A Few-Shot Approach for Relation Extraction Domain Adaptation using Large Language Models
作者: Vanni Zavarella, Juan Carlos Gamero-Salinas, Sergio Consoli
分类: cs.CL, cs.AI
发布日期: 2024-08-05
期刊: CEUR Workshop Proceedings, Vol. 3894 (2024), Workshop at KDD 2024 on Deep Learning and Large Language Models for Knowledge Graphs
💡 一句话要点
提出一种基于大语言模型的小样本关系抽取领域自适应方法,用于科学知识图谱构建。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关系抽取 领域自适应 小样本学习 大型语言模型 知识图谱
📋 核心要点
- 现有关系抽取模型在特定领域数据集上训练,难以适应新的科学领域,阻碍了跨领域知识图谱的构建。
- 利用大语言模型的上下文学习能力,通过少量样本和结构化提示,自动标注目标领域数据,降低人工标注成本。
- 实验表明,该方法在建筑、施工、工程和运营(AECO)领域取得了性能提升,验证了其领域自适应的潜力。
📝 摘要(中文)
知识图谱(KGs)已成功应用于复杂科学技术领域的分析。自动知识图谱生成方法通常依赖于关系抽取模型,该模型捕获文本中领域实体之间细粒度的关系。虽然这些关系完全适用于各个科学领域,但现有模型主要在少数领域特定数据集(如SciERC)上训练,在新目标领域表现不佳。本文探索利用大型语言模型的上下文学习能力,执行模式约束的数据标注,为基于Transformer的关系抽取模型收集领域内训练实例,该模型部署于建筑、施工、工程和运营(AECO)领域的研究论文标题和摘要上。通过评估相对于在领域外数据上训练的基线深度学习架构的性能提升,我们表明,通过使用带有结构化提示的小样本学习策略和最少的专家标注,所提出的方法可以潜在地支持科学知识图谱生成模型的领域自适应。
🔬 方法详解
问题定义:论文旨在解决关系抽取模型在不同科学领域之间迁移能力不足的问题。现有模型在特定领域数据集上训练,难以适应新的目标领域,导致在新领域上的关系抽取性能显著下降。这限制了跨领域知识图谱的构建和应用。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的上下文学习能力,通过少量样本(few-shot learning)和结构化提示(structured prompts),自动生成目标领域(如AECO)的训练数据。这样可以避免大量的人工标注工作,并使关系抽取模型能够更好地适应新的领域。
技术框架:整体框架包括以下几个主要步骤:1) 使用LLM进行模式约束的数据标注,生成目标领域的训练数据。2) 使用生成的训练数据,对基于Transformer的关系抽取模型进行微调。3) 在目标领域的数据集上评估微调后的模型的性能。该框架利用LLM强大的生成能力,降低了领域自适应的成本。
关键创新:该方法的主要创新在于利用LLM的上下文学习能力,以小样本的方式进行领域自适应。传统的领域自适应方法通常需要大量的目标领域数据或复杂的迁移学习策略。而该方法只需要少量的样本和结构化的提示,就可以使LLM生成高质量的目标领域训练数据,从而实现高效的领域自适应。
