A Comparison of LLM Finetuning Methods & Evaluation Metrics with Travel Chatbot Use Case
作者: Sonia Meyer, Shreya Singh, Bertha Tam, Christopher Ton, Angel Ren
分类: cs.CL, cs.AI
发布日期: 2024-08-07
💡 一句话要点
针对旅游聊天机器人,对比LLM微调方法与评估指标,并提出RLHF优化方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 旅游聊天机器人 LLM微调 QLoRA RAFT RLHF 模型评估 GPT-4评估
📋 核心要点
- 现有旅游聊天机器人缺乏个性化和准确性,传统评估指标难以反映真实用户体验。
- 采用QLoRA、RAFT等微调方法,结合Reddit数据构建个性化旅游对话模型,并引入GPT-4进行评估。
- 实验表明,Mistral RAFT模型经RLHF优化后,在人工评估和GPT-4评估中表现最佳,显著提升用户体验。
📝 摘要(中文)
本研究对比了大型语言模型(LLM)的微调方法,包括量化低秩适配器(QLoRA)、检索增强微调(RAFT)和基于人类反馈的强化学习(RLHF),并比较了LLM的评估方法,包括“黄金答案”的端到端(E2E)基准方法、传统自然语言处理(NLP)指标、RAG评估(Ragas)、OpenAI GPT-4评估指标和人工评估,所有这些都以旅游聊天机器人用例为背景。旅游数据集来源于Reddit API,通过请求旅游相关subreddit的帖子来获取旅游相关的对话提示和个性化的旅游体验,并针对每种微调方法进行了扩充。我们使用了两个预训练的LLM进行微调研究:LLaMa 2 7B和Mistral 7B。QLoRA和RAFT被应用于这两个预训练模型。这些模型的推理结果根据上述指标进行了广泛评估。根据人工评估和一些GPT-4指标,最佳模型是Mistral RAFT,因此它经历了基于人类反馈的强化学习(RLHF)训练流程,并最终被评估为最佳模型。主要发现包括:1)定量和Ragas指标与人工评估不一致;2)Open AI GPT-4评估与人工评估最一致;3)人工评估至关重要;4)传统NLP指标不足;5)Mistral通常优于LLaMa;6)RAFT优于QLoRA,但仍需要后处理;7)RLHF显著提高了模型性能。下一步包括提高数据质量,增加数据数量,探索RAG方法,并将数据收集重点放在特定城市,这将通过缩小范围来提高数据质量,同时创建一个有用的产品。
🔬 方法详解
问题定义:现有旅游聊天机器人通常泛化能力较强,但缺乏针对特定用户需求的个性化推荐和对话能力。传统的NLP评估指标(如BLEU、ROUGE)难以准确衡量聊天机器人的对话质量和用户满意度。因此,需要一种能够有效利用用户数据,并能更准确评估模型性能的微调和评估方法。
核心思路:本研究的核心思路是结合多种微调方法(QLoRA、RAFT)和评估指标(传统NLP指标、Ragas、GPT-4评估、人工评估),以旅游聊天机器人为用例,找到最适合该场景的微调策略和评估方法。通过Reddit API获取真实用户数据,并利用RLHF进一步优化模型,使其更符合人类偏好。
技术框架:整体框架包括数据收集与处理、模型微调、模型评估和RLHF优化四个主要阶段。数据收集阶段从Reddit API获取旅游相关数据,并进行清洗和扩充。模型微调阶段使用QLoRA和RAFT对LLaMa 2 7B和Mistral 7B进行微调。模型评估阶段采用多种评估指标,包括传统NLP指标、Ragas、GPT-4评估和人工评估。RLHF优化阶段使用人工反馈数据对表现最佳的模型进行进一步优化。
关键创新:本研究的关键创新在于综合比较了多种LLM微调方法和评估指标在旅游聊天机器人用例中的表现,并发现GPT-4评估与人工评估具有较高的一致性。此外,通过RLHF对RAFT模型进行优化,显著提升了模型性能。
关键设计:在数据收集方面,使用Reddit API获取真实用户数据,保证了数据的多样性和真实性。在模型微调方面,QLoRA和RAFT分别代表了参数高效微调和检索增强微调两种不同的策略。在模型评估方面,GPT-4评估作为一种新兴的评估方法,能够更准确地反映模型的对话质量和用户满意度。RLHF使用人工标注的偏好数据,通过奖励模型来指导模型的训练。
🖼️ 关键图片


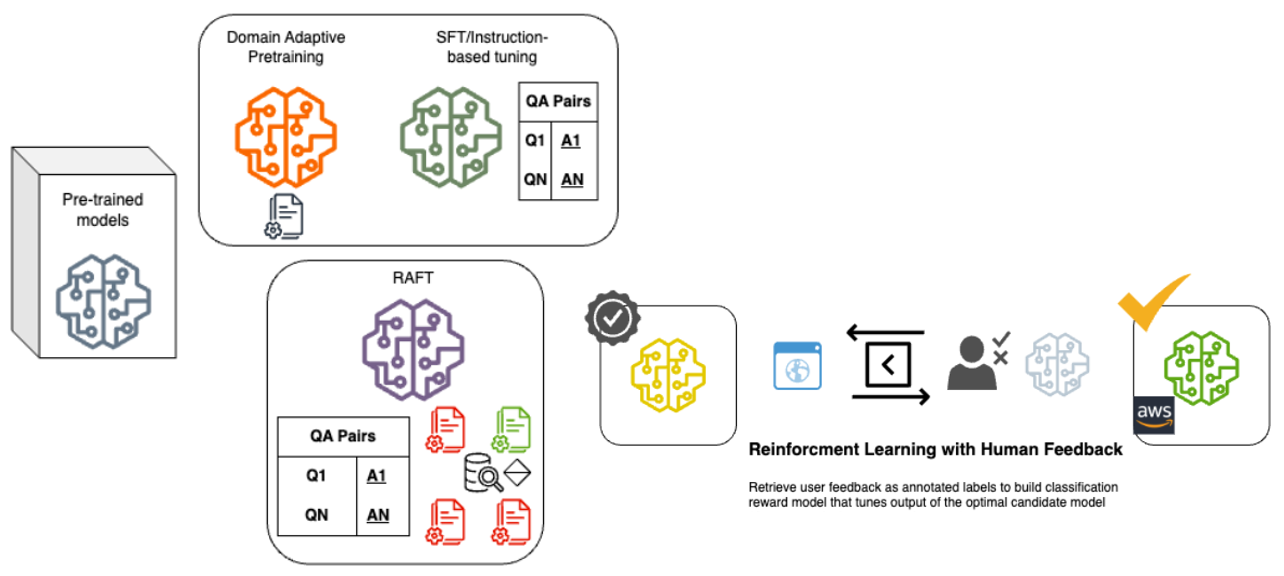
📊 实验亮点
实验结果表明,Mistral RAFT模型在经过RLHF优化后,在人工评估和GPT-4评估中表现最佳。研究发现,传统的NLP指标和Ragas指标与人工评估结果不一致,而GPT-4评估与人工评估结果具有较高的一致性。RAFT优于QLoRA,但需要后处理。RLHF显著提高了模型性能。
