Unlocking Decoding-time Controllability: Gradient-Free Multi-Objective Alignment with Contrastive Prompts
作者: Tingchen Fu, Yupeng Hou, Julian McAuley, Rui Yan
分类: cs.CL
发布日期: 2024-08-09
💡 一句话要点
提出MCA,通过对比提示实现解码时可控的多目标对齐,无需梯度训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多目标对齐 对比学习 大型语言模型 解码时控制 提示工程
📋 核心要点
- 现有方法需训练多个模型以适应不同用户偏好,模型数量随目标数量线性增长,扩展性差。
- MCA通过构建专家提示和对抗提示,在解码时进行对比,无需梯度训练即可平衡多个目标。
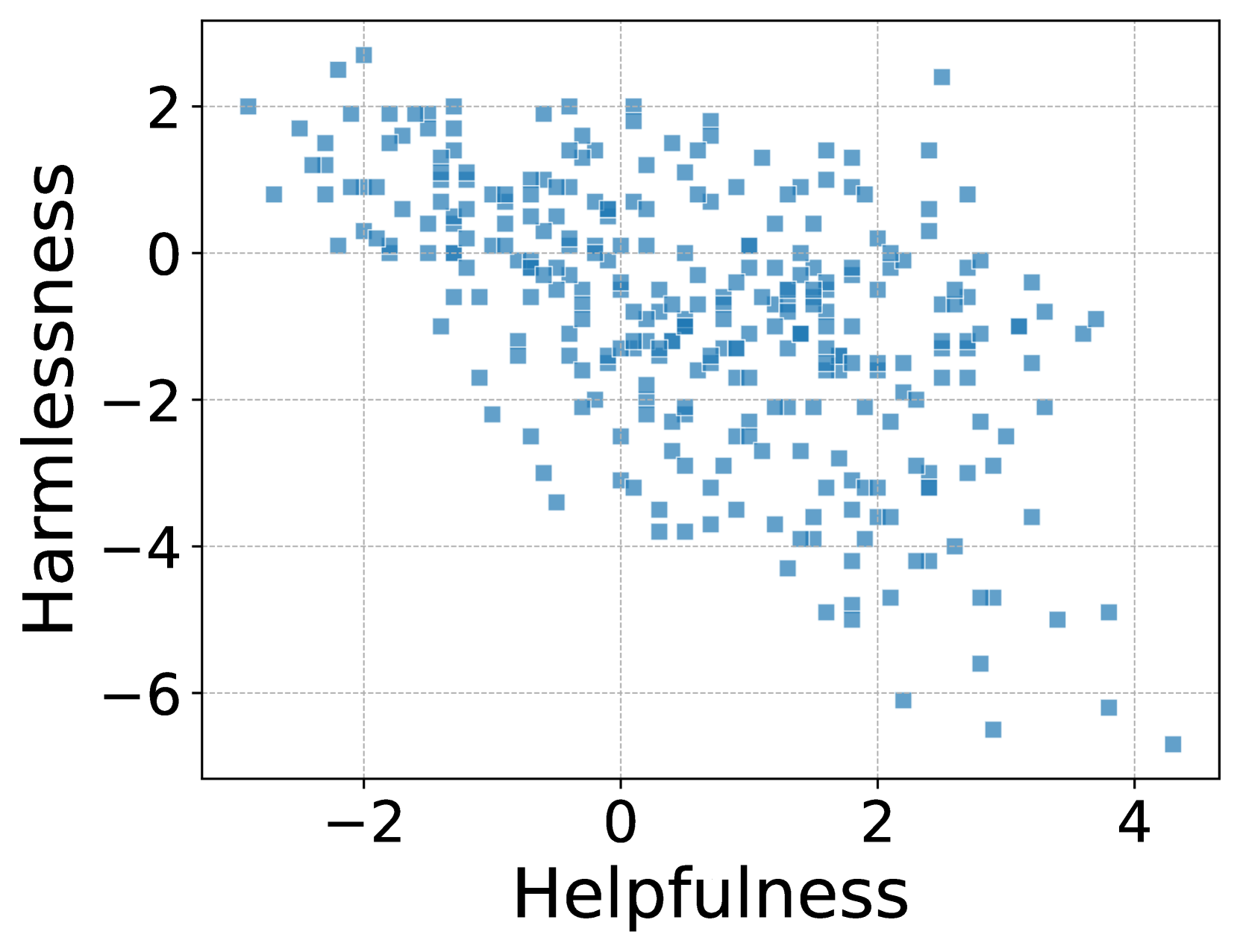
- 实验表明,MCA在不同对齐目标间能获得更好的帕累托前沿,优于现有方法。
📝 摘要(中文)
多目标对齐旨在平衡和控制大型语言模型的不同对齐目标(例如,乐于助人、无害和诚实),以满足不同用户的个性化需求。然而,先前的方法倾向于训练多个模型来处理各种用户偏好,导致训练模型的数量随对齐目标和不同偏好的数量线性增长。同时,现有方法的可扩展性通常较差,并且对于考虑的每个新对齐目标都需要进行大量的重新训练。考虑到先前方法的局限性,我们提出了MCA(多目标对比对齐),它为每个目标构建一个专家提示和一个对抗提示,以便在解码时进行对比,并通过组合对比来平衡目标。经验证,我们的方法在获得不同对齐目标之间分布良好的帕累托前沿方面优于先前的方法。
🔬 方法详解
问题定义:多目标对齐旨在平衡大型语言模型在多个目标(如helpful, harmless, honest)上的表现,以满足不同用户的个性化需求。现有方法的主要痛点在于:1) 需要为每种用户偏好训练单独的模型,导致模型数量随目标数量线性增长,训练成本高昂;2) 扩展性差,新增目标需要大量重新训练;3) 难以在解码时进行灵活控制。
核心思路:MCA的核心思路是利用对比学习的思想,在解码阶段通过对比专家提示(expert prompt)和对抗提示(adversarial prompt)来控制模型的输出。专家提示引导模型朝着特定目标前进,而对抗提示则引导模型远离该目标。通过调整两种提示的组合方式,可以实现对多个目标的平衡。这种方法无需梯度训练,可以在解码时灵活调整,具有良好的可扩展性。
技术框架:MCA的整体框架如下:1) 为每个对齐目标构建一个专家提示和一个对抗提示。专家提示旨在引导模型生成符合该目标的内容,对抗提示则旨在引导模型生成违反该目标的内容。2) 在解码阶段,将原始输入提示与专家提示和对抗提示进行组合。组合方式可以是简单的加权平均,也可以是更复杂的函数。3) 模型根据组合后的提示生成文本。通过调整专家提示和对抗提示的权重,可以控制模型在不同目标上的表现。
关键创新:MCA最重要的创新点在于:1) 提出了一种无需梯度训练的多目标对齐方法,大大降低了训练成本;2) 通过对比提示实现了在解码时对多个目标的灵活控制,提高了可扩展性;3) 将对比学习的思想引入到多目标对齐任务中,为解决该问题提供了一种新的思路。与现有方法相比,MCA避免了为每种用户偏好训练单独模型的需要,并且可以轻松地添加新的对齐目标。
