Synthetic SQL Column Descriptions and Their Impact on Text-to-SQL Performance
作者: Niklas Wretblad, Oskar Holmström, Erik Larsson, Axel Wiksäter, Oscar Söderlund, Hjalmar Öhman, Ture Pontén, Martin Forsberg, Martin Sörme, Fredrik Heintz
分类: cs.CL, cs.AI, cs.DB
发布日期: 2024-08-08 (更新: 2024-11-05)
💡 一句话要点
利用LLM生成SQL列描述提升Text-to-SQL性能,并构建了高质量的列描述数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大型语言模型 列描述生成 元数据增强 数据库查询 自然语言处理 BIRD-Bench
📋 核心要点
- 现有的关系数据库列描述信息不足,影响人和Text-to-SQL模型对数据库的理解和使用。
- 利用大型语言模型自动生成SQL数据库列的详细自然语言描述,以提升Text-to-SQL性能。
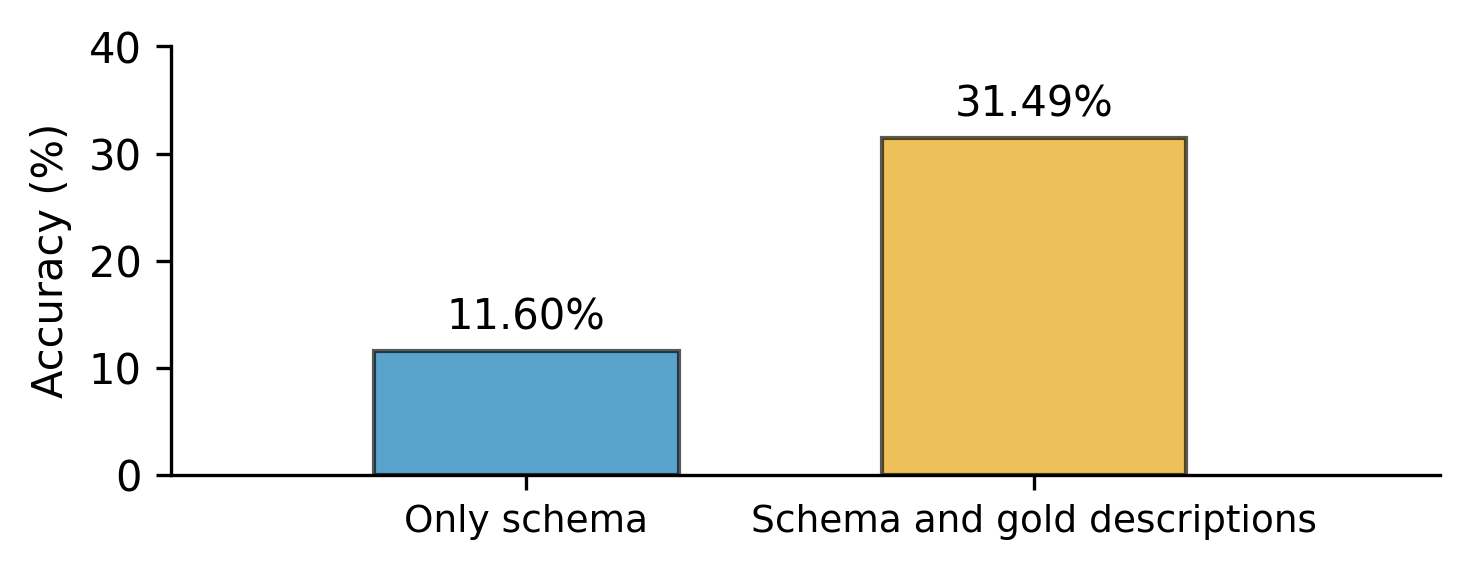
- 实验表明,结合LLM生成的列描述能持续提高Text-to-SQL模型性能,特别是对于大型模型,且Qwen2生成的描述甚至优于人工标注。
📝 摘要(中文)
本文探讨了使用大型语言模型(LLMs)自动生成SQL数据库列的详细自然语言描述,旨在提高Text-to-SQL的性能并自动化元数据创建。作者基于BIRD-Bench基准创建了一个黄金列描述数据集,手动改进了其列描述,并创建了一个用于对列难度进行分类的分类法。评估了几种不同的LLM在生成列描述方面的能力,发现模型在处理固有歧义的列时表现不佳,突出了人工专家输入的需求。研究表明,结合生成的列描述能够持续提高Text-to-SQL模型的性能,特别是对于GPT-4o、Qwen2 72B和Mixtral 22Bx8等大型模型。值得注意的是,包含被标注者认为多余信息的Qwen2生成的描述,优于手动策划的黄金描述,表明模型受益于比人类预期更详细的元数据。未来的工作将调查这些高性能描述的特定特征,并探索其他类型的元数据,例如数值推理和同义词,以进一步改进Text-to-SQL系统。数据集、注释和代码都将公开。
🔬 方法详解
问题定义:本文旨在解决关系数据库中列描述信息不足的问题,现有方法难以提供清晰、准确的列描述,导致人和Text-to-SQL模型难以理解数据库结构和内容,从而影响Text-to-SQL的准确性。
核心思路:核心思路是利用大型语言模型(LLMs)的自然语言生成能力,自动为SQL数据库的列生成详细的自然语言描述。通过提供更丰富、更易于理解的元数据,帮助Text-to-SQL模型更好地理解数据库模式,从而提高查询转换的准确性。
技术框架:整体框架包括以下几个主要阶段:1) 构建高质量的列描述数据集:基于BIRD-Bench基准,手动改进列描述并进行难度分类。2) 使用不同的LLMs生成列描述:评估不同LLMs在生成列描述方面的性能。3) 将生成的列描述集成到Text-to-SQL模型中:评估集成列描述后Text-to-SQL模型的性能提升。
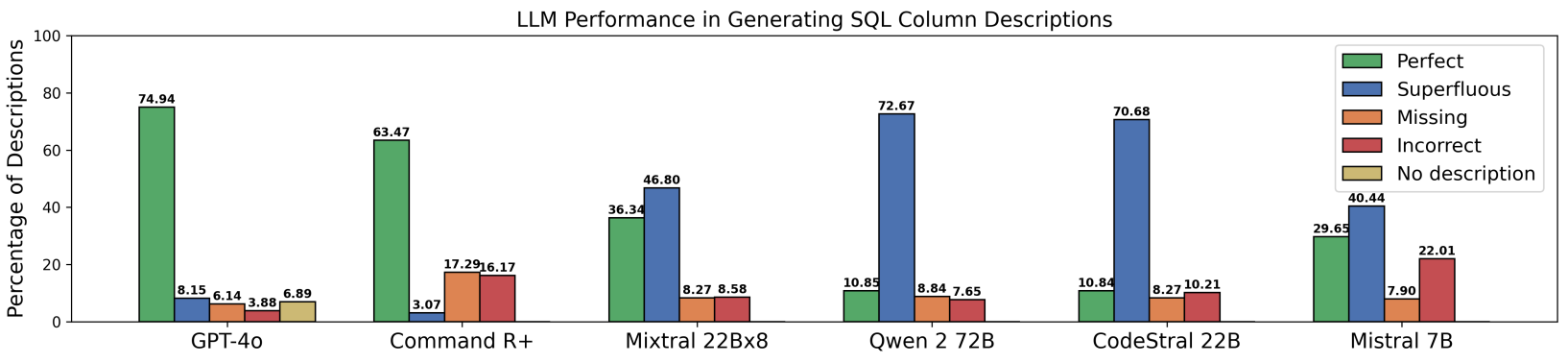
关键创新:关键创新在于发现LLM生成的、包含冗余信息的列描述,在提升Text-to-SQL性能方面,甚至优于人工标注的黄金标准描述。这表明模型可能受益于比人类预期更详细的元数据。
关键设计:论文的关键设计包括:1) 数据集的构建:手动改进BIRD-Bench的列描述,并创建列难度分类体系。2) LLM的选择:评估了多种LLM,包括GPT-4o、Qwen2 72B和Mixtral 22Bx8等。3) Text-to-SQL模型的集成:将生成的列描述作为输入,增强Text-to-SQL模型对数据库模式的理解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,将LLM生成的列描述集成到Text-to-SQL模型中,能够持续提高模型性能,特别是对于大型模型如GPT-4o、Qwen2 72B和Mixtral 22Bx8。更令人惊讶的是,Qwen2生成的包含冗余信息的描述,甚至优于人工标注的黄金标准描述,这为未来的元数据生成提供了新的思路。
