PAGED: A Benchmark for Procedural Graphs Extraction from Documents
作者: Weihong Du, Wenrui Liao, Hongru Liang, Wenqiang Lei
分类: cs.CL
发布日期: 2024-08-07 (更新: 2024-08-08)
备注: Accepted to The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)
💡 一句话要点
提出PAGED基准,用于评估和提升文档中程序图的自动抽取能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序图抽取 文档理解 大型语言模型 基准数据集 自精炼策略
📋 核心要点
- 现有程序图抽取方法依赖人工规则和数据量有限,导致无法有效抽取最优程序图。
- 论文核心在于构建高质量数据集PAGED,并探索LLM在程序图抽取中的潜力,提出自精炼策略。
- 实验表明,LLM在文本元素识别方面有优势,但在构建逻辑结构方面仍有提升空间,PAGED为后续研究提供基准。
📝 摘要(中文)
本文提出了一个新的基准PAGED,用于从文档中自动抽取程序图。自动抽取程序图为用户提供了一种低成本的方式,通过浏览可视化图表轻松理解复杂流程。尽管现有研究取得了一些进展,但仍然存在两个问题:现有研究是否充分解决了该任务?新兴的大型语言模型(LLMs)是否能为该任务带来新的机遇?为此,PAGED配备了一个大型高质量数据集和标准评估方法。通过对五个最先进的基线进行研究,揭示了它们由于严重依赖手写规则和有限的可用数据而无法很好地提取最佳程序图。此外,还将三个先进的LLM引入PAGED,并通过一种新颖的自精炼策略对其进行增强。结果表明,LLM在识别文本元素方面具有优势,但在构建逻辑结构方面存在差距。希望PAGED可以作为自动程序图提取的一个重要里程碑,并且PAGED中的研究可以为非顺序元素之间的逻辑推理研究提供见解。
🔬 方法详解
问题定义:论文旨在解决从文档中自动抽取程序图的问题。现有方法的痛点在于过度依赖人工设计的规则,泛化能力差,且缺乏大规模高质量的数据集进行训练和评估,导致抽取效果不佳。现有方法难以有效捕捉文档中非连续元素之间的逻辑关系,限制了程序图的完整性和准确性。
核心思路:论文的核心思路是构建一个大规模高质量的程序图抽取数据集PAGED,并利用大型语言模型(LLMs)的强大文本理解能力,结合自精炼策略,提升程序图的抽取效果。通过PAGED基准,可以系统地评估现有方法和LLM在程序图抽取任务上的性能,并为未来的研究提供方向。
技术框架:整体框架包括数据集构建和模型评估两个主要部分。数据集构建涉及收集包含程序流程的文档,并进行人工标注,构建高质量的程序图数据集PAGED。模型评估部分则包括选择合适的基线模型(包括传统方法和LLM),在PAGED数据集上进行训练和测试,并采用标准评估指标进行性能评估。此外,论文还提出了一种自精炼策略,用于增强LLM的程序图抽取能力。
关键创新:论文的关键创新在于:1) 构建了大规模高质量的程序图抽取数据集PAGED,填补了该领域数据集的空白。2) 探索了大型语言模型(LLMs)在程序图抽取任务中的潜力,并提出了一种自精炼策略,提升了LLM的抽取效果。3) 通过对现有方法和LLM的系统评估,揭示了它们在程序图抽取任务上的优缺点,为未来的研究提供了有价值的见解。
关键设计:自精炼策略的具体细节未知,论文中可能没有详细描述其参数设置、损失函数或网络结构等技术细节。但可以推测,该策略可能涉及利用LLM生成初始的程序图,然后通过某种机制(例如,人工反馈或自动评估)对生成的程序图进行修正和完善,从而提升其质量。
