AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
作者: Bo-Wen Zhang, Liangdong Wang, Ye Yuan, Jijie Li, Shuhao Gu, Mengdi Zhao, Xinya Wu, Guang Liu, Chengwei Wu, Hanyu Zhao, Li Du, Yiming Ju, Quanyue Ma, Yulong Ao, Yingli Zhao, Songhe Zhu, Zhou Cao, Dong Liang, Yonghua Lin, Ming Zhang, Shunfei Wang, Yanxin Zhou, Min Ye, Xuekai Chen, Xinyang Yu, Xiangjun Huang, Jian Yang
分类: cs.CL, cs.AI
发布日期: 2024-08-13
💡 一句话要点
AquilaMoE:通过Scale-Up和Scale-Out策略高效训练MoE模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 知识迁移 高效训练 大规模语言模型
📋 核心要点
- 大规模语言模型训练成本高昂,从头训练耗费大量计算资源,而从小模型扩展是一种更有效的方法。
- AquilaMoE采用EfficientScale训练方法,通过Scale-Up和Scale-Out两阶段策略,最小化数据需求并优化模型性能。
- 实验表明,该方法在1.8B、7B和16B模型上均取得了显著的性能提升和训练效率的提高,最终成功训练了8*16B AquilaMoE模型。
📝 摘要(中文)
本文提出了AquilaMoE,一个先进的双语816B混合专家(MoE)语言模型,该模型包含8个专家,每个专家有160亿参数,并采用了一种名为EfficientScale的创新训练方法。该方法通过一个两阶段过程优化性能,同时最小化数据需求。第一阶段,称为Scale-Up,使用预训练的小型模型的权重初始化更大的模型,从而实现大量的知识迁移和使用显著更少的数据进行持续预训练。第二阶段,Scale-Out,使用预训练的稠密模型来初始化MoE专家,进一步增强知识迁移和性能。在1.8B和7B模型上进行的广泛验证实验比较了各种初始化方案,实现了在持续预训练期间保持和减少损失的模型。利用最优方案,我们成功训练了一个16B模型,随后训练了816B AquilaMoE模型,证明了性能和训练效率的显著提高。
🔬 方法详解
问题定义:论文旨在解决大规模混合专家模型(MoE)训练过程中计算资源需求高、数据依赖性强的问题。现有方法通常需要大量的计算资源和数据才能从头训练MoE模型,这限制了MoE模型的发展和应用。
