Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations
作者: Leo Donisch, Sigurd Schacht, Carsten Lanquillon
分类: cs.CL
发布日期: 2024-08-06
💡 一句话要点
综述大型语言模型推理优化技术,分析其影响、挑战与实践考量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理优化 模型压缩 量化 剪枝 知识蒸馏 架构优化 自然语言处理
📋 核心要点
- 大型语言模型规模庞大,推理成本高昂,如何在资源受限的环境中高效部署是核心问题。
- 论文综述了量化、剪枝、知识蒸馏和架构优化等多种模型压缩与加速技术,旨在降低资源需求。
- 通过对各种优化方法的深入分析,论文旨在帮助研究人员和从业者更好地理解和应用这些技术。
📝 摘要(中文)
大型语言模型在自然语言处理领域应用广泛,因为它们无需重新训练即可适应新任务。然而,其庞大的规模和复杂性带来了独特的挑战和机遇,促使研究人员和从业者探索新的模型训练、优化和部署方法。本文献综述侧重于各种用于减少资源需求和压缩大型语言模型的技术,包括量化、剪枝、知识蒸馏和架构优化。主要目标是深入探讨每种方法,并突出其独特的挑战和实际应用。所讨论的方法被归类为一个分类法,该分类法概述了优化领域,并有助于更好地理解研究轨迹。
🔬 方法详解
问题定义:大型语言模型虽然性能强大,但其巨大的规模导致推理时需要大量的计算资源和内存,这限制了它们在边缘设备或资源受限环境中的部署。现有方法在压缩模型的同时,往往会牺牲一定的精度,如何在精度和效率之间取得平衡是一个关键问题。
核心思路:该综述的核心思路是对现有的各种模型压缩和加速技术进行系统性的梳理和分析,包括量化、剪枝、知识蒸馏和架构优化等。通过深入理解每种方法的原理、优缺点以及适用场景,为研究人员和从业者提供选择和应用这些技术的指导。
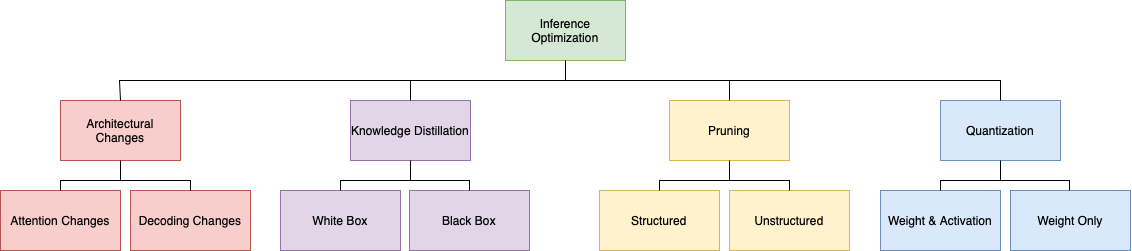
技术框架:该综述没有提出新的技术框架,而是对现有技术进行分类和总结。它构建了一个优化方法的分类体系,旨在帮助读者更好地理解优化领域的整体情况,并了解研究的演进方向。主要包括量化、剪枝、知识蒸馏和架构优化等几个主要类别,每个类别下又包含多种具体的方法。
关键创新:该综述的创新之处在于其系统性和全面性。它不是简单地罗列各种技术,而是深入分析了每种技术的原理、优缺点以及适用场景,并探讨了它们之间的联系和区别。此外,该综述还指出了各种技术面临的挑战和未来的研究方向。
关键设计:该综述的关键设计在于其分类体系。通过将各种优化方法归类到不同的类别中,可以帮助读者更好地理解这些技术之间的关系和区别。此外,该综述还对每种技术进行了详细的描述和分析,包括其原理、优缺点以及适用场景。没有涉及具体的参数设置、损失函数、网络结构等技术细节,因为这是一篇综述文章,侧重于对现有技术的总结和分析。
🖼️ 关键图片


📊 实验亮点
该论文是一篇综述,没有具体的实验结果。其亮点在于对现有的大型语言模型推理优化技术进行了全面的总结和分析,并指出了各种技术面临的挑战和未来的研究方向。这对于研究人员和从业者来说具有重要的参考价值,可以帮助他们更好地理解和应用这些技术。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,例如移动设备上的自然语言处理应用、边缘计算环境中的智能助手、以及需要降低推理成本的云服务等。通过选择合适的模型压缩和加速技术,可以在保证模型性能的同时,显著降低资源消耗,从而实现更广泛的应用。
📄 摘要(原文)
Large language models are ubiquitous in natural language processing because they can adapt to new tasks without retraining. However, their sheer scale and complexity present unique challenges and opportunities, prompting researchers and practitioners to explore novel model training, optimization, and deployment methods. This literature review focuses on various techniques for reducing resource requirements and compressing large language models, including quantization, pruning, knowledge distillation, and architectural optimizations. The primary objective is to explore each method in-depth and highlight its unique challenges and practical applications. The discussed methods are categorized into a taxonomy that presents an overview of the optimization landscape and helps navigate it to understand the research trajectory better.