Large Language Models for Biomedical Text Simplification: Promising But Not There Yet
作者: Zihao Li, Samuel Belkadi, Nicolo Micheletti, Lifeng Han, Matthew Shardlow, Goran Nenadic
分类: cs.CL, cs.AI
发布日期: 2024-08-07 (更新: 2024-09-24)
备注: Extended system report for PLABA-2023. arXiv admin note: substantial text overlap with arXiv:2309.13202
💡 一句话要点
利用大型语言模型进行生物医学文本简化研究:有前景但仍需努力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物医学文本简化 大型语言模型 领域微调 可控属性 ChatGPT 文本生成 自然语言处理
📋 核心要点
- 生物医学文本复杂,难以被非专业人士理解,现有简化方法效果有限,需要更有效的模型。
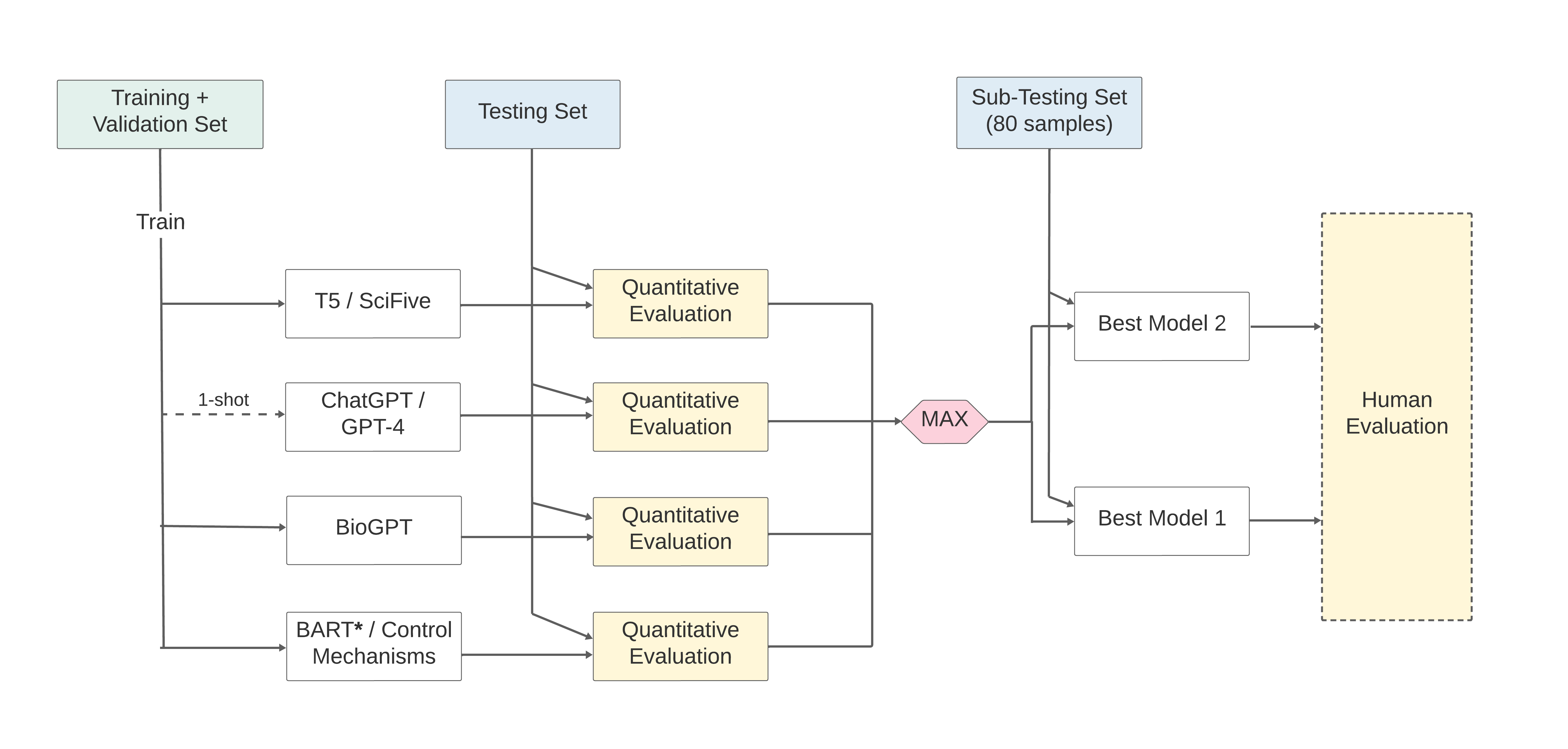
- 探索领域微调的T5类模型、可控属性BART模型和ChatGPT提示在生物医学文本简化中的应用。
- 实验结果表明,领域微调模型和可控属性BART模型在自动和人工评估中均表现良好,ChatGPT提示在特定指标上表现突出。
📝 摘要(中文)
本系统报告描述了我们参与TAC 2023的PLABA2023生物医学摘要简化任务所使用的模型和方法。我们提交的系统输出来自以下三个类别:1) 领域微调的T5类模型,包括Biomedical-T5和Lay-SciFive;2) 具有可控属性(通过tokens)的微调BARTLarge模型BART-w-CTs;3) ChatGPT提示。我们还介绍了我们为该任务进行的BioGPT微调工作。在使用SARI分数的官方自动评估中,BeeManc在所有团队中排名第二,我们的模型LaySciFive在所有13个评估系统中排名第三。在官方人工评估中,我们的模型BART-w-CTs在句子简洁度(得分92.84)上排名第二,在术语简洁度(得分82.33)上在所有7个评估系统中排名第三;与最高分93.53相比,它在流畅度方面也获得了很高的分数91.57。在第二轮提交中,我们使用ChatGPT提示的团队在几个类别中排名第二,包括简化的术语准确度得分92.26和完整性得分96.58,并且通过人工评估获得了与重新评估的PLABA-base-1(95.73)非常相似的忠实度得分95.3。
🔬 方法详解
问题定义:论文旨在解决生物医学文本的复杂性问题,使其更易于非专业人士理解。现有方法,如传统的文本简化技术,在处理生物医学文本时,往往难以保证简化后的文本在准确性、流畅性和简洁性之间取得平衡,并且难以控制简化过程中的属性(例如术语的简化程度)。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大生成能力和领域知识,通过微调和提示工程,使其能够生成更简洁、易懂且忠实于原文的生物医学文本。同时,通过引入可控属性的机制,允许用户在一定程度上控制简化过程,例如指定术语的简化程度。
技术框架:论文采用了多种技术框架,包括:1) 基于T5架构的领域微调模型(Biomedical-T5和Lay-SciFive);2) 基于BARTLarge架构的具有可控属性的模型(BART-w-CTs);3) 基于ChatGPT的提示工程方法。对于BART-w-CTs,通过在输入序列中添加特殊的控制token,来控制输出文本的属性。
关键创新:论文的关键创新在于探索了多种大型语言模型在生物医学文本简化任务中的应用,并针对性地提出了可控属性的BART模型,允许用户在一定程度上控制简化过程。此外,论文还尝试了ChatGPT的提示工程方法,并取得了较好的效果。