🖼️ 关键图片


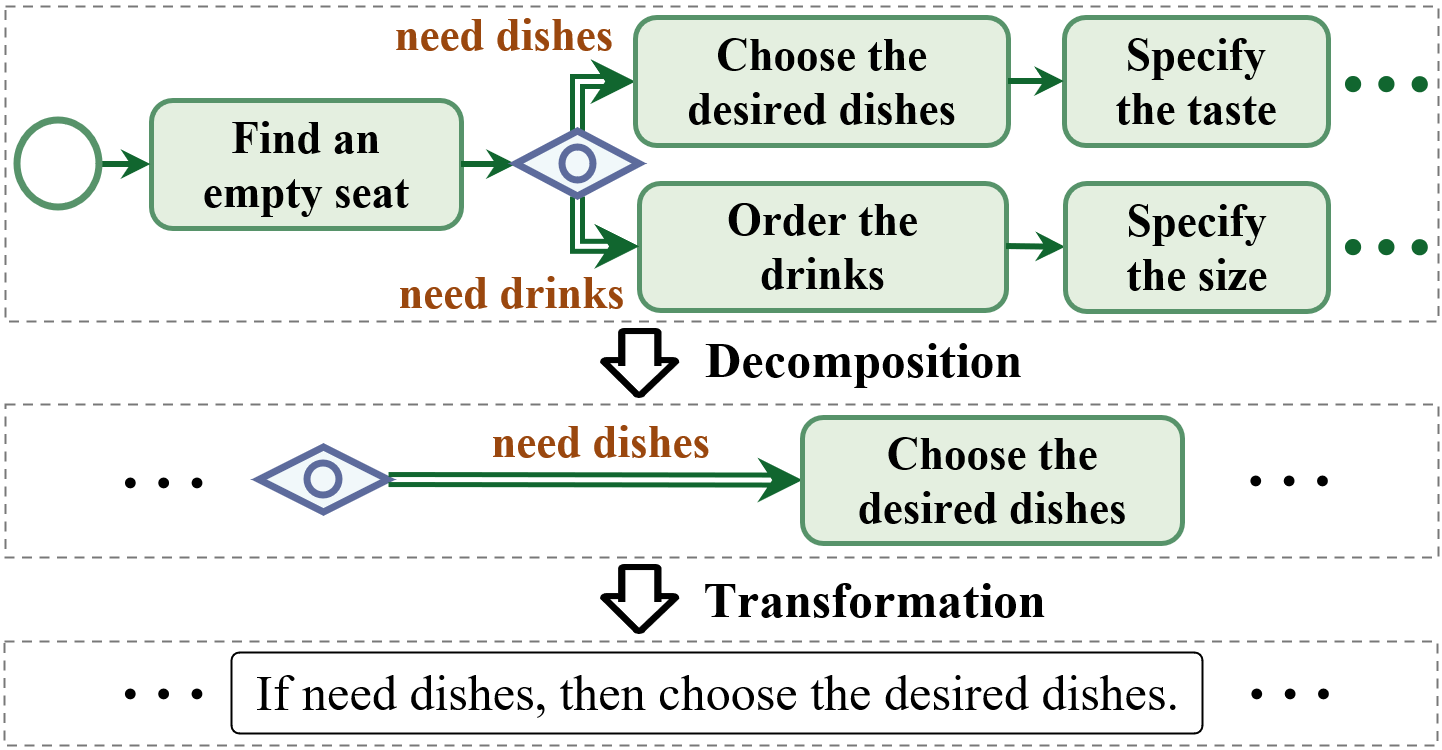
📊 实验亮点
论文通过在PAGED数据集上评估五个现有基线模型和三个大型语言模型,发现现有方法由于依赖人工规则和数据限制,性能不佳。引入LLM并结合自精炼策略后,在文本元素识别方面表现出优势,但在逻辑结构构建方面仍有提升空间。PAGED数据集和评估结果为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于自动化文档理解、智能助手、教育领域等。例如,可以帮助用户快速理解操作手册、技术文档等复杂流程,提高工作效率。在教育领域,可以将复杂的知识点转化为易于理解的程序图,辅助学生学习。未来,该技术有望应用于更广泛的领域,例如智能客服、流程自动化等。
📄 摘要(原文)
Automatic extraction of procedural graphs from documents creates a low-cost way for users to easily understand a complex procedure by skimming visual graphs. Despite the progress in recent studies, it remains unanswered: whether the existing studies have well solved this task (Q1) and whether the emerging large language models (LLMs) can bring new opportunities to this task (Q2). To this end, we propose a new benchmark PAGED, equipped with a large high-quality dataset and standard evaluations. It investigates five state-of-the-art baselines, revealing that they fail to extract optimal procedural graphs well because of their heavy reliance on hand-written rules and limited available data. We further involve three advanced LLMs in PAGED and enhance them with a novel self-refine strategy. The results point out the advantages of LLMs in identifying textual elements and their gaps in building logical structures. We hope PAGED can serve as a major landmark for automatic procedural graph extraction and the investigations in PAGED can offer insights into the research on logic reasoning among non-sequential elements.