核心思路:论文的核心思路是通过知识迁移来降低MoE模型的训练成本和数据需求。具体来说,论文提出了EfficientScale训练方法,该方法包含Scale-Up和Scale-Out两个阶段,分别利用预训练的小型稠密模型和大型稠密模型来初始化MoE模型的参数,从而实现知识的有效迁移。
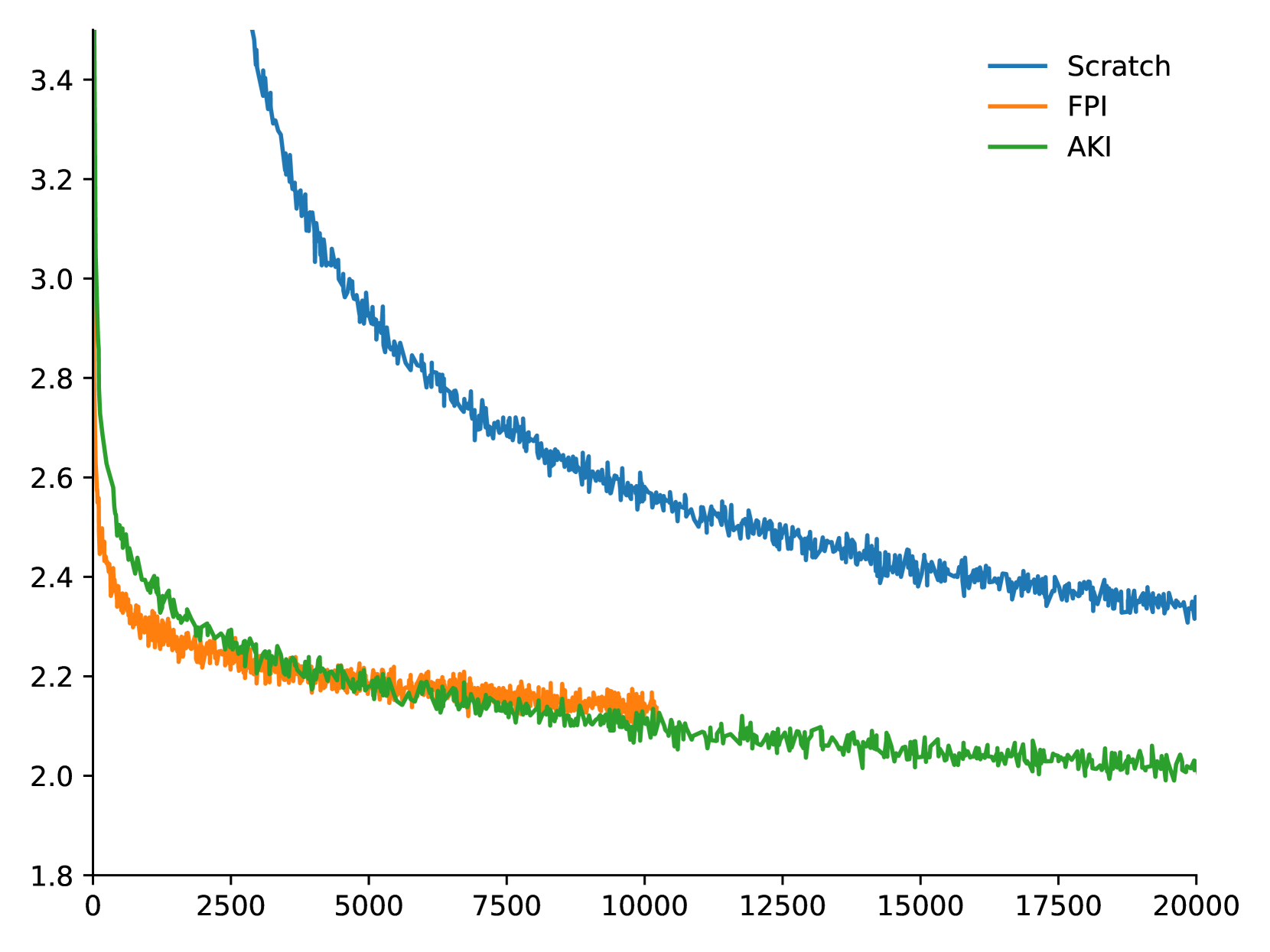
技术框架:AquilaMoE的训练过程分为两个主要阶段:Scale-Up和Scale-Out。在Scale-Up阶段,使用预训练的小型稠密模型初始化大型MoE模型的共享参数,并进行持续预训练。在Scale-Out阶段,使用预训练的大型稠密模型初始化MoE模型的专家参数,并进行微调。整个训练过程旨在利用知识迁移来加速MoE模型的训练,并降低对大量数据的依赖。
关键创新:该方法最重要的创新点在于提出了一个两阶段的知识迁移框架,即Scale-Up和Scale-Out,有效地利用了预训练的稠密模型来初始化MoE模型的参数。与传统的从头训练MoE模型的方法相比,该方法显著降低了计算资源和数据需求,并提高了训练效率。
关键设计:在Scale-Up阶段,选择合适的预训练小型模型至关重要,需要考虑模型大小、架构和训练数据等因素。在Scale-Out阶段,专家模型的初始化策略也需要仔细设计,以确保知识的有效迁移。此外,损失函数的设计也需要考虑MoE模型的特殊性,例如,可以使用辅助损失来平衡各个专家的负载。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了EfficientScale训练方法的有效性。在1.8B和7B模型上,该方法能够保持甚至降低损失。最终,成功训练了一个8*16B AquilaMoE模型,并在性能和训练效率上取得了显著提升。这些结果表明,该方法是训练大规模MoE模型的一种有效途径。
🎯 应用场景
AquilaMoE的潜在应用领域包括自然语言处理、机器翻译、文本生成、对话系统等。该研究的实际价值在于降低了大规模语言模型的训练成本,使得更多研究者和开发者能够训练和应用MoE模型。未来,AquilaMoE有望推动人工智能技术在各个领域的广泛应用。
📄 摘要(原文)
In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 816B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 816B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.