Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
作者: Yingjin Song, Denis Paperno, Albert Gatt
分类: cs.CL, cs.CV
发布日期: 2024-08-12
备注: 18 pages, 12 figures, accepted by INLG 2024
💡 一句话要点
提出基于视觉前缀调优和对比学习的上下文感知视觉故事生成框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉故事生成 视觉前缀调优 对比学习 多模态学习 预训练模型
📋 核心要点
- 视觉故事生成面临上下文信息缺失和视觉内容变化带来的挑战,现有方法难以保证故事的连贯性和信息量。
- 论文提出一种轻量级视觉-语言映射网络,结合视觉前缀调优和上下文信息,利用预训练模型生成连贯的故事。
- 实验结果表明,该框架生成的故事在多样性、连贯性、信息性和趣味性方面均优于现有方法。
📝 摘要(中文)
本文提出了一种视觉故事生成系统,该系统能够从图像序列中生成多句故事。该任务的关键挑战在于捕获上下文信息和弥合视觉变化。我们提出了一个简单而有效的框架,它利用了预训练基础模型的泛化能力,仅训练一个轻量级的视觉-语言映射网络来连接模态,同时结合上下文来增强连贯性。此外,我们引入了一种多模态对比目标,以提高视觉相关性和故事的信息量。大量的实验结果,包括自动指标和人工评估,表明我们的框架生成的故事具有多样性、连贯性、信息性和趣味性。
🔬 方法详解
问题定义:视觉故事生成任务旨在根据一系列图像生成一段连贯且信息丰富的故事。现有方法通常难以有效地捕捉图像序列中的上下文信息,并且在处理视觉内容变化时容易产生不连贯或信息量不足的故事。因此,如何提高生成故事的连贯性和信息量是该任务的关键挑战。
核心思路:本文的核心思路是利用预训练基础模型的强大泛化能力,并在此基础上进行轻量级的视觉-语言映射。通过视觉前缀调优,将视觉信息有效地融入到预训练语言模型中。同时,引入上下文信息来增强故事的连贯性。此外,采用多模态对比学习目标,鼓励模型学习视觉和语言之间的对应关系,从而提高故事的视觉相关性和信息量。
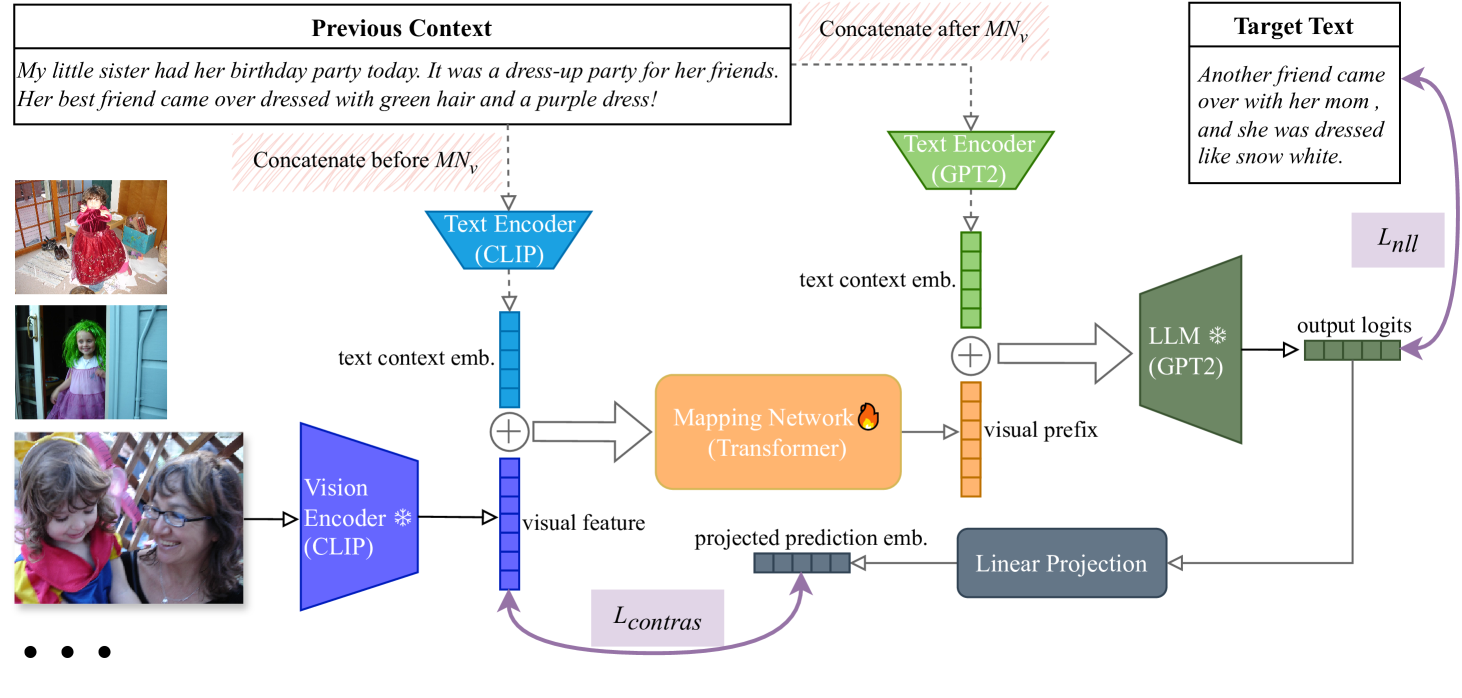
技术框架:该框架主要包含三个模块:视觉编码器、视觉-语言映射网络和语言解码器。视觉编码器负责提取图像序列的视觉特征。视觉-语言映射网络将视觉特征映射到语言模型的输入空间,并通过视觉前缀调优将视觉信息融入到语言模型中。语言解码器则根据融合了视觉信息的语言模型生成故事。
关键创新:该论文的关键创新在于以下几个方面:1) 提出了一种轻量级的视觉-语言映射网络,避免了对整个预训练模型进行微调,从而降低了计算成本。2) 引入了视觉前缀调优,能够有效地将视觉信息融入到语言模型中。3) 提出了多模态对比学习目标,鼓励模型学习视觉和语言之间的对应关系,从而提高故事的视觉相关性和信息量。
关键设计:视觉前缀调优通过在语言模型的输入层添加可学习的视觉前缀来实现。多模态对比学习目标采用InfoNCE损失函数,鼓励模型将视觉上相似的图像和语义上相关的文本拉近,同时将视觉上不同的图像和语义上不相关的文本推远。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在自动指标和人工评估方面均取得了显著的提升。例如,在常用的故事生成指标BLEU、ROUGE和METEOR上,该框架均优于现有的基线方法。人工评估结果也表明,该框架生成的故事在连贯性、信息性和趣味性方面均优于现有方法,并且更具有视觉相关性。
🎯 应用场景
该研究成果可应用于多个领域,例如:自动化内容生成、教育娱乐、辅助写作等。例如,可以利用该技术自动生成儿童绘本故事,或者帮助作家进行故事创作。此外,该技术还可以应用于智能客服领域,根据用户上传的图片生成相应的对话内容。未来,该技术有望在人机交互、内容创作等领域发挥更大的作用。
📄 摘要(原文)
Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.