Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
作者: Yuchen Xia, Jiho Kim, Yuhan Chen, Haojie Ye, Souvik Kundu, Cong Hao, Nishil Talati
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-08
备注: 10 pages, conference
💡 一句话要点
分析MoE LLM微调性能并建立成本估算模型,助力高效LLM应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 混合专家模型 性能分析 成本估算
📋 核心要点
- 大型语言模型训练成本高昂,微调成为针对特定任务定制LLM的有效方法,但缺乏对MoE LLM微调性能的深入理解。
- 本文通过分析稀疏MoE LLM在单GPU上的微调过程,深入理解其准确性和运行时性能,为优化微调过程提供指导。
- 论文构建并验证了一个分析模型,能够基于模型和GPU架构参数,估算LLM微调的成本,辅助用户进行成本预算。
📝 摘要(中文)
由于训练大型语言模型(LLM)成本高昂,微调已成为一种有吸引力的替代方案,它能以经济高效的方式,使用有限的计算资源来专门化LLM以适应特定任务。本文旨在分析基于稀疏混合专家(MoE)的LLM微调,以了解其在单个GPU上的准确性和运行时性能。我们的评估提供了对MoE模型的稀疏和密集版本的训练效果以及运行时特征的独特见解,包括最大批量大小、执行时间分解、端到端吞吐量、GPU硬件利用率和负载分配。我们的研究表明,优化MoE层对于进一步提高LLM微调的性能至关重要。利用我们的分析结果,我们还开发并验证了一个分析模型,用于估算云上LLM微调的成本。该模型基于模型和GPU架构的参数,估计LLM吞吐量和训练成本,从而帮助行业和学术界的从业者预算特定模型的微调成本。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)训练成本非常高,因此微调成为了一个更经济的选择。然而,对于稀疏混合专家(MoE)结构的LLM,其微调过程的性能特征,例如准确率、运行时效率、资源利用率等,缺乏深入的理解。这使得用户难以有效地进行模型选择、资源配置和成本预算。
核心思路:本文的核心思路是通过对MoE LLM在单GPU上的微调过程进行详细的性能剖析,来揭示其训练效果和运行时特征。然后,基于这些剖析结果,构建一个分析模型,用于预测LLM微调的成本。这样,用户就可以在实际微调之前,对模型的性能和成本有一个大致的了解。
技术框架:本文的研究框架主要包括两个部分:1) 性能剖析:对MoE LLM在单GPU上的微调过程进行详细的性能剖析,包括最大批量大小、执行时间分解、端到端吞吐量、GPU硬件利用率和负载分配等。2) 成本估算模型:基于性能剖析的结果,构建一个分析模型,用于估算LLM微调的成本。该模型以模型参数和GPU架构为输入,输出LLM吞吐量和训练成本的估计值。
关键创新:本文的关键创新在于:1) 深入分析了稀疏MoE LLM的微调性能,揭示了其独特的运行时特征。2) 构建了一个基于性能剖析的分析模型,能够准确地估算LLM微调的成本。与现有方法相比,该模型更加精确,能够为用户提供更可靠的成本预算。
关键设计:在性能剖析方面,论文使用了多种性能分析工具,例如NVIDIA Nsight Systems,来收集详细的运行时数据。在成本估算模型方面,论文考虑了多种因素,例如模型大小、GPU架构、数据并行度等。此外,论文还对模型进行了验证,证明其能够准确地预测LLM微调的成本。
🖼️ 关键图片
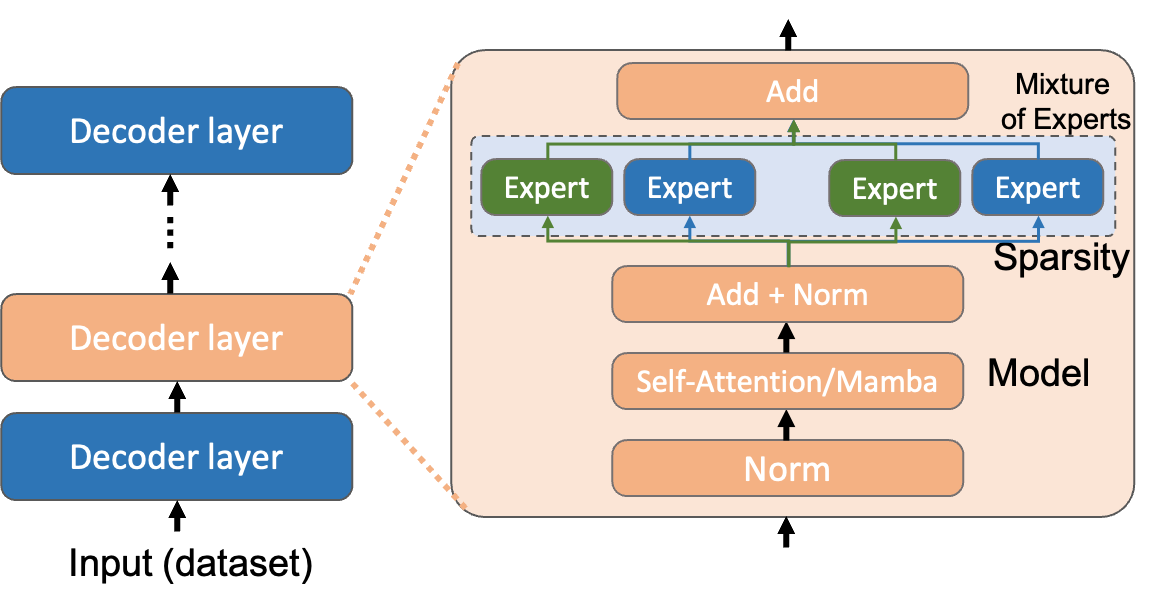


📊 实验亮点
该研究通过实验分析了MoE LLM在单GPU上的微调性能,揭示了其独特的运行时特征,例如最大批量大小、执行时间分解、端到端吞吐量、GPU硬件利用率和负载分配等。此外,论文还构建并验证了一个分析模型,能够准确地估算LLM微调的成本,为用户提供可靠的成本预算。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行微调的场景,例如自然语言处理、机器翻译、文本生成等。通过该研究,用户可以更好地理解MoE LLM的微调性能,并能够准确地估算微调成本,从而做出更明智的决策。这将有助于降低LLM的应用门槛,促进LLM在各个领域的广泛应用。
📄 摘要(原文)
Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.