关键设计:对于T5类模型,采用了在生物医学领域数据上进行微调的策略,使其更好地适应生物医学文本的特点。对于BART-w-CTs,设计了一系列控制token,用于控制输出文本的简洁性、术语简化程度等属性。对于ChatGPT提示,精心设计了提示语,以引导ChatGPT生成更符合要求的简化文本。
🖼️ 关键图片


📊 实验亮点
该研究在PLABA2023生物医学摘要简化任务中取得了显著成果。BeeManc在自动评估中排名第二,LaySciFive排名第三。BART-w-CTs在人工评估的句子简洁度和术语简洁度上均排名第二或第三,且流畅度得分接近最高水平。ChatGPT提示在简化的术语准确度和完整性方面表现突出,忠实度得分与基线模型相当。
🎯 应用场景
该研究成果可应用于多种场景,例如:为患者提供易于理解的医疗信息,帮助非专业人士阅读生物医学文献,辅助医学教育等。通过简化生物医学文本,可以提高医疗信息的普及程度,促进医患沟通,并为医学研究提供更广泛的受众。
📄 摘要(原文)
In this system report, we describe the models and methods we used for our participation in the PLABA2023 task on biomedical abstract simplification, part of the TAC 2023 tracks. The system outputs we submitted come from the following three categories: 1) domain fine-tuned T5-like models including Biomedical-T5 and Lay-SciFive; 2) fine-tuned BARTLarge model with controllable attributes (via tokens) BART-w-CTs; 3) ChatGPTprompting. We also present the work we carried out for this task on BioGPT finetuning. In the official automatic evaluation using SARI scores, BeeManc ranks 2nd among all teams and our model LaySciFive ranks 3rd among all 13 evaluated systems. In the official human evaluation, our model BART-w-CTs ranks 2nd on Sentence-Simplicity (score 92.84), 3rd on Term-Simplicity (score 82.33) among all 7 evaluated systems; It also produced a high score 91.57 on Fluency in comparison to the highest score 93.53. In the second round of submissions, our team using ChatGPT-prompting ranks the 2nd in several categories including simplified term accuracy score 92.26 and completeness score 96.58, and a very similar score on faithfulness score 95.3 to re-evaluated PLABA-base-1 (95.73) via human evaluations. Our codes, fine-tuned models, prompts, and data splits from the system development stage will be available at https://github.com/ HECTA-UoM/PLABA-MU