Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models
作者: Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung-yi Lee, Yun-Nung Chen
分类: cs.CL
发布日期: 2024-08-05 (更新: 2024-10-14)
备注: 18 pages
💡 一句话要点
研究表明:格式限制显著降低大语言模型在推理任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 格式限制 结构化生成 推理能力 性能评估
📋 核心要点
- 现有方法依赖结构化生成从LLM中提取关键信息,但其对LLM能力的影响尚不明确。
- 该研究对比了LLM在结构化格式约束和自由形式生成下的性能差异,着重考察推理能力。
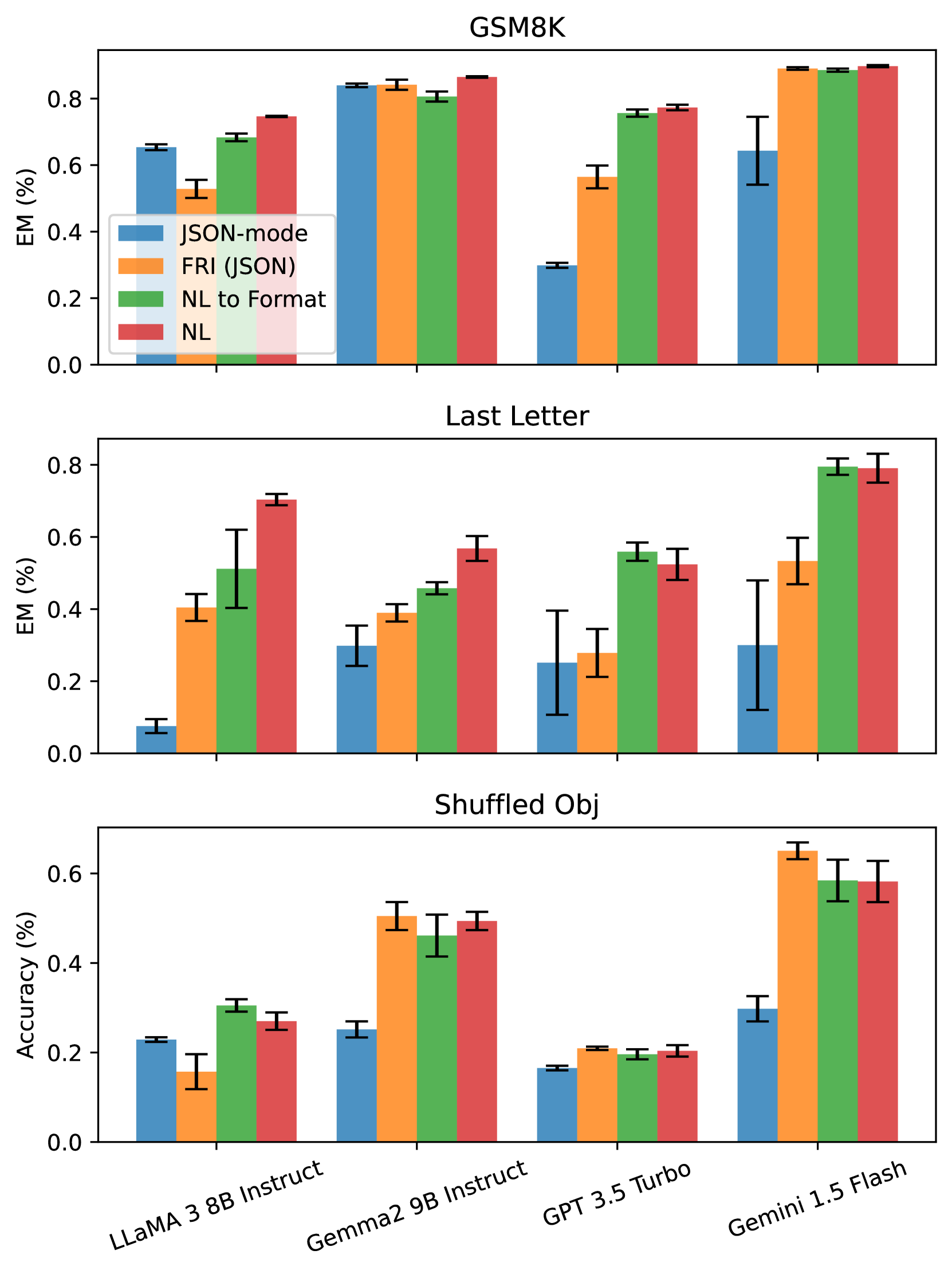
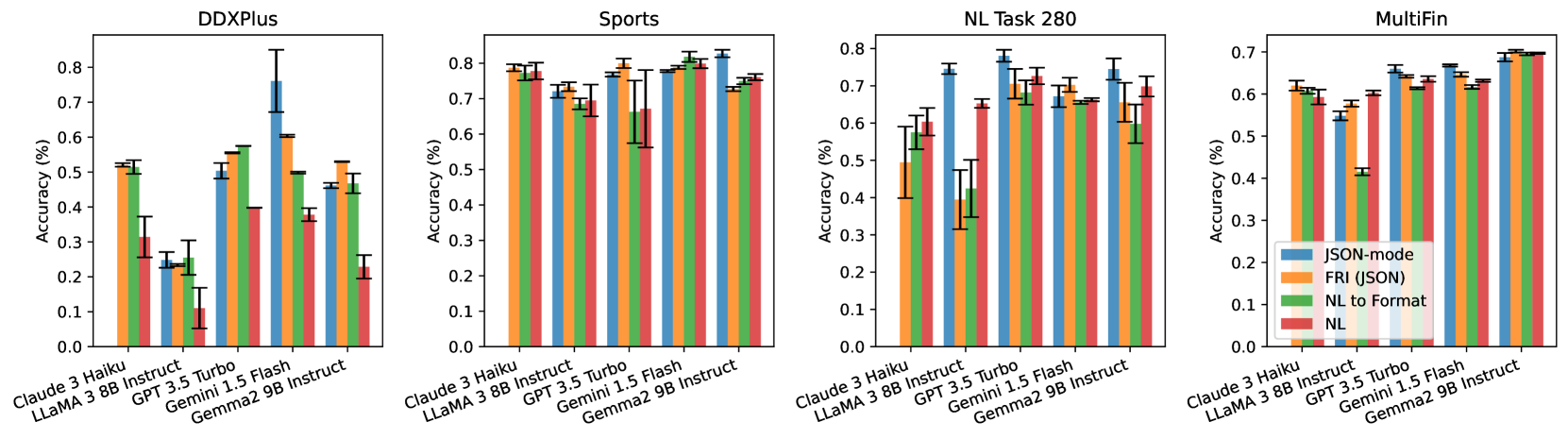
- 实验结果表明,格式限制显著降低LLM的推理能力,且更严格的格式约束导致更大的性能下降。
📝 摘要(中文)
本研究探讨了在实际应用中广泛使用的结构化生成(例如JSON和XML格式),即以标准化格式生成内容,对大语言模型(LLMs)能力的影响,包括推理能力和领域知识理解。具体而言,我们评估了LLMs在被限制为遵循结构化格式与生成自由形式响应时,在各种常见任务中的表现。令人惊讶的是,我们观察到在格式限制下,LLMs的推理能力显著下降。此外,我们发现更严格的格式约束通常会导致推理任务中更大的性能下降。
🔬 方法详解
问题定义:论文旨在研究对大语言模型施加格式限制(例如要求输出JSON或XML)是否会影响其性能,特别是推理能力和领域知识的运用。现有方法通常直接采用结构化生成,而忽略了这种约束可能带来的负面影响。现有研究缺乏对格式限制对LLM内在能力的系统性评估。
核心思路:核心思路是通过对比LLM在有格式限制和无格式限制两种情况下的表现,来量化格式限制对LLM能力的影响。通过设计不同的任务和格式约束,分析性能下降的程度,从而揭示格式限制对LLM推理能力的潜在影响。
技术框架:该研究采用实验评估的方法。首先,选择一系列常见的任务,这些任务涵盖不同的推理类型和领域知识。然后,针对每个任务,设计两种生成模式:一种是自由形式生成,允许LLM以自然语言自由回答;另一种是结构化生成,要求LLM按照预定义的格式(如JSON)输出答案。最后,比较LLM在两种生成模式下的性能,并分析性能差异与格式约束之间的关系。
关键创新:该研究的关键创新在于首次系统性地研究了格式限制对LLM推理能力的影响。以往的研究主要关注如何提高结构化生成的准确性和效率,而忽略了格式限制本身可能对LLM内在能力造成的损害。该研究的发现为未来LLM的应用和优化提供了新的视角。
