Bridging LLMs and KGs without Fine-Tuning: Intermediate Probing Meets Subgraph-Aware Entity Descriptions
作者: Bo Xue, Yi Xu, Yunchong Song, Jiaxin Ding, Luoyi Fu, Xinbing Wang
分类: cs.CL
发布日期: 2024-08-13 (更新: 2025-08-05)
💡 一句话要点
提出基于中间层探查和子图感知实体描述的框架,无需微调即可桥接LLM与KG,实现高效知识图谱补全。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱补全 大型语言模型 中间层探查 子图抽样 实体描述 数据高效学习 关系抽取
📋 核心要点
- 现有知识图谱补全方法受限于知识图谱的稀疏性,而直接微调大型语言模型进行补全则带来巨大的计算开销。
- 该论文提出一种新框架,通过提取LLM中间层的上下文感知隐藏状态,并结合子图抽样生成的实体描述,实现高效的知识图谱补全。
- 实验结果表明,该方法在性能上可与微调LLM媲美,同时显著提升了GPU内存效率和训练/推理速度。
📝 摘要(中文)
传统的知识图谱补全(KGC)方法仅依赖于结构信息,难以应对知识图谱的固有稀疏性。相比之下,大型语言模型(LLM)封装了广泛的世界知识并展现出强大的上下文建模能力,使其有望缓解传统方法的局限性。然而,直接微调LLM进行KGC虽然有效,但会带来巨大的计算和内存开销,而使用非微调LLM虽然高效,但性能欠佳。本文提出了一种新颖的框架,该框架将LLM的优势与强大的知识表示相结合,以实现有效且高效的KGC。我们从LLM的中间层提取知识三元组的上下文感知隐藏状态,从而捕获丰富的语义和关系细微差别。然后,这些表示被用于训练专门为KGC任务量身定制的数据高效分类器。为了弥合LLM和KG之间的语义差距,我们在KG上采用子图抽样来生成模型友好的实体描述。我们进一步采用切片互信息(SMI)作为一种原则性度量,以量化这些表示中编码的特定于任务的信息。在标准基准上的大量实验验证了我们方法的效率和有效性。与之前基于非微调LLM的方法相比,我们实现了47%的相对改进,并且据我们所知,我们是第一个实现与微调LLM相当的分类性能,同时将GPU内存效率提高188倍,并将训练和推理速度提高26.11倍。
🔬 方法详解
问题定义:知识图谱补全任务旨在预测知识图谱中缺失的关系三元组。现有方法主要依赖于知识图谱的结构信息,难以处理知识图谱的稀疏性问题。直接微调大型语言模型(LLM)虽然可以提升补全效果,但计算和内存开销巨大,限制了其应用。
核心思路:该论文的核心思路是利用预训练LLM的知识和推理能力,同时避免直接微调带来的高昂成本。通过提取LLM中间层的隐藏状态,获取知识三元组的上下文信息,并结合子图感知的实体描述,弥合LLM和知识图谱之间的语义鸿沟。这样既能利用LLM的优势,又能保持计算效率。
技术框架:该框架主要包含以下几个阶段: 1. LLM中间层探查:输入知识三元组,提取LLM中间层的隐藏状态,作为知识表示。 2. 子图感知实体描述生成:对知识图谱进行子图抽样,生成模型友好的实体描述,用于增强实体表示。 3. 数据高效分类器训练:利用提取的隐藏状态和实体描述,训练一个轻量级的分类器,用于预测关系类型。 4. 切片互信息(SMI)评估:使用SMI作为指标,评估隐藏状态中编码的特定于任务的信息量。
关键创新:该论文的关键创新在于: 1. 中间层探查:通过提取LLM中间层的隐藏状态,获取知识三元组的上下文信息,避免了直接微调LLM。 2. 子图感知实体描述:利用子图抽样生成模型友好的实体描述,弥合了LLM和知识图谱之间的语义鸿沟。 3. 高效的分类器训练:使用数据高效的分类器,降低了计算成本。
关键设计: 1. 中间层选择:选择哪个中间层进行探查,需要根据具体任务进行调整。 2. 子图抽样策略:子图抽样的规模和策略会影响实体描述的质量。 3. 分类器结构:分类器的结构需要根据任务的复杂程度进行设计。 4. 损失函数:使用交叉熵损失函数训练分类器。
🖼️ 关键图片
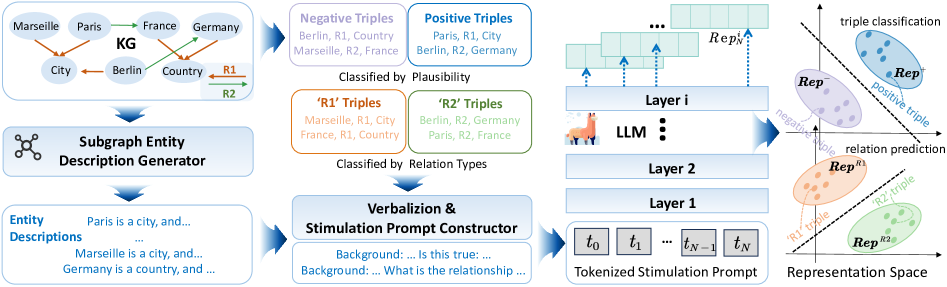


📊 实验亮点
实验结果表明,该方法在知识图谱补全任务上取得了显著的性能提升,相对于之前基于非微调LLM的方法,实现了47%的相对改进。更重要的是,该方法在达到与微调LLM相当的分类性能的同时,将GPU内存效率提高了188倍,并将训练和推理速度提高了26.11倍,展现了其高效性。
🎯 应用场景
该研究成果可应用于知识图谱补全、关系抽取、问答系统等领域。通过高效利用大型语言模型的知识,可以提升知识图谱的完整性和准确性,从而改善下游应用的性能。该方法在计算资源受限的场景下具有重要价值,例如移动设备或边缘计算环境。
📄 摘要(原文)
Traditional knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). By contrast, Large Language Models (LLMs) encapsulate extensive world knowledge and exhibit powerful context modeling capabilities, making them promising for mitigating the limitations of traditional methods. However, direct fine-tuning of LLMs for KGC, though effective, imposes substantial computational and memory overheads, while utilizing non-fine-tuned LLMs is efficient but yields suboptimal performance. In this work, we propose a novel framework that synergizes the strengths of LLMs with robust knowledge representation to enable effective and efficient KGC. We extract the context-aware hidden states of knowledge triples from the intermediate layers of LLMs, thereby capturing rich semantic and relational nuances. These representations are then utilized to train a data-efficient classifier tailored specifically for KGC tasks. To bridge the semantic gaps between LLMs and KGs, we employ subgraph sampling on KGs to generate model-friendly entity descriptions. We further adopt sliced mutual information (SMI) as a principled metric to quantify the task-specific information encoded in these representations. Extensive experiments on standard benchmarks validate the efficiency and effectiveness of our approach. We achieve a 47\% relative improvement over previous methods based on non-fine-tuned LLMs and, to our knowledge, are the first to achieve classification performance comparable to fine-tuned LLMs while enhancing GPU memory efficiency by $188\times$ and accelerating training and inference by $26.11\times$.