How Well Do LLMs Identify Cultural Unity in Diversity?
作者: Jialin Li, Junli Wang, Junjie Hu, Ming Jiang
分类: cs.CL
发布日期: 2024-08-09
备注: COLM 2024
💡 一句话要点
提出CUNIT基准数据集,评估大语言模型对跨文化概念统一性的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文化理解 跨文化关联 基准数据集 对比学习
📋 核心要点
- 现有工作侧重于LLM对文化差异的敏感性,忽略了文化间的共通之处,导致对文化理解的片面性。
- 论文构建CUNIT数据集,通过对比匹配任务,评估LLM识别跨文化概念关联的能力,考察其文化统一性理解。
- 实验表明,LLM在捕捉跨文化概念关联方面仍有局限,且地缘文化邻近性对模型性能影响较小。
📝 摘要(中文)
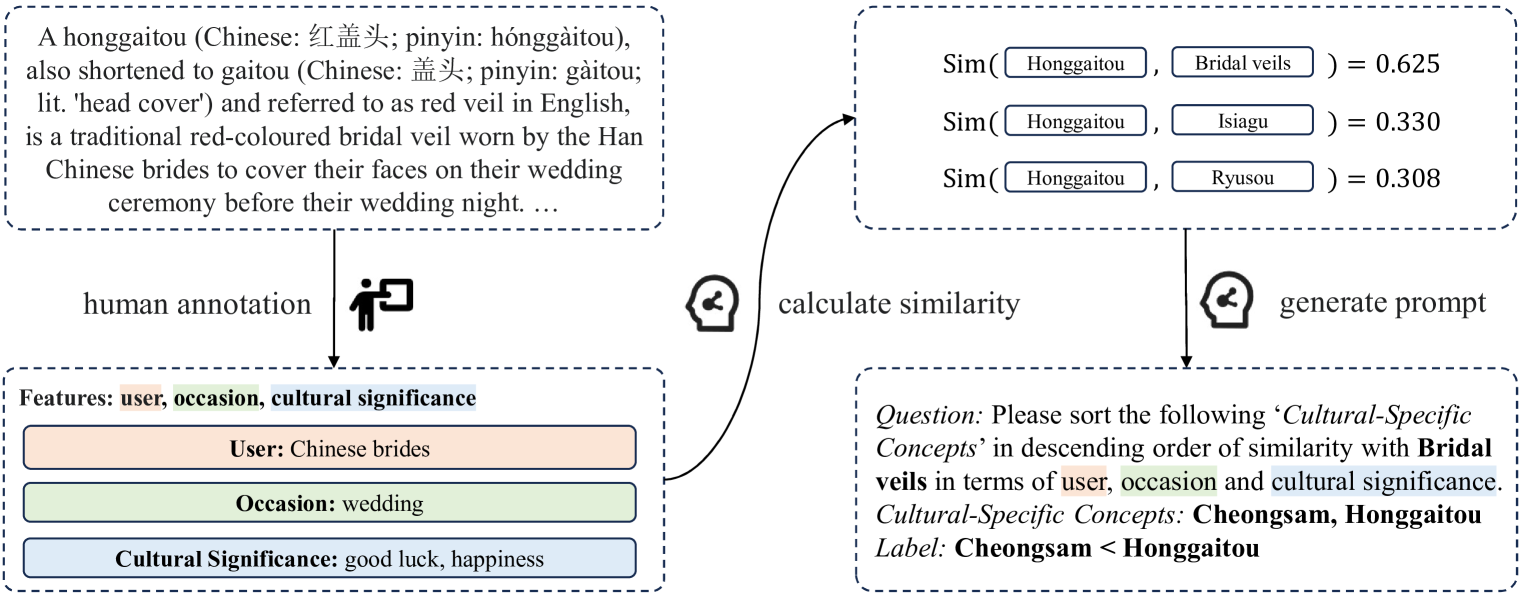
现有关于大语言模型(LLMs)文化感知能力的研究主要集中在模型对地域文化多样性的敏感性上。然而,除了跨文化差异之外,文化之间也存在共同点。例如,美国的婚纱头纱与中国的红盖头在文化上扮演着相似的角色。本研究提出了一个名为CUNIT的基准数据集,用于评估decoder-only LLMs理解概念文化统一性的能力。CUNIT包含1425个评估样例,构建于10个国家285个传统文化特定概念之上。基于对每个概念文化相关特征的系统性人工标注,我们计算了任意一对跨文化概念之间的文化关联。基于此数据集,我们设计了一个对比匹配任务,以评估LLMs识别高度相关的跨文化概念对的能力。我们评估了3个强大的LLMs,使用3种流行的prompting策略,在给出所有提取的概念特征或不给出任何特征的设置下进行评估。有趣的是,我们发现各国在服装概念方面的文化关联与食物大相径庭。我们的分析表明,与人类相比,LLMs在捕捉概念之间的跨文化关联方面仍然存在局限性。此外,地缘文化邻近性对模型捕捉跨文化关联的表现影响不大。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在理解跨文化概念统一性方面的不足。现有方法主要关注LLMs对不同文化间差异的识别,而忽略了不同文化中相似概念的关联性。这种片面的文化理解限制了LLMs在跨文化交流和理解方面的应用。
核心思路:论文的核心思路是通过构建一个包含跨文化概念关联信息的基准数据集(CUNIT),并设计对比匹配任务,来评估LLMs识别和理解这些关联的能力。通过对比LLMs在识别高关联跨文化概念对方面的表现,可以衡量其对文化统一性的理解程度。这种方法能够更全面地评估LLMs的文化感知能力。
技术框架:整体框架包括以下几个主要阶段: 1. 数据集构建:收集来自10个国家/地区的285个文化特定概念,并进行人工标注,提取每个概念的文化相关特征。 2. 关联计算:基于人工标注的特征,计算不同文化概念之间的文化关联度。 3. 对比匹配任务设计:设计对比匹配任务,要求LLMs从多个候选概念对中选择关联度最高的跨文化概念对。 4. 模型评估:使用不同的prompting策略,评估LLMs在CUNIT数据集上的表现。
关键创新:论文的关键创新在于: 1. CUNIT数据集:首次提出了一个专门用于评估LLMs对跨文化概念统一性理解的基准数据集。 2. 对比匹配任务:设计了一种新的对比匹配任务,能够有效地评估LLMs识别跨文化概念关联的能力。 3. 文化关联分析:对不同文化概念之间的关联进行了深入分析,揭示了LLMs在理解文化统一性方面的局限性。
关键设计: * 数据集构建:人工标注概念的文化相关特征,例如功能、象征意义、使用场景等。 * 关联计算:使用余弦相似度等方法,基于概念的特征向量计算文化关联度。 * Prompting策略:采用不同的prompting策略,例如zero-shot、few-shot等,以评估LLMs在不同条件下的表现。 * 模型选择:选择了多个decoder-only LLMs进行评估,例如GPT-3、LLaMA等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLMs在CUNIT数据集上的表现与人类相比仍有差距,表明其在理解跨文化概念关联方面存在局限性。此外,研究发现地缘文化邻近性对模型性能的影响较小,暗示LLMs可能更多依赖于表面文本信息,而非深层次的文化理解。不同类型的概念(如服装和食物)的文化关联模式也存在显著差异。
