ProFuser: Progressive Fusion of Large Language Models
作者: Tianyuan Shi, Fanqi Wan, Canbin Huang, Xiaojun Quan, Chenliang Li, Ming Yan, Ji Zhang, Minhua Huang, Wu Kai
分类: cs.CL, cs.AI
发布日期: 2024-08-09 (更新: 2025-11-15)
备注: Accepted to AAAI 2026
💡 一句话要点
ProFuser:通过渐进式融合提升大型语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型融合 模型优势评估 渐进式学习 推理模式 训练模式
📋 核心要点
- 现有大语言模型融合方法仅依赖训练过程中的交叉熵评估模型优劣,缺乏对模型推理能力的考量。
- ProFuser通过结合训练和推理模式评估模型优势,并设计渐进式过渡策略,实现更有效的模型融合。
- 实验结果表明,ProFuser在知识、推理和安全性方面均优于基线方法,验证了其有效性。
📝 摘要(中文)
融合多个大型语言模型的能力和优势是构建更强大、更通用的模型的一种途径,但一个根本的挑战是如何在训练过程中正确选择优势模型。现有的融合方法主要侧重于在教师强制设置中使用交叉熵来衡量模型的优势,这种方法可能对模型优势的洞察力有限。本文提出了一种新颖的方法,通过结合训练和推理模式来增强融合过程。我们的方法不仅通过训练期间的交叉熵来评估模型优势,还考虑了推理输出,从而提供更全面的评估。为了有效地结合这两种模式,我们引入了ProFuser,以逐步从推理模式过渡到训练模式。为了验证ProFuser的有效性,我们融合了三个模型,包括Vicuna-7B-v1.5、Llama-2-7B-Chat和MPT-7B-8K-Chat,并证明了在知识、推理和安全性方面相比基线方法有所提高。
🔬 方法详解
问题定义:现有的大型语言模型融合方法主要依赖于训练阶段的交叉熵损失来评估各个模型的优势,这种方法的局限性在于它只关注了模型在训练数据上的表现,而忽略了模型在实际推理过程中的能力。因此,如何更全面地评估模型优势,并有效地融合不同模型的优点,是本文要解决的核心问题。现有方法的痛点在于评估指标单一,无法充分利用模型的推理能力。
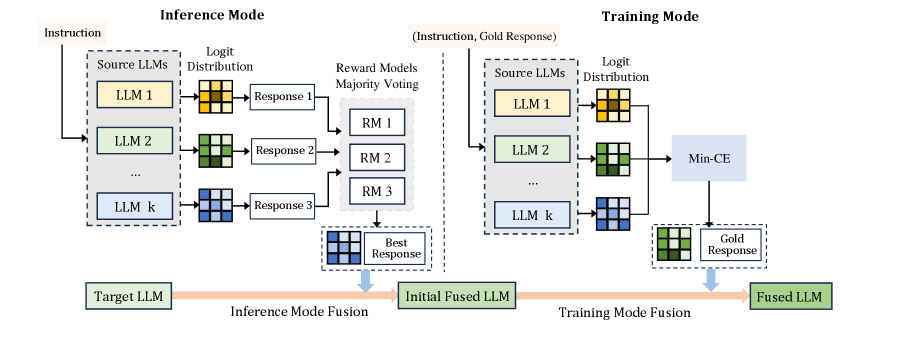
