LaDiMo: Layer-wise Distillation Inspired MoEfier
作者: Sungyoon Kim, Youngjun Kim, Kihyo Moon, Minsung Jang
分类: cs.CL
发布日期: 2024-08-08
备注: 21 pages, 10 figures
💡 一句话要点
LaDiMo:一种受层间知识蒸馏启发的MoE模型构建方法,降低训练成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 知识蒸馏 模型压缩 自然语言处理 Transformer 路由策略 模型加速
📋 核心要点
- 现有MoE模型训练成本高昂,且依赖大量硬件资源和数据,限制了其应用。
- LaDiMo利用知识蒸馏,将预训练的非MoE模型高效转化为MoE模型,降低训练成本。
- 实验表明,LaDiMo在保持精度的同时,显著减少了激活参数,提升了推理效率。
📝 摘要(中文)
大型语言模型的出现彻底改变了自然语言处理领域,但其日益增长的复杂性导致了巨大的训练成本、资源需求和环境影响。为了应对这一挑战,稀疏混合专家(MoE)模型已成为一种有希望的替代方案。由于从头开始训练MoE模型的成本可能过高,最近的研究探索了利用预训练的非MoE模型的知识。然而,现有方法存在局限性,例如需要大量的硬件资源和数据。我们提出了一种新颖的算法LaDiMo,它可以有效地将基于Transformer的非MoE模型转换为MoE模型,且只需极少的额外训练成本。LaDiMo包括两个阶段:层间专家构建和路由策略决策。通过利用知识蒸馏的概念,我们压缩模型并快速恢复其性能。此外,我们开发了一种自适应路由器,通过分析路由权重的分布并确定一个平衡精度和延迟的层间策略来优化推理效率。我们通过使用仅10万个token将LLaMA2-7B模型转换为MoE模型,同时保持准确性,并将激活参数减少超过20%,证明了我们方法的有效性。我们的方法为构建和部署MoE模型提供了一种灵活而高效的解决方案。
🔬 方法详解
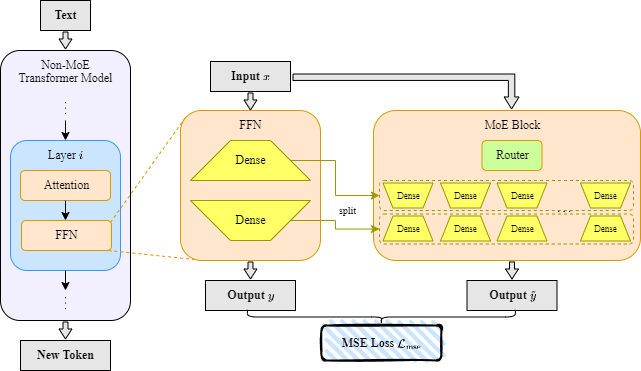
问题定义:论文旨在解决将预训练的稠密Transformer模型高效转化为稀疏MoE模型的问题。现有方法通常需要大量的训练数据和计算资源,从头训练MoE模型成本过高,而直接迁移知识的方法又难以保证性能和效率。
核心思路:论文的核心思路是利用知识蒸馏技术,将预训练的稠密模型中的知识迁移到MoE模型中,从而避免从头训练的巨大开销。通过层间蒸馏,可以更精细地控制知识迁移的过程,并加速MoE模型的训练。同时,设计自适应路由策略,在推理时平衡精度和延迟。
技术框架:LaDiMo方法包含两个主要阶段:1) 层间专家构建:利用知识蒸馏,将稠密模型的每一层知识迁移到MoE模型的对应层,构建专家网络。2) 路由策略决策:开发自适应路由器,根据路由权重的分布,动态调整每一层的路由策略,以优化推理效率。整体流程是从预训练的稠密模型开始,经过LaDiMo的转换,得到一个高效的MoE模型。
关键创新:LaDiMo的关键创新在于:1) 层间蒸馏:通过层间知识蒸馏,更有效地将稠密模型的知识迁移到MoE模型,加速训练过程。2) 自适应路由:根据路由权重的分布,动态调整每一层的路由策略,在精度和延迟之间取得平衡。
关键设计:在层间蒸馏中,使用了标准的知识蒸馏损失函数,例如KL散度损失。自适应路由器的设计考虑了每一层的路由权重分布,并根据预设的阈值动态调整路由策略。具体参数设置(如蒸馏温度、路由阈值)需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用LaDiMo方法将LLaMA2-7B模型转换为MoE模型,仅使用10万个token进行训练,即可将激活参数减少超过20%,同时保持了原模型的精度。这表明LaDiMo方法在降低模型复杂度和训练成本方面具有显著优势。
🎯 应用场景
LaDiMo方法可广泛应用于各种自然语言处理任务中,尤其适用于资源受限的场景。通过将大型稠密模型转化为高效的MoE模型,可以降低部署成本,提高推理速度,从而加速大型语言模型在移动设备、边缘计算等领域的应用。此外,该方法还可以用于模型压缩和加速,降低能源消耗,具有重要的社会价值。
📄 摘要(原文)
The advent of large language models has revolutionized natural language processing, but their increasing complexity has led to substantial training costs, resource demands, and environmental impacts. In response, sparse Mixture-of-Experts (MoE) models have emerged as a promising alternative to dense models. Since training MoE models from scratch can be prohibitively expensive, recent studies have explored leveraging knowledge from pre-trained non-MoE models. However, existing approaches have limitations, such as requiring significant hardware resources and data. We propose a novel algorithm, LaDiMo, which efficiently converts a Transformer-based non-MoE model into a MoE model with minimal additional training cost. LaDiMo consists of two stages: layer-wise expert construction and routing policy decision. By harnessing the concept of Knowledge Distillation, we compress the model and rapidly recover its performance. Furthermore, we develop an adaptive router that optimizes inference efficiency by profiling the distribution of routing weights and determining a layer-wise policy that balances accuracy and latency. We demonstrate the effectiveness of our method by converting the LLaMA2-7B model to a MoE model using only 100K tokens, reducing activated parameters by over 20% while keeping accuracy. Our approach offers a flexible and efficient solution for building and deploying MoE models.