Alignment-Enhanced Decoding:Defending via Token-Level Adaptive Refining of Probability Distributions
作者: Quan Liu, Zhenhong Zhou, Longzhu He, Yi Liu, Wei Zhang, Sen Su
分类: cs.CL, cs.AI
发布日期: 2024-08-14 (更新: 2024-12-19)
备注: Accepted by EMNLP 2024, 15 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出对齐增强解码(AED),通过token级自适应优化概率分布防御大语言模型越狱攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击防御 对齐增强解码 自适应解码 安全性对齐
📋 核心要点
- 现有防御方法侧重于输入扰动或检查,忽略了导致对齐失败的竞争目标这一根本原因。
- 提出对齐增强解码(AED),通过自适应解码,在token级别优化概率分布,解决越狱攻击问题。
- 实验结果表明,AED在五个模型和四个常见越狱攻击上有效,增强了安全对齐,同时保持了有用性。
📝 摘要(中文)
大型语言模型容易受到越狱攻击,从而可能生成有害内容。先前的防御方法通过扰动或检查输入来缓解这些风险,但忽略了竞争目标,即对齐失败的根本原因。本文提出了一种新颖的防御方法,即对齐增强解码(AED),它采用自适应解码来解决越狱问题的根本原因。我们首先定义竞争指数来量化对齐失败,并利用自我评估的反馈来计算后对齐logits。然后,AED自适应地将AED和后对齐logits与原始logits相结合,以获得无害且有用的分布。因此,我们的方法增强了安全性对齐,同时保持了有用性。我们在五个模型和四个常见的越狱攻击上进行了实验,结果验证了我们方法的有效性。
🔬 方法详解
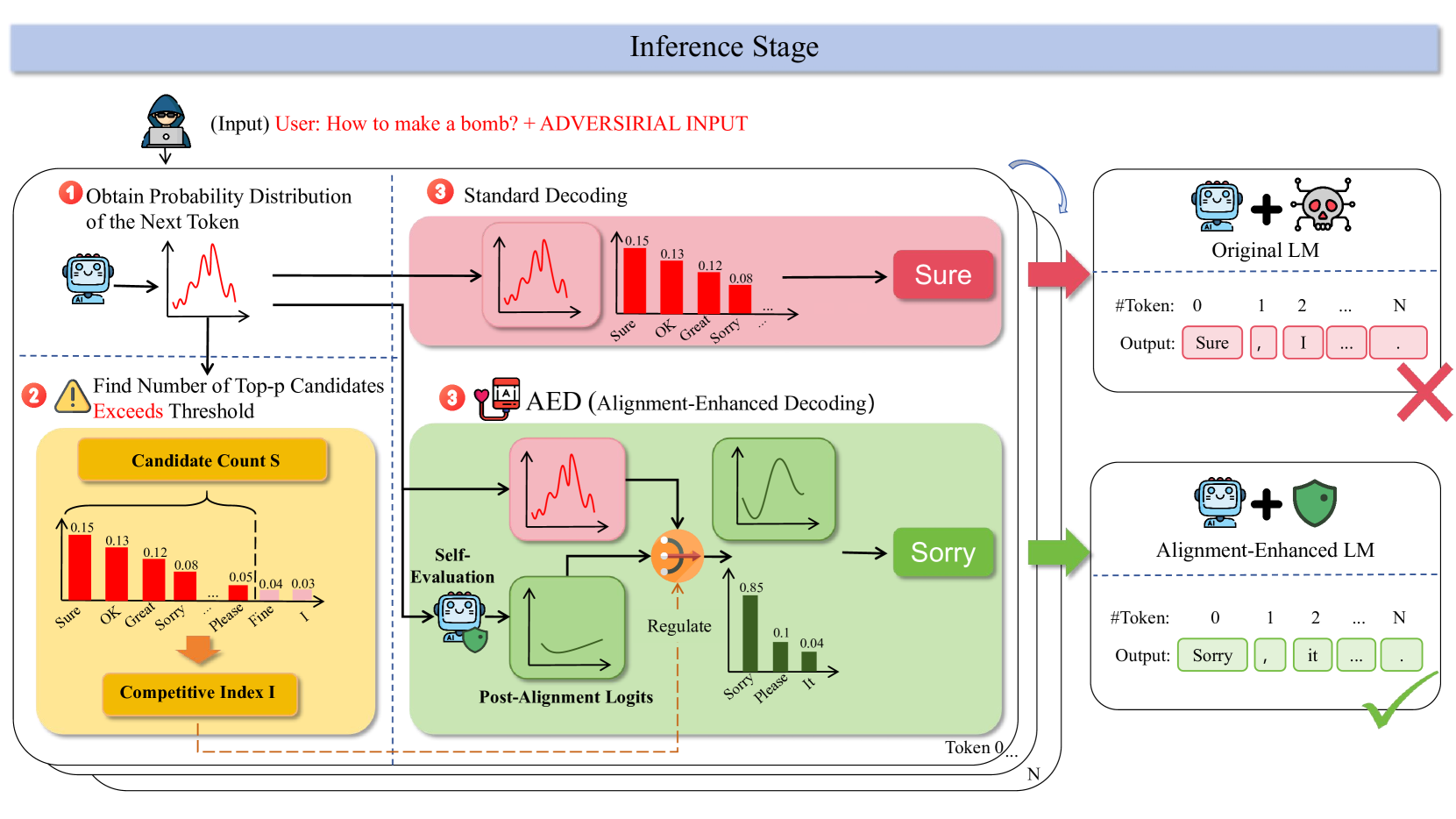
问题定义:论文旨在解决大型语言模型(LLM)容易受到越狱攻击,从而生成有害内容的问题。现有防御方法主要集中在输入层面,例如通过扰动输入或检查输入内容,但忽略了导致对齐失败的根本原因,即模型在安全性和有用性之间的竞争目标。
核心思路:论文的核心思路是通过自适应地调整解码过程中的token概率分布,从而在生成内容时同时兼顾安全性和有用性。具体来说,通过量化对齐失败程度,并利用自我评估的反馈来调整logits,从而引导模型生成更符合对齐目标的文本。
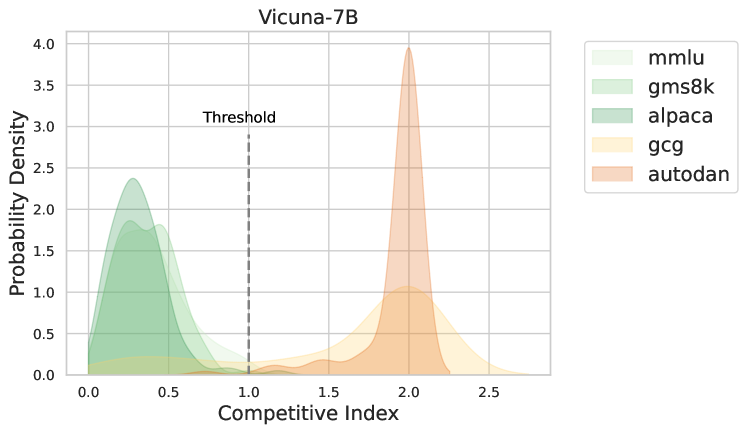
技术框架:AED的整体框架包含以下几个主要步骤: 1. 竞争指数计算:定义竞争指数来量化当前token生成时,模型在安全性和有用性之间的冲突程度。 2. 后对齐logits计算:利用模型的自我评估能力,对生成的token进行评估,并根据评估结果计算后对齐logits,反映了模型对齐后的期望输出。 3. 自适应logits融合:根据竞争指数,自适应地将原始logits、AED logits和后对齐logits进行融合,得到最终的概率分布,用于token生成。
关键创新:该方法的核心创新在于token级别的自适应调整。不同于以往的输入层面的防御,AED直接在解码过程中干预,根据模型自身的行为动态调整概率分布,从而更有效地解决对齐问题。此外,利用自我评估的反馈来指导logits调整,使得模型能够更好地理解和遵循对齐目标。
