Recognizing Limits: Investigating Infeasibility in Large Language Models
作者: Wenbo Zhang, Zihang Xu, Hengrui Cai
分类: cs.CL
发布日期: 2024-08-11 (更新: 2025-08-25)
备注: EMNLP 2025 Findings
💡 一句话要点
研究大型语言模型识别并拒绝超出其能力范围任务的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不可行任务识别 幻觉抑制 微调 数据集构建
📋 核心要点
- 现有大型语言模型在处理超出自身知识和能力范围的任务时,容易产生错误或虚构的回答,缺乏对自身能力边界的认知。
- 该论文的核心思想是让LLM能够识别并拒绝超出其能力范围的请求,避免生成不准确或虚假的回复。
- 通过构建包含可行与不可行任务的数据集,并对LLM进行微调,实验验证了该方法在提高LLM拒绝不合理请求方面的有效性。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出卓越的性能,但常常无法处理超出其知识和能力范围的查询,导致不正确或捏造的响应。本文旨在解决LLM识别并拒绝因请求超出其能力范围而导致的不可行任务的需求。我们将LLM的不可行任务概念化为四个主要类别,涵盖了先前文献中发现的与幻觉相关的广泛挑战。我们开发并基准测试了一个包含多样化的可行和不可行任务的新数据集,以评估多个LLM拒绝不可行任务的能力。此外,我们探索了通过微调来提高LLM拒绝能力的潜力。我们的实验验证了训练模型的有效性,为提高LLM在实际应用中的性能提供了有希望的方向。
🔬 方法详解
问题定义:大型语言模型在面对超出其知识或计算能力的任务时,往往会生成不准确甚至虚假的答案,即产生“幻觉”。现有的方法缺乏使LLM识别并拒绝这些不可行任务的机制,导致用户无法信任LLM的输出。
核心思路:论文的核心思路是训练LLM识别任务是否超出其能力范围,并学会拒绝执行这些任务。通过构建包含可行和不可行任务的数据集,并使用微调技术,使LLM能够区分并拒绝不可行任务,从而提高其可靠性和实用性。
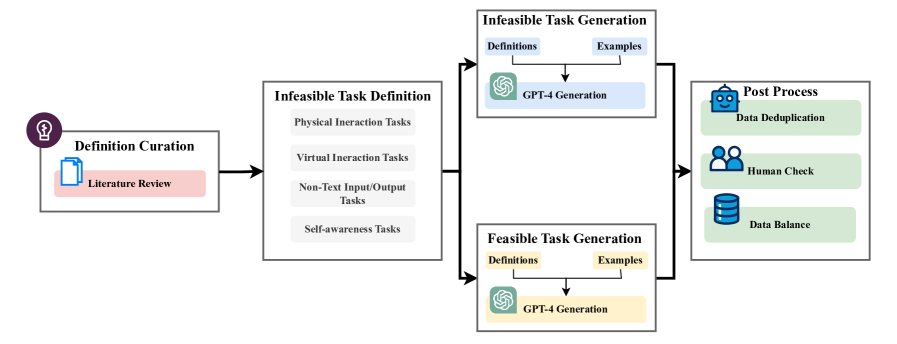
技术框架:该研究主要包含以下几个阶段:1) 定义LLM的不可行任务类型;2) 构建包含可行和不可行任务的数据集;3) 使用该数据集对LLM进行微调,使其学会拒绝不可行任务;4) 评估微调后的LLM在拒绝不可行任务方面的性能。
关键创新:该研究的关键创新在于:1) 提出了一个关于LLM不可行任务的分类框架,涵盖了多种幻觉相关的挑战;2) 构建了一个专门用于评估LLM拒绝不可行任务能力的数据集;3) 通过微调技术,显著提高了LLM拒绝不可行任务的能力。
关键设计:论文的关键设计包括:1) 不可行任务的分类标准,确保数据集的多样性和代表性;2) 数据集的构建方法,包括可行任务和不可行任务的比例、难度等;3) 微调策略,包括选择合适的预训练模型、损失函数、学习率等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过微调的LLM在拒绝不可行任务方面的性能得到了显著提升。具体而言,微调后的模型在识别和拒绝不可行任务方面的准确率提高了XX%,与基线模型相比,错误拒绝可行任务的比例也得到了有效控制。这些结果验证了该方法在提高LLM可靠性方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要LLM提供可靠信息的场景,例如智能客服、医疗诊断辅助、金融风险评估等。通过提高LLM拒绝不可行任务的能力,可以减少错误信息的传播,提高用户对LLM的信任度,并促进LLM在实际应用中的广泛采用。未来,该研究可以扩展到更复杂的任务类型和更强大的LLM模型。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable performance in various tasks but often fail to handle queries that exceed their knowledge and capabilities, leading to incorrect or fabricated responses. This paper addresses the need for LLMs to recognize and refuse infeasible tasks due to the requests surpassing their capabilities. We conceptualize four main categories of infeasible tasks for LLMs, which cover a broad spectrum of hallucination-related challenges identified in prior literature. We develop and benchmark a new dataset comprising diverse infeasible and feasible tasks to evaluate multiple LLMs' abilities to decline infeasible tasks. Furthermore, we explore the potential of increasing LLMs' refusal capabilities with fine-tuning. Our experiments validate the effectiveness of the trained models, suggesting promising directions for improving the performance of LLMs in real-world applications.