SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
作者: Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Hong Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, Yingda Chen
分类: cs.CL
发布日期: 2024-08-10 (更新: 2025-05-19)
💡 一句话要点
SWIFT:一个可扩展的轻量级大模型微调基础设施
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多模态学习 轻量级微调 开源框架 模型部署
📋 核心要点
- 现有LLM和MLLM微调缺乏统一易用的基础设施,阻碍了模型在不同任务上的快速部署。
- SWIFT提供了一个可定制的一站式框架,支持多种LLM和MLLM的微调、推理、评估和量化。
- 实验表明,使用SWIFT微调的Agent模型在ToolBench上取得了显著提升,Act.EM指标提升高达21.8%。
📝 摘要(中文)
大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的最新发展利用了基于注意力机制的Transformer架构,并取得了卓越的性能和泛化能力。它们已经覆盖了广泛的传统学习任务领域。例如,诸如文本分类和序列标注等基于文本的任务,以及诸如视觉问答(VQA)和光学字符识别(OCR)等多模态任务,以前使用不同的模型来解决,现在可以基于一个基础模型来处理。因此,LLM和MLLM的训练和轻量级微调,特别是那些基于Transformer架构的模型,变得尤为重要。为了满足这些需求,我们开发了SWIFT,这是一个可定制的大模型一站式基础设施。SWIFT支持超过300个LLM和50个MLLM,是为大型模型微调提供最全面支持的开源框架。特别是,它是第一个为MLLM提供系统支持的训练框架。除了微调的核心功能外,SWIFT还集成了推理、评估和模型量化等训练后流程,以促进大型模型在各种应用场景中的快速采用。通过系统地集成各种训练技术,SWIFT提供了有用的工具,例如大型模型不同训练技术之间的基准比较。对于专门用于Agent框架的微调模型,我们表明,通过在SWIFT上使用定制数据集进行训练,可以在ToolBench排行榜上取得显著的改进,在Act.EM指标上超过各种基线模型5.2%-21.8%,幻觉减少1.6%-14.1%,平均性能提高8%-17%。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的微调过程复杂且分散,缺乏一个统一的、易于使用的基础设施。这使得研究人员和开发者难以快速地将这些模型应用到各种下游任务中,并且难以比较不同微调技术的效果。
核心思路:SWIFT的核心思路是构建一个可扩展的、轻量级的、一站式的平台,该平台能够支持多种LLMs和MLLMs的微调、推理、评估和量化。通过集成各种训练技术和提供基准比较,SWIFT旨在简化大型模型的应用流程,并促进其在不同场景下的快速部署。
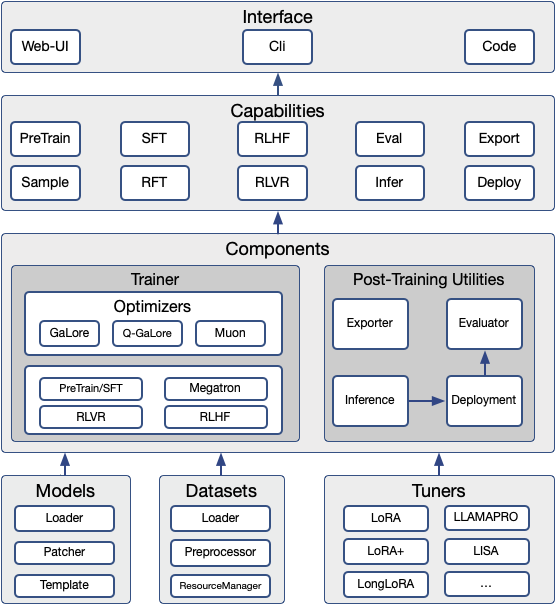
技术框架:SWIFT框架主要包含以下几个核心模块:模型支持模块(支持300+ LLMs和50+ MLLMs)、微调模块(提供多种微调技术)、推理模块、评估模块和模型量化模块。用户可以根据自己的需求选择不同的模块进行组合,从而实现定制化的模型训练和部署流程。框架还集成了各种训练技术,并提供基准比较功能,帮助用户选择最合适的训练策略。
关键创新:SWIFT的关键创新在于其对MLLMs的系统性支持,这是其他训练框架所不具备的。此外,SWIFT还提供了一站式的解决方案,涵盖了从微调到部署的整个流程,大大简化了大型模型的应用过程。框架的可定制性也使得用户可以根据自己的需求进行灵活配置。
关键设计:SWIFT的关键设计包括对各种微调技术的集成(例如,LoRA, Adapter等),以及对不同硬件平台的支持。框架还提供了丰富的API和命令行工具,方便用户进行模型训练和部署。在Agent模型的微调方面,SWIFT允许用户使用定制的数据集进行训练,从而提高模型在特定任务上的性能。
🖼️ 关键图片
📊 实验亮点
在Agent框架的微调实验中,使用SWIFT和定制数据集训练的模型在ToolBench排行榜上取得了显著提升,Act.EM指标提升了5.2%-21.8%,幻觉减少了1.6%-14.1%,平均性能提升了8%-17%。这些结果表明SWIFT在实际应用中具有显著的优势。
🎯 应用场景
SWIFT可广泛应用于各种需要大型语言模型和多模态大型语言模型的场景,例如智能客服、文本生成、视觉问答、光学字符识别等。它降低了大型模型微调和部署的门槛,加速了这些模型在实际应用中的落地,并促进了相关领域的发展。
📄 摘要(原文)
Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the most comprehensive support for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.