Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers
作者: MohammadReza Ebrahimi, Sunny Panchal, Roland Memisevic
分类: cs.CL
发布日期: 2024-08-10
备注: Published as a conference paper at COLM 2024
💡 一句话要点
揭示Transformer随机访问限制:Transformer无法有效处理上下文窗口内的随机记忆访问问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 长度泛化 随机访问 注意力机制 长序列建模
📋 核心要点
- Transformer模型在处理长序列时,长度泛化能力不足,无法有效处理超出训练长度的序列。
- 该研究认为,长度泛化失败的核心原因是Transformer无法在其上下文窗口内进行有效的随机内存访问。
- 通过实验验证,规避索引或使用基于内容的寻址可以间接实现随机token访问,从而提升模型性能。
📝 摘要(中文)
尽管基于Transformer的大型语言模型最近取得了成功,但它们也表现出令人惊讶的失效模式。一个众所周知的例子是它们无法进行长度泛化:即在推理时解决比训练期间看到的更长的问题实例。在这项工作中,我们通过对奇偶校验任务进行详细的模型行为分析,进一步探讨了这种失败的根本原因。我们的分析表明,长度泛化失败与模型无法在其上下文窗口内执行随机内存访问密切相关。我们通过证明规避索引需求或通过基于内容的寻址间接实现随机token访问的方法的有效性,来为这一假设提供支持。我们进一步展示了无法执行随机内存访问如何通过注意力图可视化来体现。
🔬 方法详解
问题定义:Transformer模型在处理长序列时,存在长度泛化问题,即在训练时使用较短的序列,而在推理时处理更长的序列时,性能会显著下降。现有的Transformer模型在处理长序列时,难以进行有效的随机内存访问,导致无法准确地提取和利用上下文信息。
核心思路:该论文的核心思路是,Transformer的长度泛化失败与模型无法在其上下文窗口内执行随机内存访问有关。通过分析模型在奇偶校验任务上的行为,发现模型难以通过索引的方式访问上下文中的任意位置的信息。
