Intermediate direct preference optimization
作者: Atsushi Kojima
分类: cs.CL
发布日期: 2024-08-06
💡 一句话要点
提出中间层直接偏好优化(Intermediate DPO)方法,提升大型语言模型微调效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 大型语言模型 中间层特征 微调 辅助损失
📋 核心要点
- 传统DPO仅利用最后一层信息,可能忽略了模型中间层的知识,限制了微调效果。
- Intermediate DPO的核心思想是利用模型中间层的logits计算DPO损失,作为辅助损失来指导模型微调。
- 实验表明,在特定中间层计算DPO损失可以显著提升模型性能,胜率分别提升至52.5%和67.5%。
📝 摘要(中文)
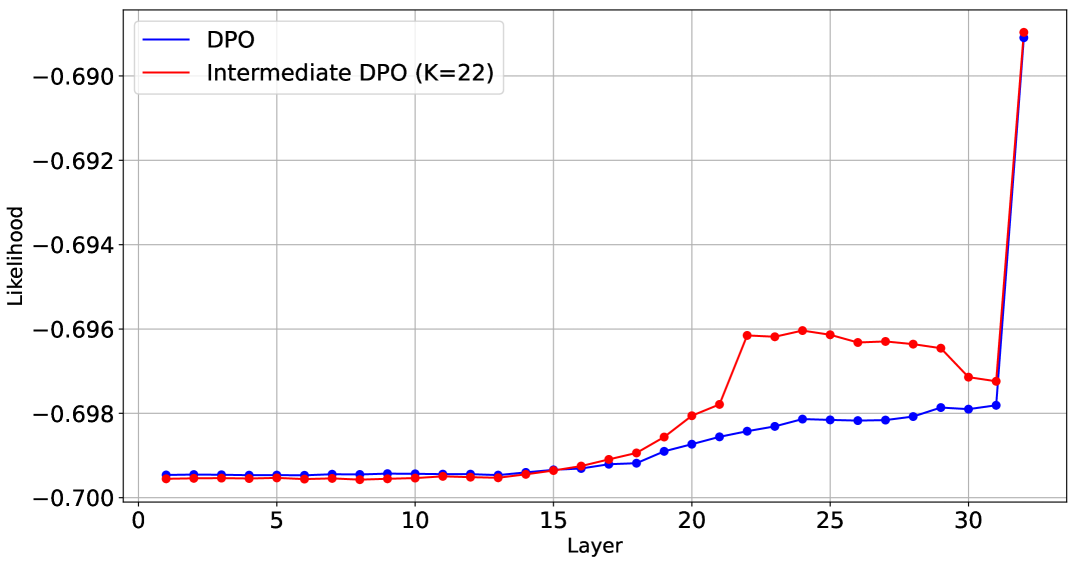
本文提出了一种中间层直接偏好优化(Intermediate DPO)方法,用于微调大型语言模型(LLMs)。该方法在选定的中间层计算DPO损失作为辅助损失。传统的DPO方法通过使用最后一层的logits计算DPO损失来微调有监督微调(SFT)模型。而本文提出的中间DPO方法,使用K个选定的中间层的logits计算DPO损失,并对这些损失进行平均,得到中间DPO损失。在训练中间DPO模型时,最终损失通过计算DPO损失和中间DPO损失的加权和得到。在推理阶段,中间DPO模型与传统DPO模型类似,使用最后一层的logits进行解码。使用ultrafeedback数据集进行的实验表明,使用32层SFT模型的第22层计算的中间DPO损失训练的中间DPO模型,相对于传统DPO和SFT模型,分别实现了52.5%和67.5%的胜率,证明了该方法的有效性。此外,本文还报告了所选中间层的位置、层数和性能之间的关系。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在微调大型语言模型时,仅使用模型最后一层的logits计算损失,这可能无法充分利用模型中间层学习到的知识,从而限制了微调效果。因此,如何更有效地利用模型中间层的信息来提升DPO微调的性能是一个关键问题。
核心思路:本文的核心思路是在DPO训练过程中,引入模型中间层的logits信息。具体来说,就是选择若干个中间层,利用这些中间层的logits计算DPO损失,并将这些损失作为辅助损失,与传统DPO损失进行加权求和,共同指导模型的训练。这样做的目的是让模型在微调过程中,不仅关注最终的输出结果,也关注中间层的表示,从而更好地学习到偏好信息。
技术框架:Intermediate DPO的整体框架如下:首先,基于SFT模型。然后,选择K个中间层。接着,计算传统DPO损失和中间DPO损失。其中,中间DPO损失是K个中间层DPO损失的平均。最后,将传统DPO损失和中间DPO损失进行加权求和,得到最终的训练损失。在推理阶段,模型仍然使用最后一层的logits进行解码,与传统DPO模型保持一致。
关键创新:该方法最重要的创新点在于,它将DPO损失计算扩展到了模型的中间层,从而能够更充分地利用模型学习到的知识。与传统DPO方法相比,Intermediate DPO方法能够更好地捕捉到偏好信息,从而提升模型的性能。
关键设计:关键设计包括:1) 中间层的选择策略:论文研究了不同中间层位置和数量对性能的影响。2) 损失函数:最终损失是传统DPO损失和中间DPO损失的加权和,权重需要根据实验进行调整。3) 推理阶段:为了保证与现有系统的兼容性,推理阶段仍然使用最后一层的logits进行解码。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Intermediate DPO方法可以显著提升模型的性能。具体来说,使用32层SFT模型的第22层计算的中间DPO损失训练的Intermediate DPO模型,相对于传统DPO和SFT模型,分别实现了52.5%和67.5%的胜率。这表明,通过利用模型中间层的信息,可以有效地提升DPO微调的性能。
🎯 应用场景
Intermediate DPO方法可广泛应用于各种需要使用大型语言模型进行微调的场景,例如对话系统、文本生成、代码生成等。通过更有效地利用模型中间层的信息,该方法可以提升模型的性能和生成质量,从而为用户提供更好的体验。此外,该方法还可以用于探索模型内部的表示学习,帮助我们更好地理解大型语言模型的工作机制。
📄 摘要(原文)
We propose the intermediate direct preference optimization (DPO) method to calculate the DPO loss at selected intermediate layers as an auxiliary loss for finetuning large language models (LLMs). The conventional DPO method fine-tunes a supervised fine-tuning (SFT) model by calculating the DPO loss using logits from the final layer. In our intermediate DPO approach, DPO losses are calculated using the logits from K-selected intermediate layers and averaged to obtain the intermediate DPO loss. For training the intermediate DPO model, the final loss is obtained by calculating the weighted sum of the DPO and intermediate DPO losses. During inference, the intermediate DPO model decodes using the final layer logits similarly to the conventional DPO model. In experiments using the ultrafeedback dataset, the performance of the intermediate DPO model was evaluated using GPT-4. As a result, the intermediate DPO model trained using the intermediate DPO loss calculated at the 22nd layer of a 32-layer SFT model achieved win rates of 52.5% and 67.5% against the conventional DPO and SFT models, respectively, demonstrating the effectiveness of the proposed method. Furthermore, we report the relationships among the position of the selected intermediate layers, the number of layers, and performance.