Non-Determinism of "Deterministic" LLM Settings
作者: Berk Atil, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, Zhe Wu, Lixinyu Xu, Breck Baldwin
分类: cs.CL, cs.AI, cs.LG, cs.SE
发布日期: 2024-08-06 (更新: 2025-04-02)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示“确定性”LLM设置下的非确定性问题,并提出量化指标
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 非确定性 确定性 可靠性 量化指标
📋 核心要点
- 现有研究缺乏对LLM在“确定性”设置下非确定性输出的系统性调查,影响模型可靠性。
- 通过多次运行实验,量化了不同LLM在常见任务中的非确定性程度,并分析了性能差异。
- 提出了TARr@N和TARa@N指标,用于量化LLM输出的确定性,为后续研究提供参考。
📝 摘要(中文)
大型语言模型(LLM)从业者普遍观察到,即使在预期为确定性的设置下,对于相同的输入,输出也可能存在差异。然而,这种现象的普遍程度以及对结果的影响尚未得到系统性的研究。本文研究了五个配置为确定性的LLM在应用于八个常见任务的十次运行中的非确定性,包括零样本和少样本设置。结果表明,自然运行中准确率变化高达15%,最佳性能与最差性能之间的差距高达70%。事实上,没有一个LLM能够在所有任务中始终如一地提供可重复的准确率,更不用说相同的输出字符串。与内部人士分享初步结果表明,非确定性可能是通过输入缓冲区中混合数据来有效利用计算资源所必需的,因此这个问题在短期内不会消失。为了更好地量化我们的观察结果,我们引入了专注于量化确定性的指标,TARr@N用于原始输出在N次运行中的总协议率,TARa@N用于解析答案的总协议率。我们的代码和数据可在https://github.com/breckbaldwin/llm-stability公开获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在被配置为“确定性”设置时,仍然表现出非确定性输出的问题。现有方法的痛点在于,从业者虽然观察到这种现象,但缺乏系统性的研究和量化,导致无法准确评估和控制LLM的可靠性。这种非确定性会严重影响LLM在实际应用中的效果,尤其是在对结果一致性要求较高的场景下。
核心思路:论文的核心思路是通过大量的实验来量化LLM的非确定性程度,并分析其对模型性能的影响。通过在多个LLM和多个任务上进行多次运行,记录并比较每次运行的输出结果,从而揭示非确定性的普遍性和影响范围。同时,论文还提出了新的指标来量化LLM的确定性,为后续研究提供了一种标准化的评估方法。
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择多个LLM模型,并将其配置为“确定性”设置。2) 选择多个常见的NLP任务,例如问答、文本生成等。3) 在每个LLM和每个任务上进行多次运行(例如10次),记录每次运行的输入和输出。4) 使用提出的指标(TARr@N和TARa@N)来量化每次运行的确定性程度。5) 分析实验结果,评估非确定性对模型性能的影响。
关键创新:论文最重要的技术创新点在于对LLM非确定性的系统性研究和量化。以往的研究主要关注LLM的性能和效率,而忽略了其确定性问题。论文通过大量的实验数据,证明了即使在“确定性”设置下,LLM仍然存在显著的非确定性。此外,论文提出的TARr@N和TARa@N指标为量化LLM的确定性提供了一种新的方法,可以用于比较不同LLM的确定性程度,以及评估不同优化方法对LLM确定性的影响。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM模型,例如不同架构和不同规模的模型。2) 选择覆盖不同领域的NLP任务,以评估非确定性在不同任务上的影响。3) 进行足够多次的运行,以保证实验结果的统计显著性。4) 设计合适的指标来量化LLM的确定性,例如TARr@N和TARa@N,其中TARr@N关注原始输出的协议率,而TARa@N关注解析后的答案的协议率。
