Assessing the Role of Lexical Semantics in Cross-lingual Transfer through Controlled Manipulations
作者: Roy Ilani, Taelin Karidi, Omri Abend
分类: cs.CL
发布日期: 2024-08-14
💡 一句话要点
通过可控操纵评估词汇语义在跨语言迁移中的作用
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 跨语言迁移学习 词汇语义 语言属性 可控操纵 翻译熵
📋 核心要点
- 跨语言迁移学习效果显著,但对其内在机制的理解尚不充分,尤其是在不同语言属性的影响方面。
- 该研究通过操纵英语句子,模拟目标语言的特性,从而评估不同语言属性对跨语言对齐的影响。
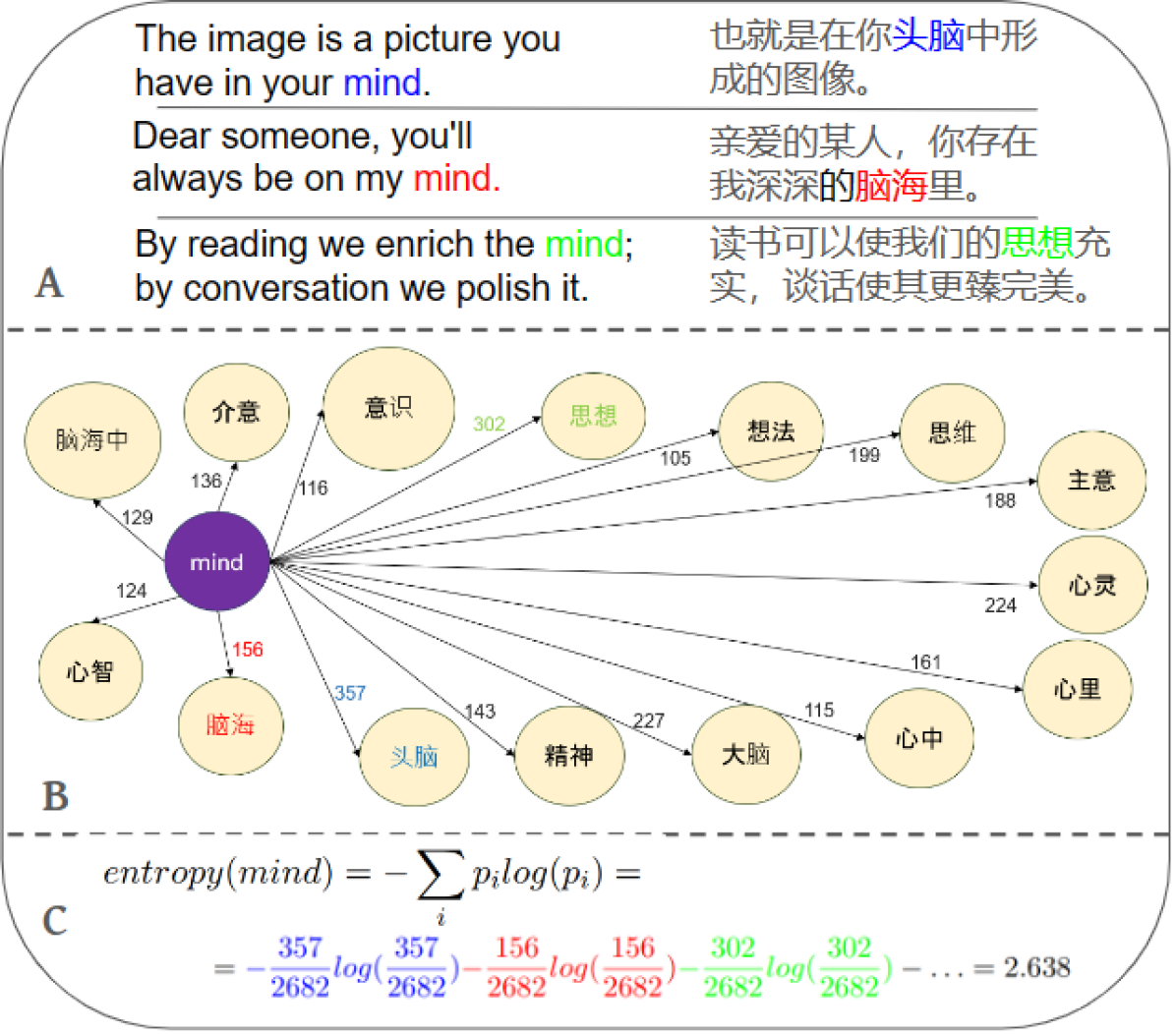
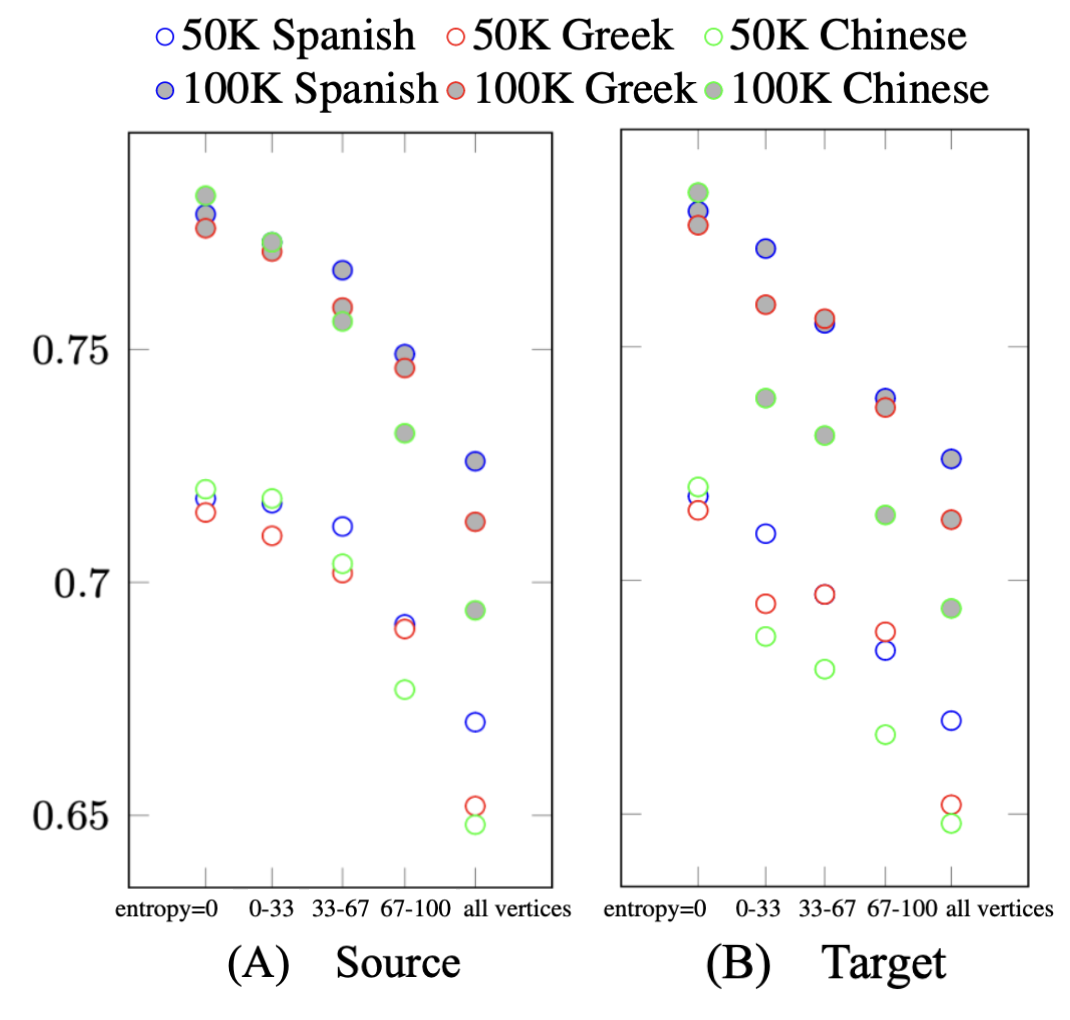
- 实验表明,词汇匹配程度(通过翻译熵衡量)对跨语言对齐质量有显著影响,而脚本或词序的影响较小。
📝 摘要(中文)
跨语言模型迁移在许多场景中有效,但对其工作条件的理解仍然有限。本文重点评估词汇语义在跨语言迁移中的作用,并将其影响与其他语言属性进行比较。通过单独检查每个语言属性,我们系统地分析了英语和目标语言之间的差异如何影响将该语言与英语预训练表示空间对齐的能力。我们通过人为地操纵英语句子来模拟目标语言的特定特征,并报告每次操纵对与表示空间对齐质量的影响。我们表明,虽然诸如脚本或词序之类的属性对对齐质量的影响有限,但两种语言之间的词汇匹配程度(我们使用翻译熵的度量来定义)会极大地影响对齐质量。
🔬 方法详解
问题定义:论文旨在深入理解跨语言迁移学习中,不同语言属性(如词汇语义、脚本、词序等)对模型性能的影响。现有方法缺乏对这些因素的系统性分析,难以解释跨语言迁移成功或失败的原因。
