Automated Educational Question Generation at Different Bloom's Skill Levels using Large Language Models: Strategies and Evaluation
作者: Nicy Scaria, Suma Dharani Chenna, Deepak Subramani
分类: cs.CL, cs.AI
发布日期: 2024-08-08
期刊: Artificial Intelligence in Education. AIED 2024
DOI: 10.1007/978-3-031-64299-9_12
💡 一句话要点
利用大型语言模型自动生成不同布鲁姆认知水平的教育问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动教育问题生成 大型语言模型 布鲁姆分类法 提示工程 教育评估
📋 核心要点
- 教育工作者面临创建教学合理且能促进学习的问题的挑战,传统方法耗时且难以覆盖高认知水平。
- 该研究探索利用大型语言模型(LLM)和高级提示技术,自动生成不同布鲁姆认知水平的教育问题。
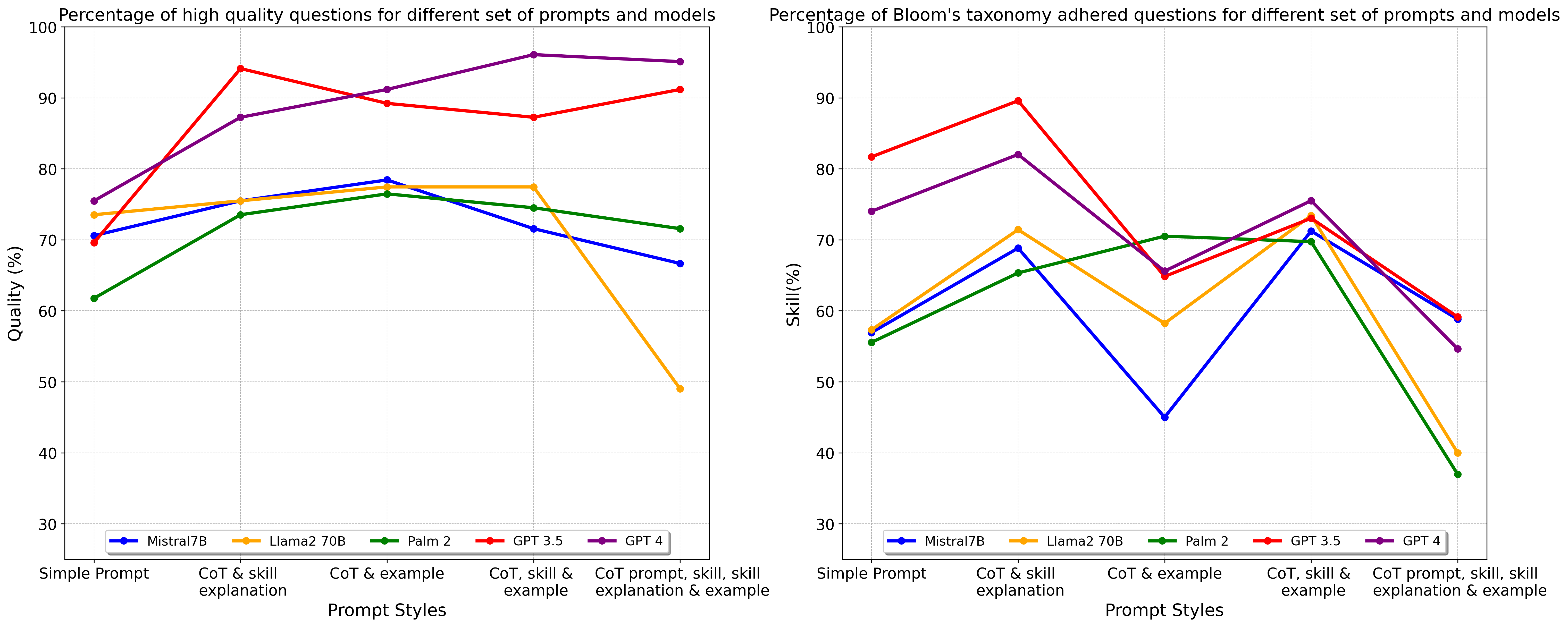
- 实验评估了五种LLM在生成高质量教育问题方面的能力,并比较了自动评估与人工评估的差异。
📝 摘要(中文)
对于教育工作者而言,开发在教学上合理、相关且能促进学习的问题是一项具有挑战性且耗时的任务。现代大型语言模型(LLM)可以在多个领域生成高质量的内容,从而有可能帮助教育工作者开发高质量的问题。自动教育问题生成(AEQG)对于扩展面向不同学生群体的在线教育至关重要。过去在AEQG方面的尝试显示出在较高认知水平上生成问题的能力有限。本研究考察了五种不同规模的先进LLM生成不同认知水平(由布鲁姆分类法定义)的多样化和高质量问题的能力。我们使用具有不同复杂性的高级提示技术进行AEQG。我们进行了专家评估和基于LLM的评估,以评估问题的语言和教学相关性及质量。我们的研究结果表明,当提供足够的信息时,LLM可以生成不同认知水平的相关且高质量的教育问题,尽管所考虑的五种LLM的性能存在显着差异。我们还表明,自动评估与人工评估并不相同。
🔬 方法详解
问题定义:论文旨在解决教育领域中自动生成高质量、多样化且符合不同布鲁姆认知水平教育问题的问题。现有方法在生成高认知水平问题方面存在局限性,且人工生成问题耗时耗力。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,通过设计合适的提示(prompting)策略,引导LLM生成符合特定认知水平的教育问题。通过调整提示的复杂度和信息量,控制LLM生成问题的难度和类型。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择合适的LLM模型;2) 设计不同复杂度的提示策略,以引导LLM生成不同认知水平的问题;3) 利用LLM生成候选问题;4) 通过专家评估和基于LLM的自动评估,对生成的问题进行质量评估。
关键创新:该研究的关键创新在于探索了利用高级提示技术,控制LLM生成符合特定布鲁姆认知水平的教育问题。与以往的AEQG方法相比,该研究更注重对LLM生成过程的引导和控制,从而提高了生成问题的质量和多样性。
关键设计:研究中使用了不同复杂度的提示策略,例如,对于高认知水平的问题,提示中会包含更多的背景信息、约束条件和推理步骤。同时,研究还比较了不同规模的LLM在AEQG任务上的表现,并分析了自动评估与人工评估的差异。具体参数设置和网络结构取决于所使用的LLM模型,论文中可能未详细描述。