技术框架:该论文主要通过实验分析Transformer模型在奇偶校验任务上的表现,并结合注意力图可视化来验证其假设。具体来说,作者设计了一系列实验,旨在探究模型在不同长度的序列上的表现,以及模型在处理不同位置的token时的注意力分布。同时,作者还尝试了一些方法来规避索引需求或通过基于内容的寻址间接实现随机token访问,并观察这些方法对模型性能的影响。
关键创新:该论文最重要的技术创新点在于,它揭示了Transformer模型在处理长序列时存在的随机访问限制。以往的研究主要关注Transformer模型的计算复杂度和并行性,而忽略了模型在内存访问方面的限制。该论文通过实验证明,Transformer模型难以通过索引的方式访问上下文中的任意位置的信息,这导致模型在处理长序列时难以进行有效的推理。
关键设计:论文的关键设计在于实验的设计,通过奇偶校验任务来考察模型对序列中不同位置信息的利用能力。此外,论文还探索了基于内容的寻址方法,例如使用memory network等结构,来缓解随机访问的限制。具体的参数设置和网络结构细节在论文中可能没有详细描述,需要参考相关文献。
🖼️ 关键图片
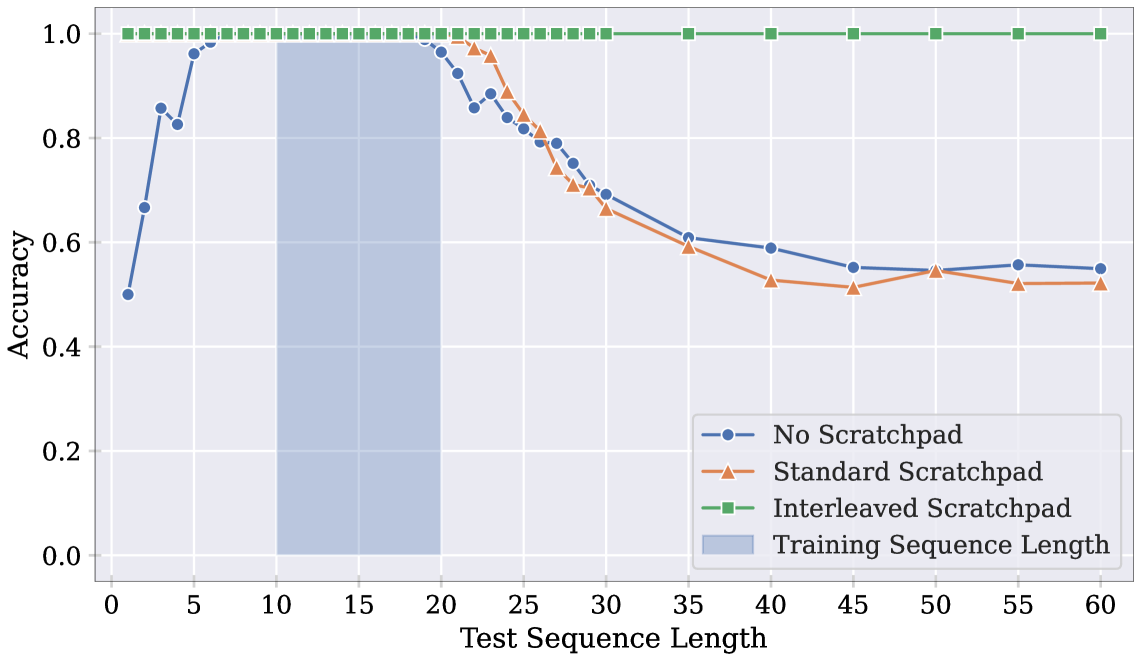
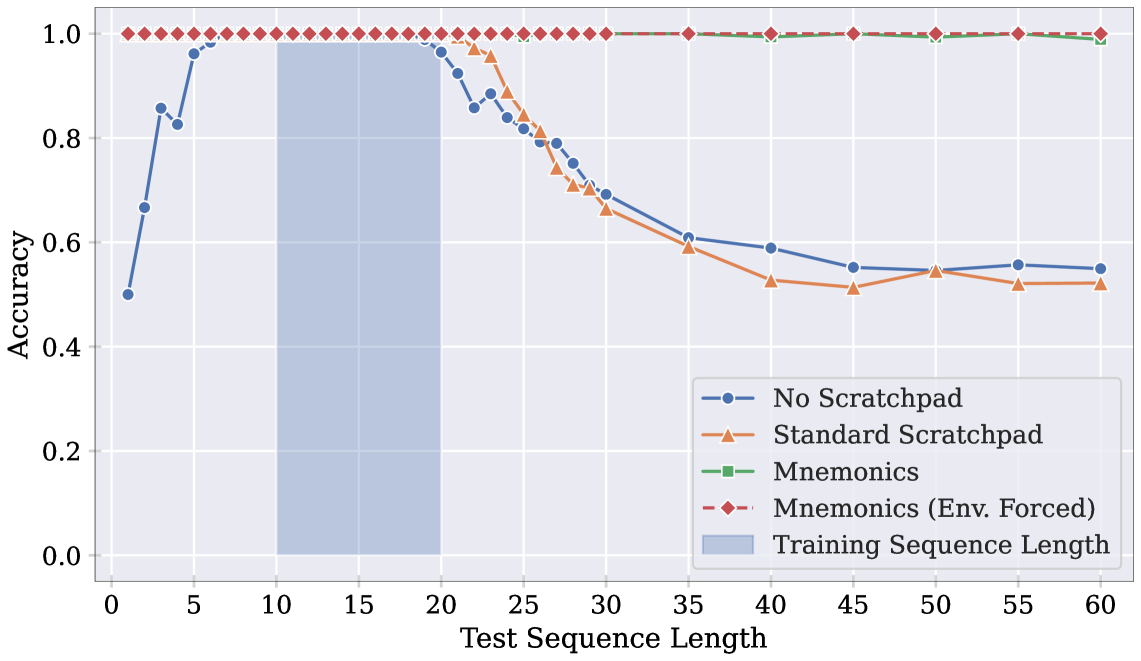
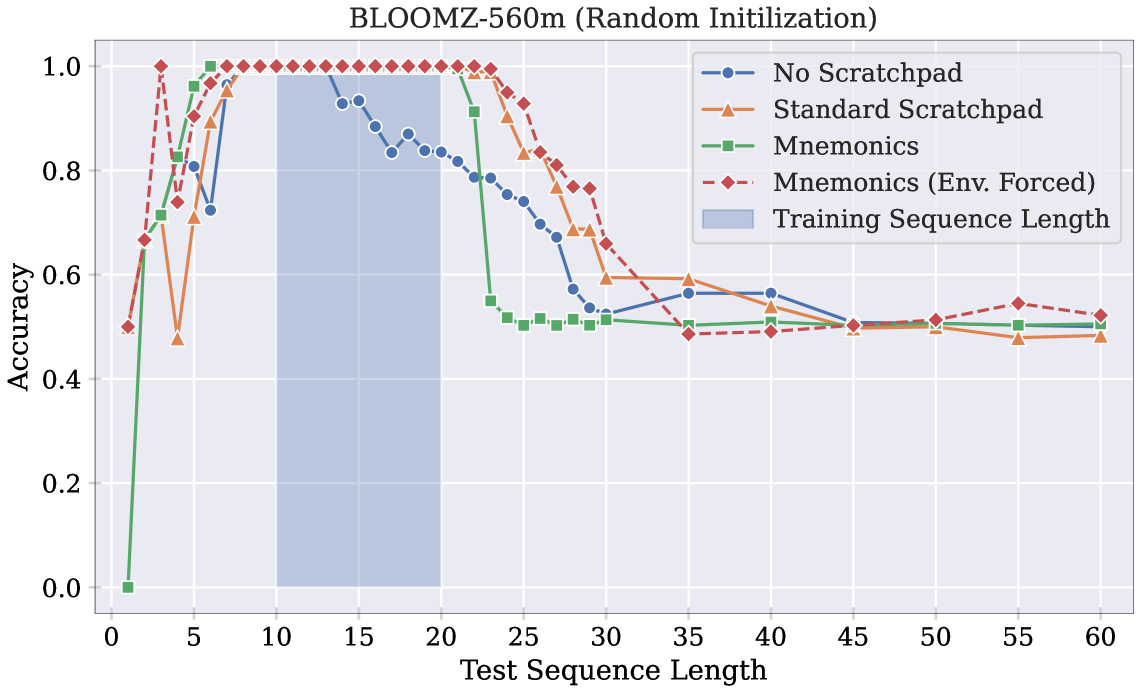
📊 实验亮点
该研究通过在奇偶校验任务上的实验,证明了Transformer模型在处理长序列时存在随机访问限制。实验结果表明,当序列长度超过训练长度时,模型的性能会显著下降。同时,通过引入基于内容的寻址机制,可以有效地缓解这一问题,并提升模型的泛化能力。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可以应用于改进Transformer模型的架构设计,使其能够更好地处理长序列数据,例如在机器翻译、文本摘要、对话系统等领域。通过解决随机访问限制,可以提升模型在处理长文本时的性能和泛化能力,从而提高相关应用的质量和效率。此外,该研究也为理解Transformer模型的内部机制提供了新的视角。
📄 摘要(原文)
Despite their recent successes, Transformer-based large language models show surprising failure modes. A well-known example of such failure modes is their inability to length-generalize: solving problem instances at inference time that are longer than those seen during training. In this work, we further explore the root cause of this failure by performing a detailed analysis of model behaviors on the simple parity task. Our analysis suggests that length generalization failures are intricately related to a model's inability to perform random memory accesses within its context window. We present supporting evidence for this hypothesis by demonstrating the effectiveness of methodologies that circumvent the need for indexing or that enable random token access indirectly, through content-based addressing. We further show where and how the failure to perform random memory access manifests through attention map visualizations.