🎯 应用场景
该研究成果可应用于各种需要进行数据库查询的场景,例如智能客服、数据分析平台等。通过自动生成高质量的列描述,可以降低用户理解数据库的门槛,提高查询效率和准确性,并能自动化元数据创建,降低数据库维护成本。未来可扩展到其他类型的元数据生成,进一步提升数据库智能化水平。
📄 摘要(原文)
Relational databases often suffer from uninformative descriptors of table contents, such as ambiguous columns and hard-to-interpret values, impacting both human users and text-to-SQL models. In this paper, we explore the use of large language models (LLMs) to automatically generate detailed natural language descriptions for SQL database columns, aiming to improve text-to-SQL performance and automate metadata creation. We create a dataset of gold column descriptions based on the BIRD-Bench benchmark, manually refining its column descriptions and creating a taxonomy for categorizing column difficulty. We then evaluate several different LLMs in generating column descriptions across the columns and different difficulties in the dataset, finding that models unsurprisingly struggle with columns that exhibit inherent ambiguity, highlighting the need for manual expert input. We also find that incorporating such generated column descriptions consistently enhances text-to-SQL model performance, particularly for larger models like GPT-4o, Qwen2 72B and Mixtral 22Bx8. Notably, Qwen2-generated descriptions, containing by annotators deemed superfluous information, outperform manually curated gold descriptions, suggesting that models benefit from more detailed metadata than humans expect. Future work will investigate the specific features of these high-performing descriptions and explore other types of metadata, such as numerical reasoning and synonyms, to further improve text-to-SQL systems. The dataset, annotations and code will all be made available.