🖼️ 关键图片

📊 实验亮点
研究结果表明,通过适当的提示,LLM可以生成不同认知水平的相关且高质量的教育问题。尽管不同LLM的性能存在差异,但整体表现优于以往的AEQG方法。此外,研究还发现自动评估与人工评估存在显著差异,表明人工评估在教育问题质量评估中仍然不可或缺。
🎯 应用场景
该研究成果可应用于在线教育平台、智能辅导系统和教育资源库的建设,能够帮助教师快速生成高质量的教育问题,提高教学效率和学生的学习效果。未来,该技术还可用于个性化学习内容的生成和智能评估系统的开发。
📄 摘要(原文)
Developing questions that are pedagogically sound, relevant, and promote learning is a challenging and time-consuming task for educators. Modern-day large language models (LLMs) generate high-quality content across multiple domains, potentially helping educators to develop high-quality questions. Automated educational question generation (AEQG) is important in scaling online education catering to a diverse student population. Past attempts at AEQG have shown limited abilities to generate questions at higher cognitive levels. In this study, we examine the ability of five state-of-the-art LLMs of different sizes to generate diverse and high-quality questions of different cognitive levels, as defined by Bloom's taxonomy. We use advanced prompting techniques with varying complexity for AEQG. We conducted expert and LLM-based evaluations to assess the linguistic and pedagogical relevance and quality of the questions. Our findings suggest that LLms can generate relevant and high-quality educational questions of different cognitive levels when prompted with adequate information, although there is a significant variance in the performance of the five LLms considered. We also show that automated evaluation is not on par with human evaluation.