Enhancing Journalism with AI: A Study of Contextualized Image Captioning for News Articles using LLMs and LMMs
作者: Aliki Anagnostopoulou, Thiago Gouvea, Daniel Sonntag
分类: cs.CL, cs.CV
发布日期: 2024-08-08
💡 一句话要点
利用LLM和LMM增强新闻报道:针对新闻文章的上下文图像描述生成研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述生成 新闻报道 大型语言模型 多模态学习 上下文理解
📋 核心要点
- 现有图像描述生成模型难以充分利用新闻文章的上下文信息,导致生成的标题与新闻内容关联性不足。
- 论文提出利用大型语言模型(LLMs)和大型多模态模型(LMMs)为新闻图片生成上下文相关的标题,从而提升新闻报道的质量。
- 实验结果表明,控制上下文信息量可以提升模型性能,并强调了人机协作在新闻图像描述生成中的重要性。
📝 摘要(中文)
大型语言模型(LLMs)和大型多模态模型(LMMs)对人工智能领域、工业界和各个经济部门产生了重大影响。在新闻业中,集成人工智能带来了独特的挑战和机遇,尤其是在提高新闻报道的质量和效率方面。本研究探讨了LLMs和LMMs如何通过为新闻文章配图生成上下文相关的标题来辅助新闻实践。我们使用GoodNews数据集进行了实验,评估了LMMs(BLIP-2、GPT-4v或LLaVA)整合两种类型上下文(完整新闻文章或提取的命名实体)的能力。此外,我们将它们的性能与由标题生成模型(BLIP-2、OFA或ViT-GPT2)和LLMs(GPT-4或LLaMA)进行后验上下文处理的两阶段流程进行了比较。我们评估了各种模型,发现上下文模型的选择对于两阶段流程来说是一个重要因素,但在LMMs中并非如此,较小的开源模型与专有的、基于GPT的模型相比表现良好。此外,我们发现控制提供的上下文量可以提高性能。这些结果突出了完全自动化方法的局限性,并强调了交互式人机协作策略的必要性。
🔬 方法详解
问题定义:论文旨在解决新闻文章配图的自动标题生成问题,现有方法无法充分利用新闻文章的上下文信息,导致生成的标题缺乏针对性和准确性。这限制了AI在新闻行业的应用,降低了新闻报道的质量和效率。
核心思路:论文的核心思路是利用大型语言模型(LLMs)和大型多模态模型(LMMs)的强大上下文理解和生成能力,将新闻文章的文本信息融入到图像标题生成过程中。通过提供不同类型的上下文(如完整文章或提取的命名实体),引导模型生成更贴合新闻内容的标题。
技术框架:论文采用了两种主要的技术框架:1) 端到端的LMMs:直接使用LMMs(如BLIP-2、GPT-4v、LLaVA)将图像和上下文信息作为输入,生成标题。2) 两阶段流程:首先使用图像描述模型(如BLIP-2、OFA、ViT-GPT2)生成初步标题,然后使用LLMs(如GPT-4、LLaMA)对标题进行后验上下文处理,使其更符合新闻内容。
关键创新:论文的关键创新在于探索了不同类型的上下文信息(完整文章 vs. 命名实体)对图像标题生成的影响,并比较了端到端的LMMs和两阶段流程的性能。此外,论文还研究了控制上下文信息量对模型性能的影响,揭示了完全自动化方法的局限性。
关键设计:在实验设计方面,论文使用了GoodNews数据集,并评估了多种不同的LMMs和LLMs。对于两阶段流程,论文尝试了不同的图像描述模型和上下文处理模型组合。论文还通过控制输入模型的上下文信息量来研究其对性能的影响。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于模型本身的默认配置。
🖼️ 关键图片
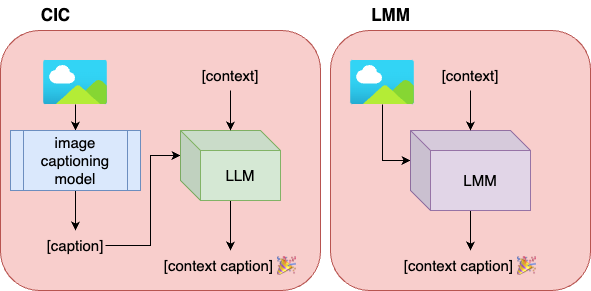

📊 实验亮点
实验结果表明,在LMMs中,较小的开源模型与专有的、基于GPT的模型相比表现良好。此外,控制提供的上下文信息量可以提高性能。例如,在特定设置下,使用提取的命名实体作为上下文可以获得比使用完整文章更好的效果。这些结果表明,并非提供的信息越多越好,需要根据具体情况进行调整。
🎯 应用场景
该研究成果可应用于新闻行业的自动化内容生成、新闻报道辅助写作、社交媒体新闻传播等领域。通过自动生成高质量的图像标题,可以提升新闻报道的吸引力、准确性和传播效率,并减轻记者和编辑的工作负担。未来,该技术有望与人机协作相结合,实现更智能化的新闻内容生产。
📄 摘要(原文)
Large language models (LLMs) and large multimodal models (LMMs) have significantly impacted the AI community, industry, and various economic sectors. In journalism, integrating AI poses unique challenges and opportunities, particularly in enhancing the quality and efficiency of news reporting. This study explores how LLMs and LMMs can assist journalistic practice by generating contextualised captions for images accompanying news articles. We conducted experiments using the GoodNews dataset to evaluate the ability of LMMs (BLIP-2, GPT-4v, or LLaVA) to incorporate one of two types of context: entire news articles, or extracted named entities. In addition, we compared their performance to a two-stage pipeline composed of a captioning model (BLIP-2, OFA, or ViT-GPT2) with post-hoc contextualisation with LLMs (GPT-4 or LLaMA). We assess a diversity of models, and we find that while the choice of contextualisation model is a significant factor for the two-stage pipelines, this is not the case in the LMMs, where smaller, open-source models perform well compared to proprietary, GPT-powered ones. Additionally, we found that controlling the amount of provided context enhances performance. These results highlight the limitations of a fully automated approach and underscore the necessity for an interactive, human-in-the-loop strategy.