🖼️ 关键图片

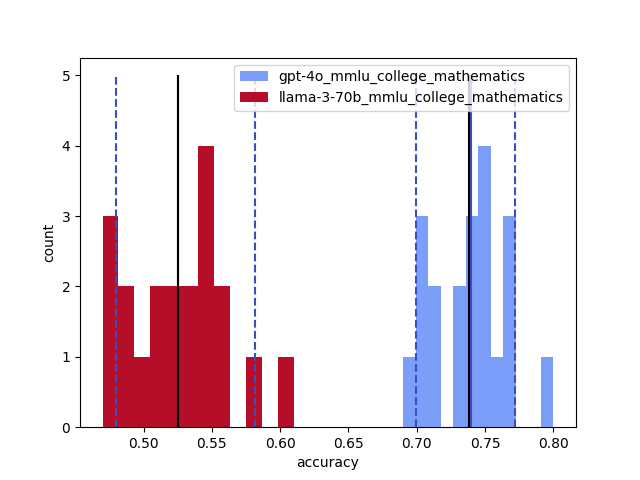
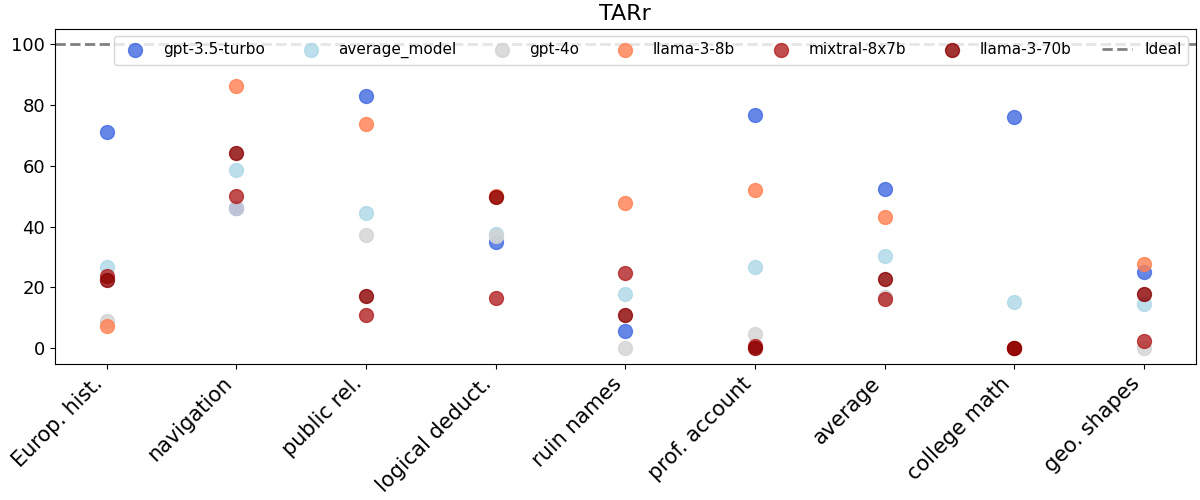
📊 实验亮点
实验结果表明,即使在配置为确定性的LLM中,准确率变化高达15%,最佳性能与最差性能之间的差距高达70%。没有一个LLM能够在所有任务中始终如一地提供可重复的准确率。这些结果突显了LLM非确定性的严重性,并强调了对其进行系统性研究的必要性。
🎯 应用场景
该研究成果可应用于对结果一致性要求高的LLM应用场景,如金融分析、法律咨询、医疗诊断等。通过量化LLM的非确定性,可以帮助开发者选择更可靠的模型,并优化模型配置以提高其确定性。此外,该研究还可以促进LLM的可靠性研究,推动开发更稳定、可预测的LLM系统。
📄 摘要(原文)
LLM (large language model) practitioners commonly notice that outputs can vary for the same inputs under settings expected to be deterministic. Yet the questions of how pervasive this is, and with what impact on results, have not to our knowledge been systematically investigated. We investigate non-determinism in five LLMs configured to be deterministic when applied to eight common tasks in across 10 runs, in both zero-shot and few-shot settings. We see accuracy variations up to 15% across naturally occurring runs with a gap of best possible performance to worst possible performance up to 70%. In fact, none of the LLMs consistently delivers repeatable accuracy across all tasks, much less identical output strings. Sharing preliminary results with insiders has revealed that non-determinism perhaps essential to the efficient use of compute resources via co-mingled data in input buffers so this issue is not going away anytime soon. To better quantify our observations, we introduce metrics focused on quantifying determinism, TARr@N for the total agreement rate at N runs over raw output, and TARa@N for total agreement rate of parsed-out answers. Our code and data are publicly available at https://github.com/breckbaldwin/llm-stability.