关键设计:关键设计包括:1) 使用结构化的提示,引导LLM生成符合特定模式的关系抽取数据。2) 使用Transformer作为关系抽取模型的基础架构,并使用生成的训练数据进行微调。3) 通过与在领域外数据上训练的基线模型进行比较,评估领域自适应的效果。具体的参数设置、损失函数和网络结构等细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
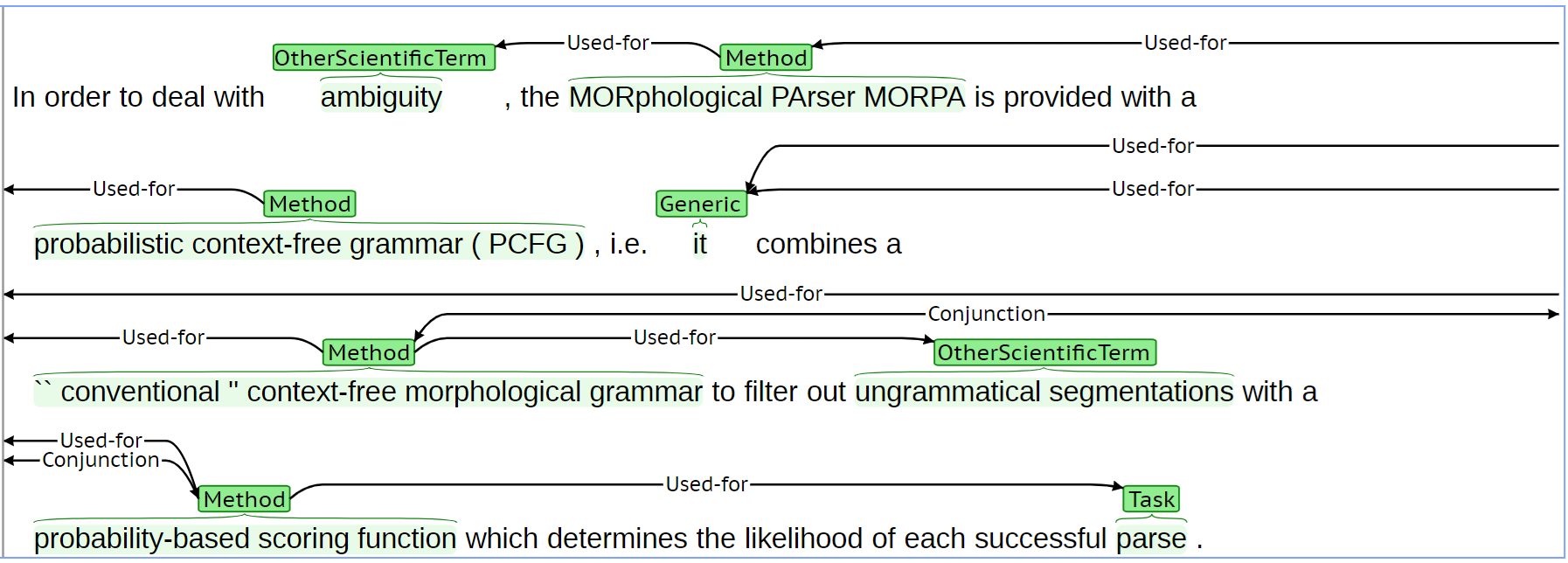


📊 实验亮点
论文通过实验证明,使用基于大语言模型的小样本学习方法,可以有效提升关系抽取模型在目标领域的性能。相对于在领域外数据上训练的基线模型,该方法取得了显著的性能提升,表明其在领域自适应方面具有潜力。具体的性能数据和提升幅度在摘要中没有明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于自动构建特定领域的科学知识图谱,例如建筑、施工、工程和运营(AECO)领域。通过自动抽取论文中的实体关系,可以帮助研究人员快速了解领域内的知识结构,促进跨学科的合作和创新。该方法还可推广到其他科学领域,加速知识图谱的构建和应用。
📄 摘要(原文)
Knowledge graphs (KGs) have been successfully applied to the analysis of complex scientific and technological domains, with automatic KG generation methods typically building upon relation extraction models capturing fine-grained relations between domain entities in text. While these relations are fully applicable across scientific areas, existing models are trained on few domain-specific datasets such as SciERC and do not perform well on new target domains. In this paper, we experiment with leveraging in-context learning capabilities of Large Language Models to perform schema-constrained data annotation, collecting in-domain training instances for a Transformer-based relation extraction model deployed on titles and abstracts of research papers in the Architecture, Construction, Engineering and Operations (AECO) domain. By assessing the performance gain with respect to a baseline Deep Learning architecture trained on off-domain data, we show that by using a few-shot learning strategy with structured prompts and only minimal expert annotation the presented approach can potentially support domain adaptation of a science KG generation model.