Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
作者: Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
分类: cs.CL, cs.IR
发布日期: 2024-08-06
备注: 10 pages, 7 figures
💡 一句话要点
Fact Finder:融合知识图谱增强大语言模型在特定领域的专业知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大语言模型 领域知识 混合系统 信息检索 医学知识图谱 Cypher查询
📋 核心要点
- 大语言模型在回答自然语言查询方面表现出色,但受限于领域知识,其回答的可靠性受到质疑。
- 该研究提出一种混合系统,通过知识图谱检索增强LLM,提升其在特定领域的事实准确性和完整性。
- 实验表明,该系统在准确性和完整性方面优于独立LLM,尤其适用于需要精确知识的场景,如靶标识别。
📝 摘要(中文)
本文提出了一种混合系统,通过将领域知识图谱(KG)融入大语言模型(LLM),利用基于KG的检索方法来提高事实正确性。该方法以医学KG为例,包括预处理、Cypher查询生成、Cypher查询处理、KG检索和LLM增强的响应生成五个步骤。在包含69个样本的测试数据集上,该系统在检索正确KG节点方面达到了78%的精度。实验结果表明,该混合系统在准确性和完整性方面优于独立的LLM,并通过LLM-as-a-Judge评估方法验证了这一点。该系统适用于需要事实正确性和完整性的应用,如靶标识别,即精确定位用于疾病治疗或作物改良的生物实体。其直观的搜索界面和快速响应能力使其适用于时间敏感、注重精确性的研究环境。论文公开了源代码、数据集和使用的提示模板。
🔬 方法详解
问题定义:现有的大语言模型在特定领域知识方面存在不足,导致回答的准确性和可靠性受到限制。尤其是在医学等专业领域,错误的信息可能会产生严重的后果。因此,需要一种方法来增强LLM的领域知识,提高其回答的准确性和完整性。
核心思路:该论文的核心思路是将领域知识图谱(KG)与大语言模型(LLM)相结合,利用KG存储和检索结构化知识的能力,弥补LLM在特定领域知识方面的不足。通过KG检索,可以为LLM提供更准确、更全面的信息,从而提高其回答的质量。
