LLM-based MOFs Synthesis Condition Extraction using Few-Shot Demonstrations
作者: Lei Shi, Zhimeng Liu, Yi Yang, Weize Wu, Yuyang Zhang, Hongbo Zhang, Jing Lin, Siyu Wu, Zihan Chen, Ruiming Li, Nan Wang, Zipeng Liu, Huobin Tan, Hongyi Gao, Yue Zhang, Ge Wang
分类: cs.CL, cs.AI
发布日期: 2024-08-06 (更新: 2025-02-25)
💡 一句话要点
提出基于Few-Shot LLM的MOFs合成条件提取方法,显著提升提取性能和材料设计质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金属有机框架 MOFs 合成路线提取 大型语言模型 Few-Shot学习 人机交互 信息检索
📋 核心要点
- 现有方法依赖于缺乏专业知识的零样本LLM,在MOFs合成路线提取方面表现不足。
- 本文提出一种基于Few-Shot LLM的上下文学习方法,通过人机交互和信息检索提升模型性能。
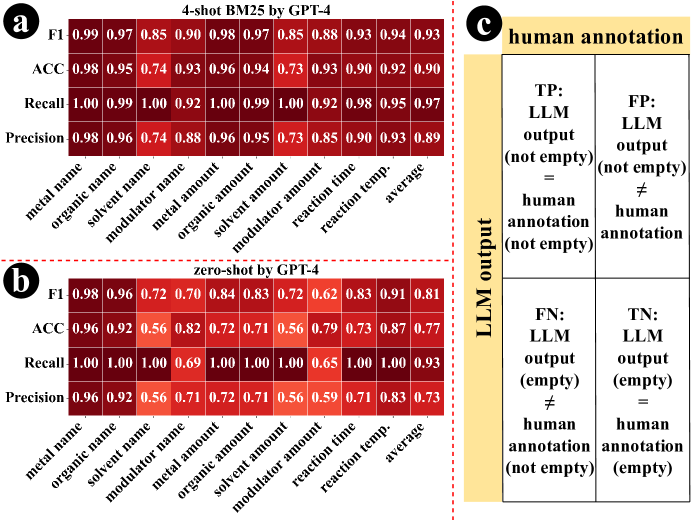
- 实验表明,该方法在合成提取、结构推断和材料设计方面显著优于零样本LLM和基线方法。
📝 摘要(中文)
从文献中提取金属有机框架(MOFs)的合成路线对于设计具有理想功能的MOFs至关重要。大型语言模型(LLMs)的出现为解决这个长期存在的问题提供了一种颠覆性的新方案。与主要采用缺乏专业材料知识的原始零样本LLM的最新研究不同,本文介绍了一种few-shot LLM的上下文学习范式。首先,提出了一种人机交互数据管理方法,以确保高质量的演示数据。其次,应用信息检索算法来选择和量化每次提取的few-shot演示。在从近90,000个定义明确的MOFs中随机抽样的三个数据集上,我们进行了三重评估以验证我们的方法。所提出的few-shot LLM在合成提取、结构推断和材料设计方面的性能均显著优于零样本LLM和基线方法。在比表面积这一关键物理性质上,LLM指导的实验室合成材料超过了文献中报道的同类高质量MOFs的91.1%。
🔬 方法详解
问题定义:论文旨在解决从文献中自动提取金属有机框架(MOFs)合成路线的问题。现有方法,特别是基于零样本LLM的方法,由于缺乏专业的材料科学知识,在提取准确性和效率方面存在瓶颈,难以满足实际应用的需求。
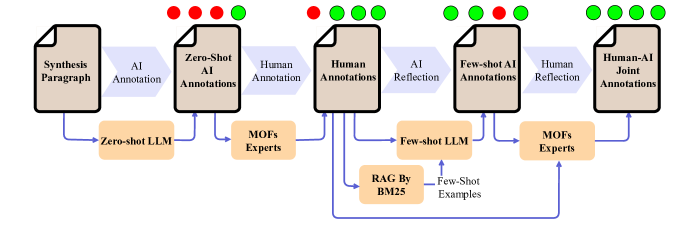
核心思路:论文的核心思路是利用Few-Shot学习,通过少量高质量的示例(demonstrations)来引导LLM学习MOFs合成路线提取的模式。通过让人工参与数据标注和筛选,保证示例的质量。同时,使用信息检索算法,针对不同的提取任务,选择最相关的示例,从而提高LLM的提取性能。
技术框架:整体框架包含以下几个主要步骤:1) 数据收集与标注:从文献中收集MOFs合成路线数据,并进行人工标注,构建高质量的训练数据集。2) 人机交互数据管理:设计人机交互界面,让人工专家参与到数据清洗和筛选过程中,确保示例的质量和多样性。3) 信息检索:针对每个提取任务,使用信息检索算法从标注数据集中选择最相关的Few-Shot示例。4) Few-Shot LLM学习:将选择的示例作为上下文输入到LLM中,引导LLM学习MOFs合成路线提取的模式。5) 模型评估:在多个数据集上评估模型的性能,并与零样本LLM和基线方法进行比较。
关键创新:该论文的关键创新在于:1) 引入了Few-Shot学习范式到MOFs合成路线提取任务中,克服了零样本LLM的局限性。2) 提出了人机交互的数据管理方法,保证了示例的质量。3) 使用信息检索算法,针对不同的提取任务,选择最相关的示例,提高了模型的泛化能力。
关键设计:论文中关于Few-Shot示例的选择策略是关键设计之一。具体而言,使用信息检索算法(具体算法类型未知)计算待提取MOF与已标注MOF之间的相似度,选择相似度最高的几个MOF作为Few-Shot示例。此外,论文还可能涉及LLM的选择(具体模型未知)和Prompt的设计,这些细节对最终的提取性能都有重要影响。损失函数和网络结构方面的信息未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在三个数据集上均显著优于零样本LLM和基线方法。LLM指导的实验室合成材料,在比表面积这一关键物理性质上,超过了文献中报道的同类高质量MOFs的91.1%。这表明该方法不仅可以准确提取合成路线,还可以指导实际的材料合成,具有重要的应用价值。
🎯 应用场景
该研究成果可应用于材料科学领域,加速新材料的发现和设计。通过自动提取文献中的合成路线,研究人员可以快速了解现有材料的制备方法,并在此基础上进行改进和创新。此外,该技术还可以用于构建MOFs合成路线数据库,为材料科学研究提供更便捷的数据支持。
📄 摘要(原文)
The extraction of Metal-Organic Frameworks (MOFs) synthesis route from literature has been crucial for the logical MOFs design with desirable functionality. The recent advent of large language models (LLMs) provides disruptively new solution to this long-standing problem. While the latest researches mostly stick to primitive zero-shot LLMs lacking specialized material knowledge, we introduce in this work the few-shot LLM in-context learning paradigm. First, a human-AI interactive data curation approach is proposed to secure high-quality demonstrations. Second, an information retrieval algorithm is applied to pick and quantify few-shot demonstrations for each extraction. Over three datasets randomly sampled from nearly 90,000 well-defined MOFs, we conduct triple evaluations to validate our method. The synthesis extraction, structure inference, and material design performance of the proposed few-shot LLMs all significantly outplay zero-shot LLM and baseline methods. The lab-synthesized material guided by LLM surpasses 91.1% high-quality MOFs of the same class reported in the literature, on the key physical property of specific surface area.