Re-TASK: Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
作者: Zhihu Wang, Shiwan Zhao, Yu Wang, Heyuan Huang, Sitao Xie, Yubo Zhang, Jiaxin Shi, Zhixing Wang, Hongyan Li, Junchi Yan
分类: cs.CL
发布日期: 2024-08-13 (更新: 2025-06-19)
备注: ACL 2025 Findings; First three authors contributed equally
🔗 代码/项目: GITHUB
💡 一句话要点
Re-TASK框架通过能力、技能和知识视角,提升LLM在特定领域任务中的表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 领域知识 任务分解 能力建模 知识注入 技能适应 Chain-of-Thought Chain-of-Learning
📋 核心要点
- 现有CoT方法在特定领域任务中表现不佳,主要原因是LLM无法准确分解任务或有效执行子任务。
- Re-TASK框架从能力、技能和知识三个维度重新审视LLM任务,并提出Chain-of-Learning (CoL)范式。
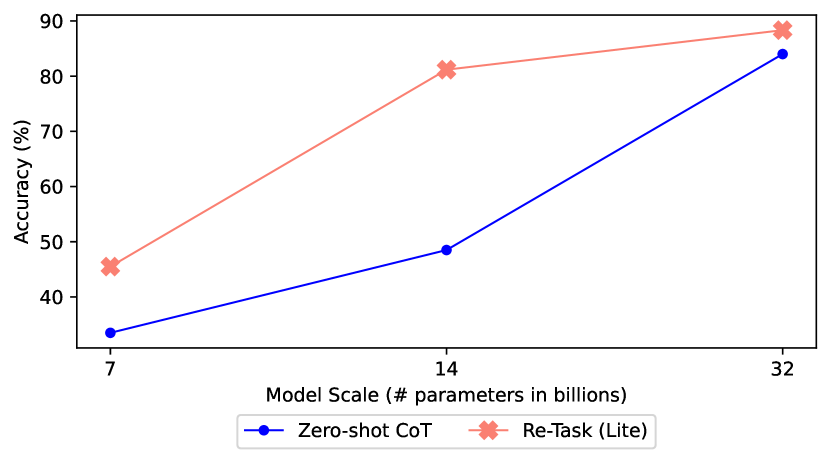
- Re-TASK提示策略通过知识注入和技能适应,显著提升了LLM在法律等领域的任务性能,最高提升达45%。
📝 摘要(中文)
Chain-of-Thought (CoT)已成为大型语言模型(LLM)解决复杂问题的关键方法。然而,由于LLM常常无法准确分解任务或有效执行子任务,其在特定领域任务中的应用仍然具有挑战性。本文提出了Re-TASK框架,这是一个新颖的理论模型,它从能力、技能和知识的角度重新审视LLM任务,借鉴了布鲁姆分类学和知识空间理论的原则。CoT提供了一个以工作流程为中心的任务视角,而Re-TASK引入了Chain-of-Learning (CoL)范式,强调任务对特定能力项的依赖性,并进一步分解为构成知识和技能组成部分。为了解决CoT的失败,我们提出了一种Re-TASK提示策略,通过有针对性的知识注入和技能适应来加强任务相关能力。在不同领域的实验证明了Re-TASK的有效性。特别是在法律任务上,Yi-1.5-9B模型提升了45.00%,Llama3-Chinese-8B模型提升了24.50%。这些结果突出了Re-TASK在显著提高LLM性能及其在专业领域中的适用性的潜力。我们在https://github.com/Uylee/Re-TASK发布了我们的代码和数据。
🔬 方法详解
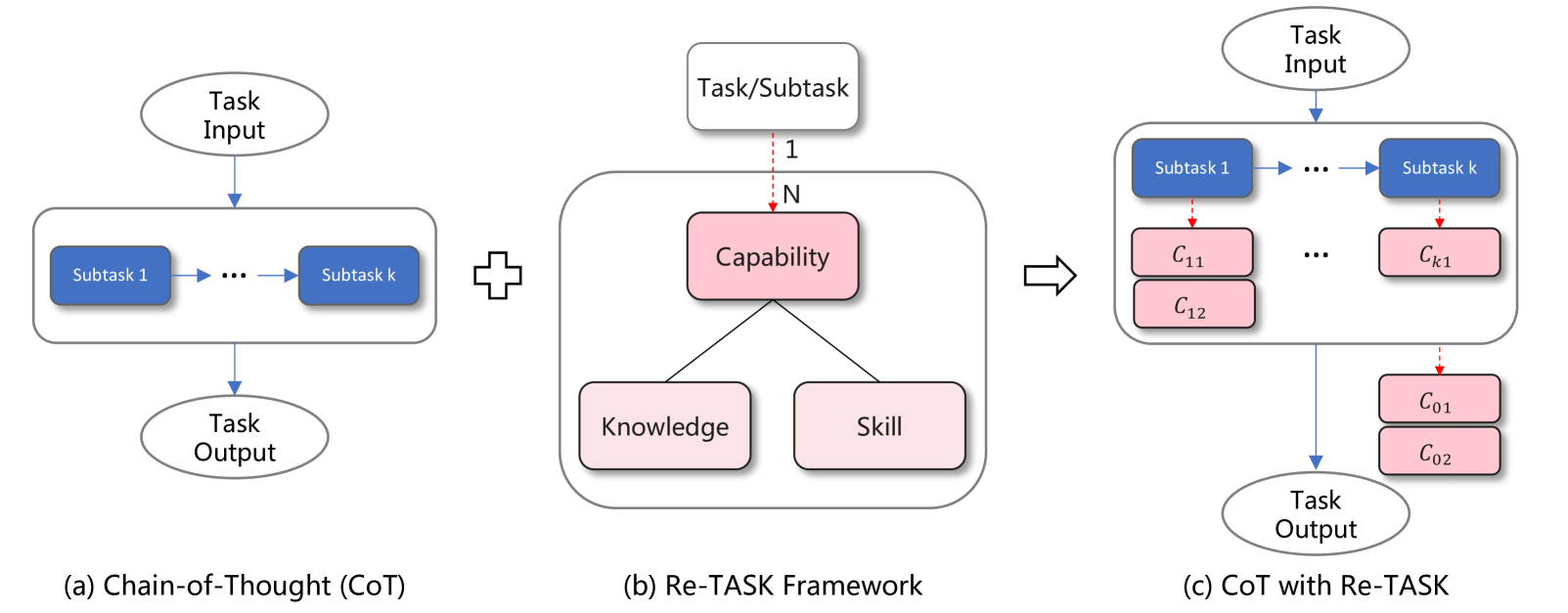