关键设计:关键设计包括:1) 任务选择:选择涵盖不同推理类型(如逻辑推理、常识推理)和领域知识的任务,以保证研究的generalizability。2) 格式约束设计:设计不同严格程度的格式约束,例如JSON的schema的复杂程度,以研究格式约束的强度与性能下降之间的关系。3) 评估指标:采用准确率、F1值等指标来量化LLM在不同生成模式下的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,格式限制显著降低了LLM的推理能力。例如,在某些推理任务中,采用JSON格式约束后,LLM的准确率下降了10%以上。此外,研究还发现,更严格的格式约束(例如更复杂的JSON schema)会导致更大的性能下降。这些结果表明,在实际应用中,需要谨慎权衡格式约束带来的便利性和对LLM性能的潜在影响。
🎯 应用场景
该研究成果可应用于各种需要从LLM中提取结构化信息的场景,例如智能助手、知识图谱构建、数据分析等。通过了解格式限制对LLM性能的影响,可以更好地设计提示词和输出格式,从而提高LLM在实际应用中的效果。未来的研究可以探索如何缓解格式限制带来的负面影响,例如通过微调或prompt engineering。
📄 摘要(原文)
Structured generation, the process of producing content in standardized formats like JSON and XML, is widely utilized in real-world applications to extract key output information from large language models (LLMs). This study investigates whether such constraints on generation space impact LLMs abilities, including reasoning and domain knowledge comprehension. Specifically, we evaluate LLMs performance when restricted to adhere to structured formats versus generating free-form responses across various common tasks. Surprisingly, we observe a significant decline in LLMs reasoning abilities under format restrictions. Furthermore, we find that stricter format constraints generally lead to greater performance degradation in reasoning tasks.