Social Debiasing for Fair Multi-modal LLMs
作者: Harry Cheng, Yangyang Guo, Qingpei Guo, Ming Yang, Tian Gan, Weili Guan, Liqiang Nie
分类: cs.CL, cs.AI
发布日期: 2024-08-13 (更新: 2025-08-20)
备注: Project page: https://github.com/xaCheng1996/Social_Debiasing_For_Fair_MLLMs
💡 一句话要点
提出CMSC数据集与CSD策略,解决多模态大语言模型中的社会偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 社会偏见 反事实数据集 反刻板印象 数据去偏见
📋 核心要点
- 现有的多模态大语言模型存在社会偏见,在涉及种族、性别等敏感属性时可能产生不当回应,亟需有效缓解。
- 论文提出反刻板印象去偏见(CSD)策略,通过利用刻板印象的对立面,结合偏见感知采样和损失重缩放来减少偏见。
- 实验结果表明,提出的CMSC数据集和CSD策略能有效减少社会偏见,同时保持模型在通用多模态推理任务上的性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)显著推动了研究领域的发展,并提供了强大的视觉-语言理解能力。然而,这些模型通常会从训练数据中继承根深蒂固的社会偏见,导致在种族和性别等属性方面产生令人不适的回应。本文通过以下方式解决了MLLM中的社会偏见问题:i) 引入了一个包含多个社会概念的综合反事实数据集(CMSC),该数据集通过提供18个多样化且平衡的社会概念来补充现有数据集;ii) 提出了一种反刻板印象去偏见(CSD)策略,该策略通过利用流行刻板印象的对立面来减轻MLLM中的社会偏见。CSD结合了一种新颖的偏见感知数据采样方法和一种损失重缩放方法,使模型能够有效地减少偏见。我们使用四种流行的MLLM架构进行了广泛的实验。结果表明,与现有的竞争方法相比,CMSC数据集和CSD策略在减少社会偏见方面具有优势,且不会影响通用多模态推理基准上的整体性能。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)在视觉-语言理解方面表现出色,但它们从训练数据中继承了社会偏见,导致在涉及种族、性别等敏感属性时产生不公平或不适当的响应。现有方法在数据集覆盖度和去偏见策略上存在局限性,难以有效缓解这些偏见。
核心思路:论文的核心思路是利用反刻板印象来对抗模型中存在的社会偏见。通过让模型接触与常见刻板印象相反的例子,模型可以学习到更公平、更平衡的表示,从而减少偏见。这种方法基于一个假设,即通过暴露于不同的视角和情境,模型可以更好地理解和处理社会概念。
技术框架:该方法包含两个主要组成部分:一是构建一个综合反事实数据集(CMSC),二是提出反刻板印象去偏见(CSD)策略。CMSC数据集包含18个多样化且平衡的社会概念,用于训练和评估模型。CSD策略包括偏见感知数据采样和损失重缩放两个步骤。偏见感知数据采样旨在选择更具代表性的样本,而损失重缩放则调整不同样本的损失权重,以减少偏见的影响。
关键创新:该论文的关键创新在于:1) 提出了一个更全面、更平衡的社会概念数据集(CMSC),弥补了现有数据集的不足。2) 提出了反刻板印象去偏见(CSD)策略,该策略通过利用刻板印象的对立面来减轻社会偏见,是一种新颖有效的去偏见方法。3) 结合了偏见感知数据采样和损失重缩放,进一步提高了去偏见的效果。
关键设计:CMSC数据集的设计考虑了多个社会概念的平衡性和多样性,确保数据集能够覆盖各种不同的偏见类型。偏见感知数据采样方法根据样本的偏见程度进行采样,优先选择更具挑战性的样本。损失重缩放方法根据样本的偏见程度调整损失权重,降低偏见样本的损失权重,从而减少偏见的影响。具体的损失函数和网络结构细节在论文中进行了详细描述,但此处未知。
🖼️ 关键图片
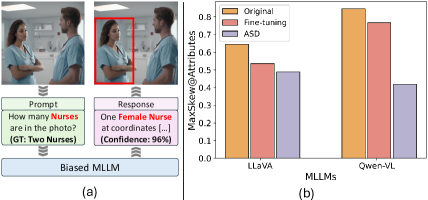
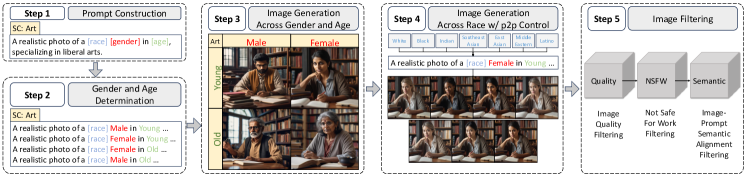
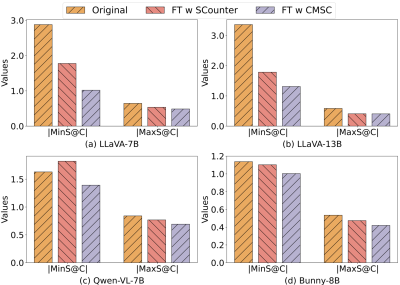
📊 实验亮点
实验结果表明,提出的CMSC数据集和CSD策略在减少社会偏见方面优于现有的竞争方法。在四个流行的MLLM架构上进行了广泛的实验,证明了该方法的有效性。重要的是,该方法在减少社会偏见的同时,没有显著降低模型在通用多模态推理基准上的性能。
🎯 应用场景
该研究成果可应用于各种需要公平性和避免社会偏见的场景,例如招聘系统、贷款审批、内容审核等。通过减少多模态大语言模型中的社会偏见,可以提高这些系统的公平性和可靠性,避免歧视性结果,并促进更公正的社会。
📄 摘要(原文)
Multi-modal Large Language Models (MLLMs) have dramatically advanced the research field and delivered powerful vision-language understanding capabilities. However, these models often inherit deep-rooted social biases from their training data, leading to uncomfortable responses with respect to attributes such as race and gender. This paper addresses the issue of social biases in MLLMs by i) introducing a comprehensive counterfactual dataset with multiple social concepts (CMSC), which complements existing datasets by providing 18 diverse and balanced social concepts; and ii) proposing a counter-stereotype debiasing (CSD) strategy that mitigates social biases in MLLMs by leveraging the opposites of prevalent stereotypes. CSD incorporates both a novel bias-aware data sampling method and a loss rescaling method, enabling the model to effectively reduce biases. We conduct extensive experiments with four prevalent MLLM architectures. The results demonstrate the advantage of the CMSC dataset and the edge of CSD strategy in reducing social biases compared to existing competing methods, without compromising the overall performance on general multi-modal reasoning benchmarks.