核心思路:论文的核心思路是通过可控的实验操纵,人为改变源语言(英语)的某些属性,使其更接近目标语言,然后观察这些改变对跨语言对齐效果的影响。通过这种方式,可以隔离并评估每个语言属性的贡献。
技术框架:论文采用了一种基于操纵的实验框架。首先,选择一系列目标语言和需要评估的语言属性。然后,设计相应的操纵方法,将英语句子进行修改,使其在特定属性上更接近目标语言。最后,使用某种跨语言对齐方法(具体方法未知)将修改后的英语句子与目标语言的表示空间对齐,并评估对齐质量。
关键创新:该研究的关键创新在于其系统性的实验设计,通过可控的操纵来隔离和评估不同语言属性的影响。这种方法避免了直接比较不同语言的复杂性,从而更清晰地揭示了跨语言迁移的内在机制。
关键设计:论文的关键设计在于如何选择和实现对英语句子的操纵。例如,为了模拟不同的词序,可能需要对英语句子进行句法分析,然后按照目标语言的词序规则重新排列单词。为了模拟不同的脚本,可能需要将英语单词翻译成目标语言,然后使用目标语言的脚本书写。此外,如何量化词汇匹配程度(使用翻译熵)也是一个关键设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,词汇匹配程度(通过翻译熵衡量)对跨语言对齐质量有显著影响。具体来说,词汇匹配程度高的语言更容易与英语预训练表示空间对齐,而脚本或词序等属性的影响相对较小。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于改进跨语言自然语言处理系统的设计,例如机器翻译、跨语言信息检索等。通过更好地理解不同语言属性的影响,可以更有针对性地选择和调整跨语言迁移策略,提高模型在低资源语言上的性能。此外,该研究也有助于开发更有效的跨语言预训练方法。
📄 摘要(原文)
While cross-linguistic model transfer is effective in many settings, there is still limited understanding of the conditions under which it works. In this paper, we focus on assessing the role of lexical semantics in cross-lingual transfer, as we compare its impact to that of other language properties. Examining each language property individually, we systematically analyze how differences between English and a target language influence the capacity to align the language with an English pretrained representation space. We do so by artificially manipulating the English sentences in ways that mimic specific characteristics of the target language, and reporting the effect of each manipulation on the quality of alignment with the representation space. We show that while properties such as the script or word order only have a limited impact on alignment quality, the degree of lexical matching between the two languages, which we define using a measure of translation entropy, greatly affects it.