Knowledge in Superposition: Unveiling the Failures of Lifelong Knowledge Editing for Large Language Models
作者: Chenhui Hu, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
分类: cs.CL
发布日期: 2024-08-14 (更新: 2025-02-26)
备注: To be published in AAAI 2025 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示大语言模型终身知识编辑失败的原因:知识叠加现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 终身学习 大语言模型 知识叠加 线性联想记忆
📋 核心要点
- 现有知识编辑方法在终身学习场景下扩展性不足,无法持续更新知识。
- 论文通过数学推导,发现知识叠加是导致终身知识编辑失败的根本原因。
- 实验证明知识叠加在多种语言模型中普遍存在,并呈现特定的统计特性。
📝 摘要(中文)
知识编辑旨在更新大语言模型(LLMs)中过时或不正确的知识。然而,当前的知识编辑方法在终身编辑方面的可扩展性有限。本研究探讨了知识编辑在终身编辑中失败的根本原因。我们从线性联想记忆推导出的闭式解开始,该解是当前最先进的知识编辑方法的基础。我们将该解从单次编辑扩展到终身编辑,并通过严格的数学推导,在最终解中识别出一个干扰项,表明编辑知识可能会影响不相关的知识。对干扰项的进一步分析揭示了其与知识表示之间的叠加密切相关。当语言模型中不存在知识叠加时,干扰项消失,从而实现无损知识编辑。跨多个语言模型的实验表明,知识叠加是普遍存在的,表现出高峰度、零均值和具有清晰缩放规律的重尾分布。最终,通过结合理论和实验,我们证明了知识叠加是终身编辑失败的根本原因。此外,这是第一个从叠加的角度研究知识编辑的研究,并提供了对众多真实世界语言模型中叠加的全面观察。
🔬 方法详解
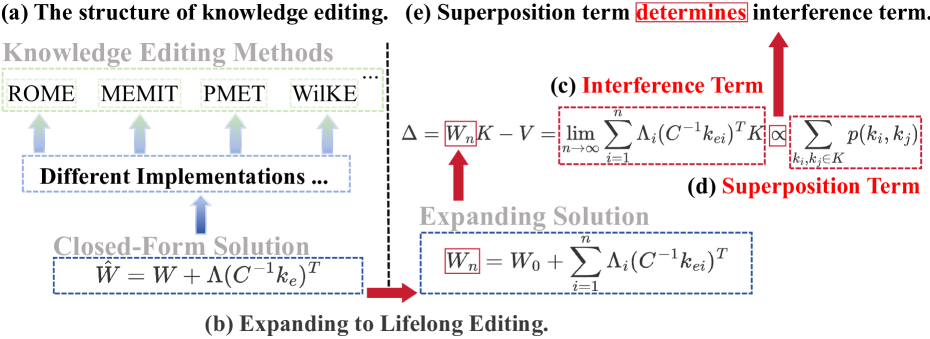
问题定义:论文旨在解决大语言模型在终身知识编辑中遇到的困难。现有知识编辑方法在单次编辑中表现良好,但在持续更新知识时会产生干扰,导致性能下降。痛点在于无法保证编辑后的知识不影响模型中其他知识的准确性,即缺乏可扩展性。
核心思路:论文的核心思路是分析知识编辑过程中的干扰项,并将其与知识表示的叠加联系起来。通过数学推导,证明了知识叠加是导致干扰产生的根本原因。如果知识表示之间没有叠加,则可以实现无损的知识编辑。因此,降低知识叠加程度可能有助于提升终身知识编辑的效果。
技术框架:论文的技术框架主要包括以下几个部分:1) 基于线性联想记忆的知识编辑方法的形式化描述;2) 将单次编辑的解扩展到终身编辑的场景;3) 通过数学推导,识别出终身编辑解中的干扰项;4) 分析干扰项与知识叠加之间的关系;5) 通过实验验证知识叠加在多种语言模型中的普遍性及其统计特性。
关键创新:论文最重要的技术创新点在于将知识编辑的失败归因于知识叠加现象,并从理论上证明了知识叠加是导致终身编辑中知识干扰的根本原因。这是首次从知识叠加的角度来分析知识编辑问题,为解决终身知识编辑的挑战提供了新的视角。
关键设计:论文的关键设计包括:1) 使用线性联想记忆作为知识编辑的基础模型,便于进行数学推导;2) 通过计算知识表示的峰度、均值和分布来分析知识叠加的程度;3) 在多个真实世界的语言模型上进行实验,验证理论分析的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,知识叠加在多种语言模型中普遍存在,并且表现出高峰度、零均值和具有清晰缩放规律的重尾分布。这些统计特性为理解知识叠加提供了重要的线索。论文通过实验验证了知识叠加与终身知识编辑性能之间的关系,为未来的研究提供了坚实的实验基础。
🎯 应用场景
该研究成果可应用于提升大语言模型的持续学习能力,使其能够不断更新知识,适应快速变化的世界。潜在应用领域包括智能客服、知识图谱更新、机器翻译等,有助于构建更加可靠和可信赖的AI系统。未来的研究方向可能包括设计减少知识叠加的训练方法,从而提高终身知识编辑的性能。
📄 摘要(原文)
Knowledge editing aims to update outdated or incorrect knowledge in large language models (LLMs). However, current knowledge editing methods have limited scalability for lifelong editing. This study explores the fundamental reason why knowledge editing fails in lifelong editing. We begin with the closed-form solution derived from linear associative memory, which underpins state-of-the-art knowledge editing methods. We extend the solution from single editing to lifelong editing, and through rigorous mathematical derivation, identify an interference term in the final solution, suggesting that editing knowledge may impact irrelevant knowledge. Further analysis of the interference term reveals a close relationship with superposition between knowledge representations. When knowledge superposition does not exist in language models, the interference term vanishes, allowing for lossless knowledge editing. Experiments across numerous language models reveal that knowledge superposition is universal, exhibiting high kurtosis, zero mean, and heavy-tailed distributions with clear scaling laws. Ultimately, by combining theory and experiments, we demonstrate that knowledge superposition is the fundamental reason for the failure of lifelong editing. Moreover, this is the first study to investigate knowledge editing from the perspective of superposition and provides a comprehensive observation of superposition across numerous real-world language models. Code available at https://github.com/ChenhuiHu/knowledge_in_superposition.