技术框架:该混合系统主要包含五个阶段:(1) 预处理:对知识图谱进行清洗和转换,使其适应后续的查询和检索。(2) Cypher查询生成:将自然语言查询转换为Cypher查询语句,以便在知识图谱中进行检索。(3) Cypher查询处理:执行Cypher查询,从知识图谱中检索相关节点和关系。(4) KG检索:对检索到的KG节点进行排序和筛选,选择最相关的节点。(5) LLM增强的响应生成:将检索到的KG信息作为上下文,输入到LLM中,生成最终的回答。
关键创新:该研究的关键创新在于将知识图谱检索与大语言模型相结合,形成一个混合系统。与传统的LLM相比,该系统能够利用KG的结构化知识,提供更准确、更全面的信息。此外,该系统还能够解释其推理过程,提高了回答的可解释性。
关键设计:在Cypher查询生成阶段,使用了基于规则和基于学习的方法,将自然语言查询转换为Cypher查询语句。在KG检索阶段,使用了基于相似度的排序算法,选择最相关的KG节点。在LLM增强的响应生成阶段,使用了prompt engineering技术,引导LLM生成更准确、更自然的回答。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
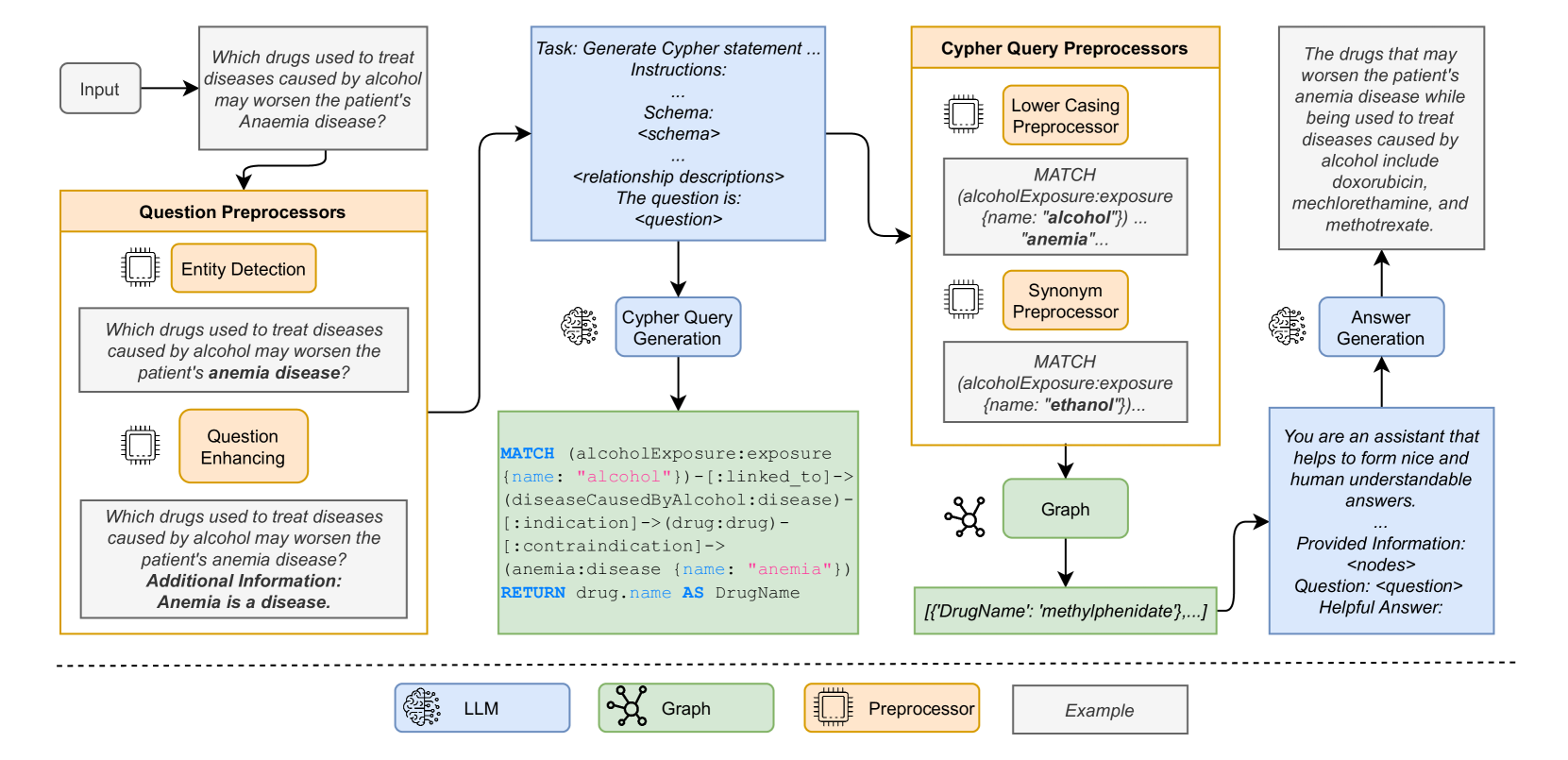


📊 实验亮点
实验结果表明,该混合系统在检索正确KG节点方面达到了78%的精度。通过LLM-as-a-Judge评估方法验证,该系统在准确性和完整性方面优于独立的LLM。这表明将知识图谱与大语言模型相结合,可以显著提高LLM在特定领域的表现。具体的提升幅度数据未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于需要高精度和专业知识的领域,如医疗诊断、药物研发、基因工程、农业优化等。例如,在药物研发中,该系统可以帮助研究人员快速找到与特定疾病相关的靶点,加速药物的开发过程。此外,该系统还可以用于构建智能客服系统,为用户提供更准确、更专业的咨询服务。未来,该研究有望推动LLM在专业领域的应用,提高其解决实际问题的能力。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78\% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.