🎯 应用场景
该研究成果可应用于提升LLMs在跨文化交流、机器翻译、文化遗产保护等领域的表现。通过提高LLMs对文化统一性的理解,可以减少文化误解和偏见,促进不同文化之间的交流与合作。此外,CUNIT数据集可以作为LLMs文化感知能力研究的重要资源。
📄 摘要(原文)
Much work on the cultural awareness of large language models (LLMs) focuses on the models' sensitivity to geo-cultural diversity. However, in addition to cross-cultural differences, there also exists common ground across cultures. For instance, a bridal veil in the United States plays a similar cultural-relevant role as a honggaitou in China. In this study, we introduce a benchmark dataset CUNIT for evaluating decoder-only LLMs in understanding the cultural unity of concepts. Specifically, CUNIT consists of 1,425 evaluation examples building upon 285 traditional cultural-specific concepts across 10 countries. Based on a systematic manual annotation of cultural-relevant features per concept, we calculate the cultural association between any pair of cross-cultural concepts. Built upon this dataset, we design a contrastive matching task to evaluate the LLMs' capability to identify highly associated cross-cultural concept pairs. We evaluate 3 strong LLMs, using 3 popular prompting strategies, under the settings of either giving all extracted concept features or no features at all on CUNIT Interestingly, we find that cultural associations across countries regarding clothing concepts largely differ from food. Our analysis shows that LLMs are still limited to capturing cross-cultural associations between concepts compared to humans. Moreover, geo-cultural proximity shows a weak influence on model performance in capturing cross-cultural associations.