关键设计:MCA的关键设计包括:1) 专家提示和对抗提示的设计。提示的设计需要能够有效地引导模型朝着或远离特定目标。2) 提示组合方式的设计。组合方式需要能够平衡不同目标之间的冲突。3) 权重的设置。权重的设置需要能够反映用户对不同目标的偏好。论文中可能使用了启发式方法或优化算法来确定这些参数。
🖼️ 关键图片


📊 实验亮点
论文验证了MCA在多目标对齐任务上的有效性。实验结果表明,MCA能够在不同对齐目标之间获得分布良好的帕累托前沿,这意味着MCA能够在多个目标上取得较好的平衡。与现有方法相比,MCA在帕累托前沿的覆盖范围和均匀性方面均有显著提升,表明其在多目标对齐方面具有优越的性能。
🎯 应用场景
MCA可应用于各种需要对大型语言模型进行多目标对齐的场景,例如:个性化对话系统、内容生成、智能助手等。它可以根据用户的偏好,生成既乐于助人、又无害、又诚实的文本。该研究有助于提高语言模型的安全性和可靠性,并促进人机之间的有效沟通。
📄 摘要(原文)
The task of multi-objective alignment aims at balancing and controlling the different alignment objectives (e.g., helpfulness, harmlessness and honesty) of large language models to meet the personalized requirements of different users. However, previous methods tend to train multiple models to deal with various user preferences, with the number of trained models growing linearly with the number of alignment objectives and the number of different preferences. Meanwhile, existing methods are generally poor in extensibility and require significant re-training for each new alignment objective considered. Considering the limitation of previous approaches, we propose MCA (Multi-objective Contrastive Alignemnt), which constructs an expert prompt and an adversarial prompt for each objective to contrast at the decoding time and balances the objectives through combining the contrast. Our approach is verified to be superior to previous methods in obtaining a well-distributed Pareto front among different alignment objectives.