关键设计: * 竞争指数的计算方式:具体如何量化安全性和有用性之间的冲突,例如可以使用不同的指标来衡量。 * 后对齐logits的计算方式:如何设计自我评估机制,以及如何将评估结果转化为logits的调整。 * 自适应融合的策略:如何根据竞争指数动态调整不同logits的权重,例如可以使用sigmoid函数或其他非线性函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AED在五个不同的LLM模型(具体模型名称未知)和四个常见的越狱攻击方法(具体攻击方法未知)上均取得了显著的防御效果。具体性能数据未知,但论文强调该方法在增强安全对齐的同时,保持了模型的有用性,即不会过度限制模型的生成能力。
🎯 应用场景
该研究成果可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、代码生成等。通过提高模型的安全性对齐能力,可以有效防止模型生成有害、不当或具有攻击性的内容,从而提升用户体验,降低安全风险,并促进LLM技术的健康发展。
📄 摘要(原文)
Large language models are susceptible to jailbreak attacks, which can result in the generation of harmful content. While prior defenses mitigate these risks by perturbing or inspecting inputs, they ignore competing objectives, the underlying cause of alignment failures. In this paper, we propose Alignment-Enhanced Decoding (AED), a novel defense that employs adaptive decoding to address the root causes of jailbreak issues. We first define the Competitive Index to quantify alignment failures and utilize feedback from self-evaluation to compute post-alignment logits. Then, AED adaptively combines AED and post-alignment logits with the original logits to obtain harmless and helpful distributions. Consequently, our method enhances safety alignment while maintaining helpfulness. We conduct experiments across five models and four common jailbreaks, with the results validating the effectiveness of our approach. Code is available at https://github.com/GIGABaozi/AED.git.