问题定义:现有的大型语言模型(LLM)在处理特定领域的复杂任务时,即使采用Chain-of-Thought (CoT) 方法,仍然面临挑战。主要痛点在于LLM难以准确地将任务分解为合适的子任务,并且在执行这些子任务时效率低下,导致最终结果不尽如人意。这通常是由于LLM缺乏特定领域所需的知识和技能,或者无法有效地利用已有的知识和技能。
核心思路:Re-TASK的核心思路是将LLM的任务分解为能力、技能和知识三个层次。借鉴布鲁姆分类学和知识空间理论,认为一个复杂任务的完成依赖于一系列能力,而每个能力又由具体的知识和技能构成。通过显式地建模这些依赖关系,Re-TASK旨在帮助LLM更好地理解任务需求,并针对性地提升相关能力。
技术框架:Re-TASK引入了Chain-of-Learning (CoL) 范式,作为对CoT的补充。CoL强调任务对特定能力项的依赖性,并将这些能力进一步分解为知识和技能组成部分。整体流程包括:1) 任务分解:将复杂任务分解为能力项;2) 知识注入:针对每个能力项,注入相关的知识;3) 技能适应:调整LLM的技能,使其更好地利用知识;4) 任务执行:利用增强后的LLM执行任务。
关键创新:Re-TASK最重要的创新在于其理论模型,它将LLM任务分解为能力、技能和知识三个层次,并提出了Chain-of-Learning (CoL) 范式。与传统的CoT方法相比,Re-TASK更加关注任务背后的能力需求,并通过知识注入和技能适应来增强LLM的能力。这种方法能够更有效地解决LLM在特定领域任务中遇到的问题。
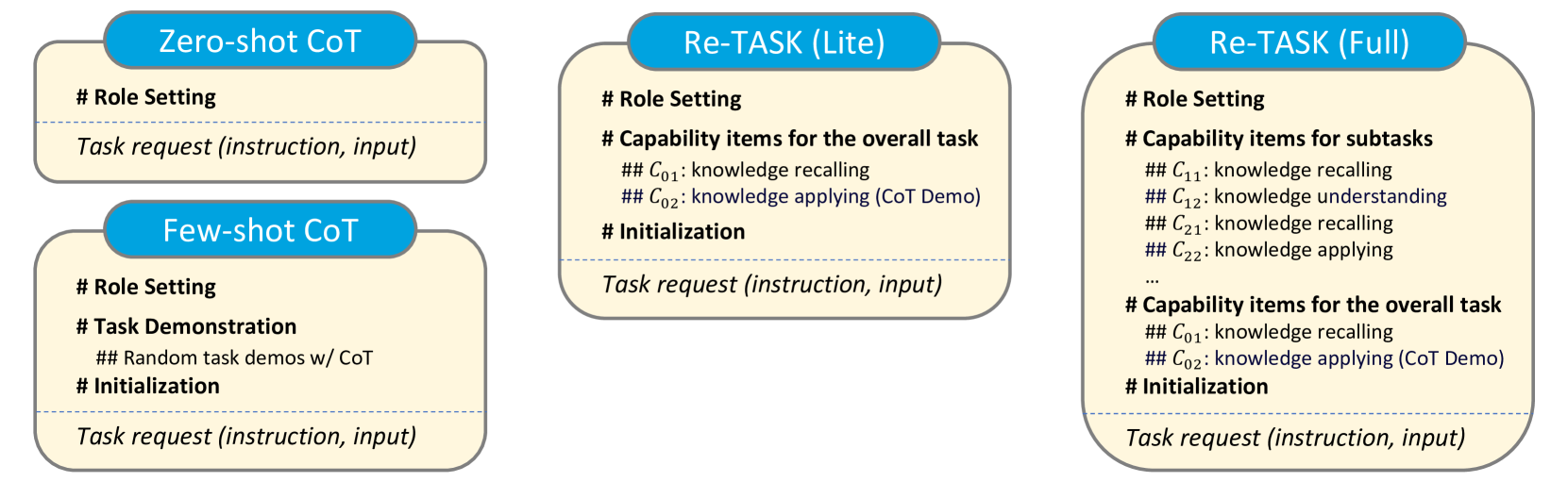
关键设计:Re-TASK提示策略是实现知识注入和技能适应的关键。具体来说,该策略包括:1) 知识提示:向LLM提供与任务相关的知识,例如法律条文、医学知识等;2) 技能提示:引导LLM使用特定的技能来解决问题,例如推理、分析、总结等。具体的提示模板和参数设置需要根据不同的任务和LLM进行调整。论文中没有详细描述损失函数或网络结构,因为Re-TASK主要是一种提示策略,而不是一种新的模型架构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Re-TASK框架在多个领域都取得了显著的性能提升。特别是在法律任务上,使用Re-TASK后,Yi-1.5-9B模型的性能提升了45.00%,Llama3-Chinese-8B模型的性能提升了24.50%。这些结果表明,Re-TASK能够有效地提高LLM在特定领域任务中的表现,具有很强的实用价值。
🎯 应用场景
Re-TASK框架具有广泛的应用前景,尤其是在需要专业知识的领域,如法律、医疗、金融等。它可以帮助LLM更好地理解和解决这些领域的复杂问题,提高工作效率和准确性。未来,Re-TASK可以应用于智能客服、法律咨询、医疗诊断等场景,为各行各业提供更智能、更专业的服务。
📄 摘要(原文)
The Chain-of-Thought (CoT) paradigm has become a pivotal method for solving complex problems with large language models (LLMs). However, its application to domain-specific tasks remains challenging, as LLMs often fail to decompose tasks accurately or execute subtasks effectively. This paper introduces the Re-TASK framework, a novel theoretical model that revisits LLM tasks from capability, skill, and knowledge perspectives, drawing on the principles of Bloom's Taxonomy and Knowledge Space Theory. While CoT provides a workflow-centric perspective on tasks, Re-TASK introduces a Chain-of-Learning (CoL) paradigm that highlights task dependencies on specific capability items, further broken down into their constituent knowledge and skill components. To address CoT failures, we propose a Re-TASK prompting strategy, which strengthens task-relevant capabilities through targeted knowledge injection and skill adaptation. Experiments across diverse domains demonstrate the effectiveness of Re-TASK. In particular, we achieve improvements of 45.00% on Yi-1.5-9B and 24.50% on Llama3-Chinese-8B for legal tasks. These results highlight the potential of Re-TASK to significantly enhance LLM performance and its applicability in specialized domains. We release our code and data at https://github.com/Uylee/Re-TASK.