详解
问题定义:论文旨在解决无通信耦合问题,即Alice和Bob分别拥有概率分布P和Q,在没有任何通信的情况下,如何独立地生成样本a和b,使得a=b的概率最大化。现有方法,如基于Weighted MinHash的算法,虽然在最坏情况下被证明是最优的,但在实际应用中仍有提升空间,尤其是在特定分布下可能存在更优的耦合策略。
核心思路:论文的核心思路是利用Gumbel采样来构建一种新的无通信耦合协议。Gumbel分布具有良好的数学性质,可以用于近似最大值,从而实现更有效的耦合。通过精心设计采样策略,使得Alice和Bob能够独立地生成更接近的样本,从而提高a=b的概率。
技术框架:整体框架包括以下步骤:1. Alice和Bob共享公共随机数种子。2. Alice根据分布P,Bob根据分布Q,分别使用公共随机数种子和Gumbel采样生成样本a和b。3. 比较a和b,如果a=b,则耦合成功;否则,耦合失败。关键在于Gumbel采样的具体实现,需要根据P和Q的特性进行调整。
关键创新:最重要的技术创新点在于使用Gumbel采样替代Weighted MinHash。Gumbel采样能够提供一种Pareto改进,即对于任何分布对P和Q,Gumbel采样都能达到等于或优于Weighted MinHash的耦合概率。这表明Gumbel采样在无通信耦合问题上具有更强的适应性和潜力。
关键设计:关键设计在于如何将Gumbel采样应用于具体的概率分布P和Q。具体来说,需要设计一个合适的函数,将P和Q的概率值映射到Gumbel分布的参数,然后根据这些参数进行采样。此外,还需要考虑如何选择合适的公共随机数种子,以保证采样结果的随机性和独立性。论文中可能涉及一些具体的数学公式和算法细节,用于指导Gumbel采样的实现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于Gumbel采样的无通信耦合方法在语言生成任务中优于Weighted MinHash。具体而言,在推测解码的应用中,Gumbel采样能够显著提高解码速度,同时保证生成文本的质量。开源代码的提供也方便了其他研究者复现和应用该方法。
🎯 应用场景
该研究成果可应用于任何需要无通信耦合的场景,例如分布式计算、隐私保护机器学习和联邦学习。特别是在推测解码中,可以构建与起草者无关的解码方案,提高解码效率和公平性。未来,该方法有望推广到其他序列生成任务和更复杂的模型中。
📄 摘要(原文)
Suppose Alice has a distribution $P$ and Bob has a distribution $Q$. Alice wants to draw a sample $a\sim P$ and Bob a sample $b \sim Q$ such that $a = b$ with as high of probability as possible. It is well-known that, by sampling from an optimal coupling between the distributions, Alice and Bob can achieve $\Pr[a = b] = 1 - D_{TV}(P,Q)$, where $D_{TV}(P,Q)$ is the total variation distance between $P$ and $Q$. What if Alice and Bob must solve this same problem \emph{without communicating at all?} Perhaps surprisingly, with access to public randomness, they can still achieve $\Pr[a = b] \geq \frac{1 - D_{TV}(P,Q)}{1 + D_{TV}(P,Q)} \geq 1-2D_{TV}(P,Q)$ using a simple protocol based on the Weighted MinHash algorithm. This bound was shown to be optimal in the worst-case by [Bavarian et al., 2020]. In this work, we revisit the communication-free coupling problem. We provide a simpler proof of the optimality result from [Bavarian et al., 2020]. We show that, while the worst-case success probability of Weighted MinHash cannot be improved, an equally simple protocol based on Gumbel sampling offers a Pareto improvement: for every pair of distributions $P, Q$, Gumbel sampling achieves an equal or higher value of $\Pr[a = b]$ than Weighted MinHash. Importantly, this improvement translates to practice. We demonstrate an application of communication-free coupling to \emph{speculative decoding}, a recent method for accelerating autoregressive large language models [Leviathan, Kalman, Matias, ICML 2023]. We show that communication-free protocols can be used to contruct \emph{\CSD{}} schemes, which have the desirable property that their output is fixed given a fixed random seed, regardless of what drafter is used for speculation. In experiments on a language generation task, Gumbel sampling outperforms Weighted MinHash. Code is available at https://github.com/majid-daliri/DISD.