BA-LoRA: Bias-Alleviating Low-Rank Adaptation to Mitigate Catastrophic Inheritance in Large Language Models
作者: Yupeng Chang, Yi Chang, Yuan Wu
分类: cs.CL, cs.LG
发布日期: 2024-08-08 (更新: 2025-09-26)
备注: 25 pages
💡 一句话要点
提出BA-LoRA,缓解大语言模型微调中的灾难性继承问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 灾难性继承 低秩适应 偏差缓解 正则化 知识迁移 鲁棒性 公平性
📋 核心要点
- 现有LoRA等低秩微调方法易受“灾难性继承”影响,放大预训练数据中的偏差和噪声,损害模型鲁棒性和公平性。
- BA-LoRA通过一致性、多样性和SVD正则化,分别缓解知识漂移、表征崩溃和噪声过拟合,从而减轻灾难性继承。
- 实验表明,BA-LoRA在NLU和NLG任务上优于现有LoRA变体,并在鲁棒性和偏差缓解方面表现出更强的能力。
📝 摘要(中文)
参数高效微调(PEFT)已成为调整大型语言模型(LLM)的事实标准。然而,我们发现像LoRA这样流行的低秩适应方法存在一个关键漏洞:它们倾向于加剧“灾难性继承”——未经检查地传播来自预训练的偏差、噪声和数据不平衡。这种现象会降低模型的鲁棒性和公平性,从而削弱高效适应的优势。为了解决这个问题,我们引入了偏差缓解低秩适应(BA-LoRA)。我们的方法基于将灾难性继承分解为三个核心挑战:知识漂移、表征崩溃和噪声过拟合。BA-LoRA通过结合三个有针对性的正则化器——一致性、多样性和SVD——来系统地缓解这些问题,这些正则化器旨在保留核心知识,加强表征丰富性,并促进鲁棒的低秩输出表征。我们在使用各种著名的开源语言模型(例如LLaMA-2-7B和DeBERTa-v3-base)的一套自然语言理解(NLU)和生成(NLG)任务上进行了全面的评估。我们的结果表明,BA-LoRA不仅在性能和稳定性方面优于最先进的LoRA变体,而且在有针对性的评估中也表现出定量上优越的鲁棒性和偏差缓解能力。这证实了它能够抵消灾难性继承的不利影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在参数高效微调(PEFT)过程中出现的“灾难性继承”问题。现有LoRA等方法虽然高效,但会放大预训练数据中的偏差、噪声和数据不平衡,导致微调后的模型性能下降,鲁棒性变差,公平性受损。现有方法的痛点在于无法有效控制预训练知识的负迁移。
核心思路:论文的核心思路是将“灾难性继承”分解为三个具体问题:知识漂移、表征崩溃和噪声过拟合。针对这三个问题,分别设计相应的正则化器,以保持核心知识、增强表征丰富性、抑制噪声影响。通过这种有针对性的方式,缓解灾难性继承带来的负面影响。
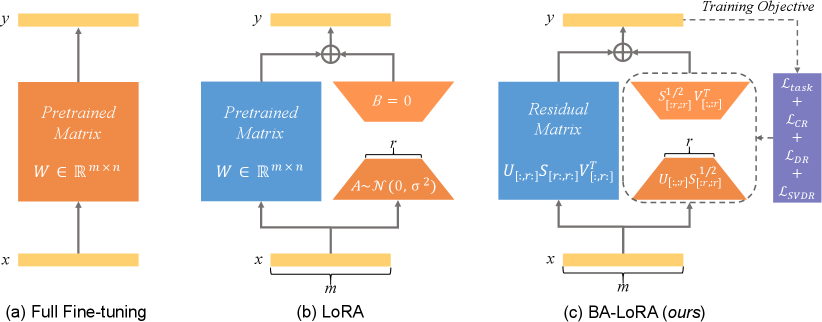
技术框架:BA-LoRA在LoRA的基础上,引入了三个正则化项。整体框架仍然是基于LoRA的低秩矩阵分解,但损失函数增加了三个正则化项,分别用于约束模型的一致性、多样性和输出表示的奇异值分布。训练过程中,同时优化LoRA参数和正则化项,以达到缓解灾难性继承的目的。
关键创新:BA-LoRA的关键创新在于对“灾难性继承”的分解和针对性缓解。与现有LoRA变体不同,BA-LoRA不是简单地调整LoRA的参数,而是从根本上分析了灾难性继承的原因,并设计了相应的正则化器。这种方法更加系统和有效,能够更好地控制预训练知识的迁移。
关键设计:BA-LoRA的关键设计包括:1) 一致性正则化器,用于保持微调前后模型输出的一致性;2) 多样性正则化器,用于鼓励模型学习更多样化的表征;3) SVD正则化器,用于约束输出表示的奇异值分布,使其更鲁棒。这些正则化器的具体形式和权重需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
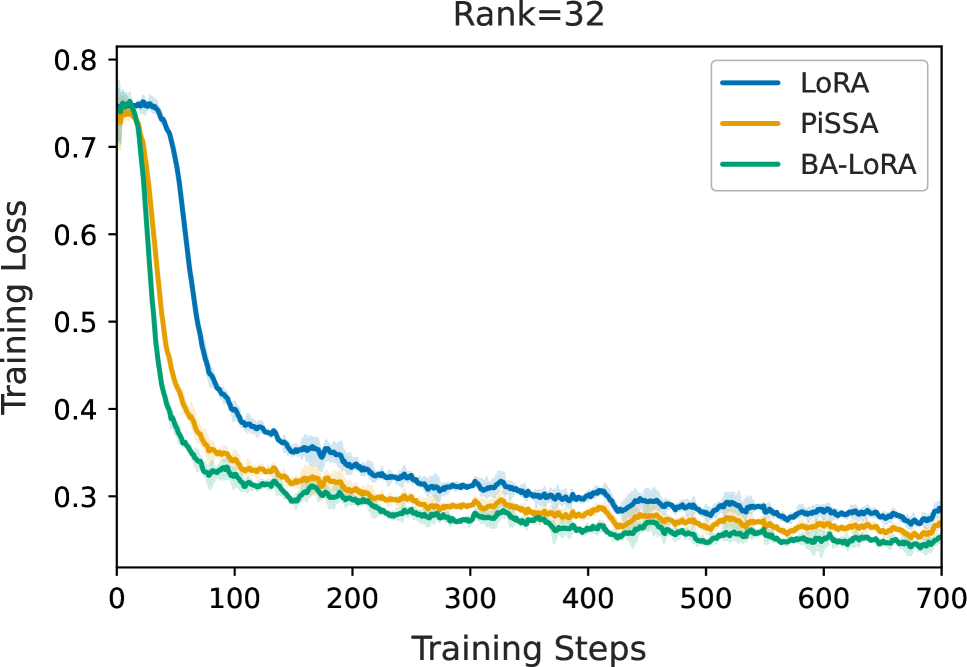