🎯 应用场景
该研究成果可应用于开发更智能、更个性化的旅游聊天机器人,为用户提供定制化的旅游建议和服务。此外,该研究提出的微调和评估方法也适用于其他领域的对话系统,例如客服机器人、教育助手等,具有广泛的应用前景。
📄 摘要(原文)
This research compares large language model (LLM) fine-tuning methods, including Quantized Low Rank Adapter (QLoRA), Retrieval Augmented fine-tuning (RAFT), and Reinforcement Learning from Human Feedback (RLHF), and additionally compared LLM evaluation methods including End to End (E2E) benchmark method of "Golden Answers", traditional natural language processing (NLP) metrics, RAG Assessment (Ragas), OpenAI GPT-4 evaluation metrics, and human evaluation, using the travel chatbot use case. The travel dataset was sourced from the the Reddit API by requesting posts from travel-related subreddits to get travel-related conversation prompts and personalized travel experiences, and augmented for each fine-tuning method. We used two pretrained LLMs utilized for fine-tuning research: LLaMa 2 7B, and Mistral 7B. QLoRA and RAFT are applied to the two pretrained models. The inferences from these models are extensively evaluated against the aforementioned metrics. The best model according to human evaluation and some GPT-4 metrics was Mistral RAFT, so this underwent a Reinforcement Learning from Human Feedback (RLHF) training pipeline, and ultimately was evaluated as the best model. Our main findings are that: 1) quantitative and Ragas metrics do not align with human evaluation, 2) Open AI GPT-4 evaluation most aligns with human evaluation, 3) it is essential to keep humans in the loop for evaluation because, 4) traditional NLP metrics insufficient, 5) Mistral generally outperformed LLaMa, 6) RAFT outperforms QLoRA, but still needs postprocessing, 7) RLHF improves model performance significantly. Next steps include improving data quality, increasing data quantity, exploring RAG methods, and focusing data collection on a specific city, which would improve data quality by narrowing the focus, while creating a useful product.