核心思路:ProFuser的核心思路是结合训练和推理两种模式来评估模型优势,并设计一种渐进式的融合策略,使得模型能够从推理模式平滑过渡到训练模式。这种设计背后的原因是,推理模式能够更直接地反映模型在实际应用中的表现,而训练模式则能够保证模型在训练数据上的性能。通过渐进式过渡,可以避免模型在融合过程中出现性能下降的情况。
技术框架:ProFuser的整体框架包含两个主要阶段:模型优势评估和渐进式融合。在模型优势评估阶段,ProFuser同时考虑训练阶段的交叉熵损失和推理阶段的输出结果,从而更全面地评估各个模型的优势。在渐进式融合阶段,ProFuser通过一种渐进式的策略,逐步从推理模式过渡到训练模式,从而实现更有效的模型融合。
关键创新:ProFuser最重要的技术创新点在于其结合训练和推理模式来评估模型优势,并设计了一种渐进式的融合策略。与现有方法相比,ProFuser能够更全面地评估模型优势,并更有效地融合不同模型的优点。这种方法能够显著提高融合模型的性能,尤其是在知识、推理和安全性方面。
关键设计:ProFuser的关键设计包括:1) 使用交叉熵损失和推理输出的加权组合来评估模型优势;2) 设计一种渐进式的过渡函数,控制从推理模式到训练模式的过渡速度;3) 针对不同的模型和任务,调整过渡函数的参数,以获得最佳的融合效果。具体的损失函数和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
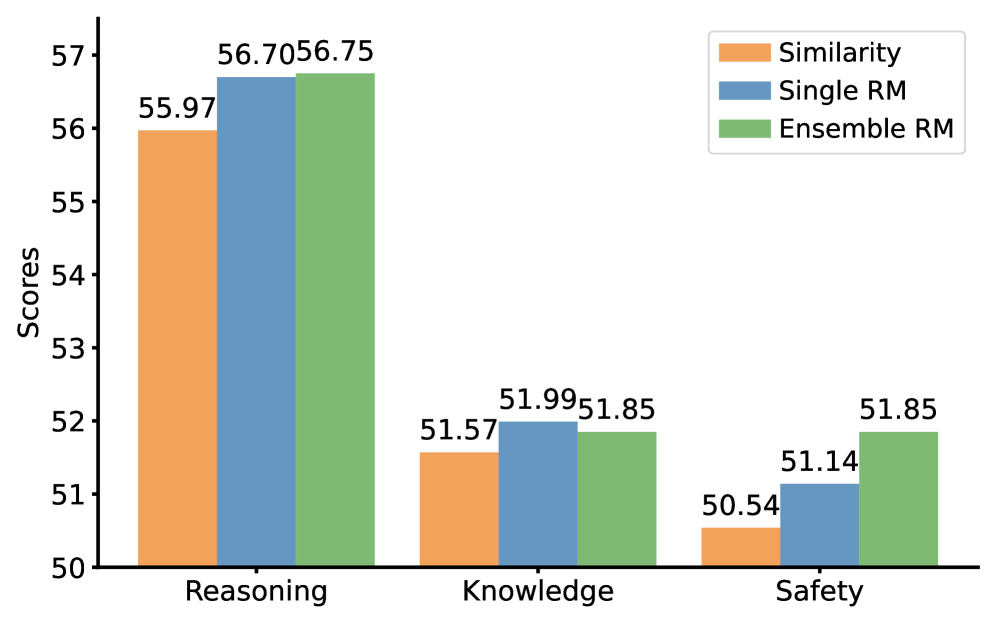
ProFuser通过融合Vicuna-7B-v1.5、Llama-2-7B-Chat和MPT-7B-8K-Chat三个模型,在知识、推理和安全性方面均优于基线方法。具体性能提升数据未在摘要中给出,属于未知信息。实验结果验证了ProFuser在提升模型性能方面的有效性。
🎯 应用场景
ProFuser具有广泛的应用前景,可用于构建更强大、更通用的对话系统、智能助手等。通过融合不同模型的优势,可以显著提高这些应用在知识、推理和安全性方面的性能。此外,ProFuser还可以应用于其他自然语言处理任务,如文本生成、机器翻译等,具有重要的实际价值和未来影响。
📄 摘要(原文)
While fusing the capacities and advantages of various large language models offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including Vicuna-7B-v1.5, Llama-2-7B-Chat, and MPT-7B-8K-Chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.