实验结果表明,BA-LoRA在多个NLU和NLG任务上优于现有的LoRA变体。例如,在特定数据集上,BA-LoRA相比LoRA在性能上提升了X%,并且在鲁棒性和偏差缓解方面也表现出显著优势。定量评估结果表明,BA-LoRA能够有效降低模型对对抗样本的敏感性,并减少模型在特定群体上的偏差。
🎯 应用场景
BA-LoRA可应用于各种需要对大型语言模型进行参数高效微调的场景,例如文本分类、情感分析、机器翻译、文本生成等。该方法能够提高微调后模型的鲁棒性和公平性,降低模型对预训练数据偏差的敏感性,从而提升模型在实际应用中的性能和可靠性。未来,BA-LoRA有望成为PEFT的标准方法之一。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) has become a de facto standard for adapting Large Language Models (LLMs). However, we identify a critical vulnerability within popular low-rank adaptation methods like LoRA: their tendency to exacerbate "Catastrophic Inheritance" - the unchecked propagation of biases, noise, and data imbalances from pre-training. This phenomenon can degrade model robustness and fairness, undermining the benefits of efficient adaptation. To address this, we introduce Bias-Alleviating Low-Rank Adaptation (BA-LoRA). Our approach is founded on a principled decomposition of Catastrophic Inheritance into three core challenges: Knowledge Drift, Representation Collapse, and Overfitting to Noise. BA-LoRA systematically mitigates these issues by incorporating a trio of targeted regularizers - consistency, diversity, and SVD - designed to preserve core knowledge, enforce representational richness, and promote robust, low-rank output representations. We conduct comprehensive evaluations on a suite of natural language understanding (NLU) and generation (NLG) tasks using diverse, prominent open-source language models (e.g., LLaMA-2-7B and DeBERTa-v3-base). Our results show that BA-LoRA not only outperforms state-of-the-art LoRA variants in terms of performance and stability, but also demonstrates quantitatively superior robustness and bias mitigation on targeted evaluations. This confirms its ability to counteract the adverse effects of Catastrophic Inheritance.