Dialogue Ontology Relation Extraction via Constrained Chain-of-Thought Decoding
作者: Renato Vukovic, David Arps, Carel van Niekerk, Benjamin Matthias Ruppik, Hsien-Chin Lin, Michael Heck, Milica Gašić
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-05 (更新: 2025-03-07)
备注: Accepted to appear at SIGDIAL 2024. 9 pages, 4 figures
💡 一句话要点
提出基于约束链式思考解码的对话本体关系抽取方法,提升泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话本体构建 关系抽取 链式思考 大型语言模型 本体约束
📋 核心要点
- 现有面向任务的对话系统依赖手动构建的本体,成本高且限制了应用。
- 论文提出约束链式思考解码方法,通过在解码时约束本体术语和关系来减少幻觉。
- 实验表明,该方法在目标本体上提升了源微调和单样本提示的大型语言模型的性能。
📝 摘要(中文)
目前先进的面向任务的对话系统通常依赖于任务特定的本体来满足用户查询。然而,大多数面向任务的对话数据,例如客户服务录音,缺乏本体和标注。这些本体通常是手动构建的,限制了专用系统的应用。对话本体构建旨在自动化该过程,通常包括术语提取和关系提取两个步骤。本文侧重于迁移学习设置中的关系提取。为了提高泛化能力,我们提出了一种大型语言模型解码机制的扩展。我们将最近为推理问题开发的链式思考(CoT)解码应用于生成式关系提取。在这里,我们在解码空间中生成多个分支,并根据置信度阈值选择关系。通过将解码约束到本体术语和关系,我们旨在降低幻觉风险。我们在两个广泛使用的数据集上进行了大量实验,发现源微调和单样本提示的大型语言模型在目标本体上的性能有所提高。
🔬 方法详解
问题定义:论文旨在解决对话本体构建中的关系抽取问题。现有方法,特别是基于大型语言模型的方法,在生成关系时容易出现“幻觉”,即生成不符合预定义本体的关系,导致抽取结果不准确,泛化能力不足。
核心思路:论文的核心思路是将链式思考(Chain-of-Thought, CoT)解码与本体约束相结合。CoT解码通过生成多个推理分支来提高模型的推理能力,而本体约束则限制了解码空间,减少了模型生成不相关或错误关系的可能性。通过这种方式,模型能够在预定义的本体范围内更准确地抽取关系。
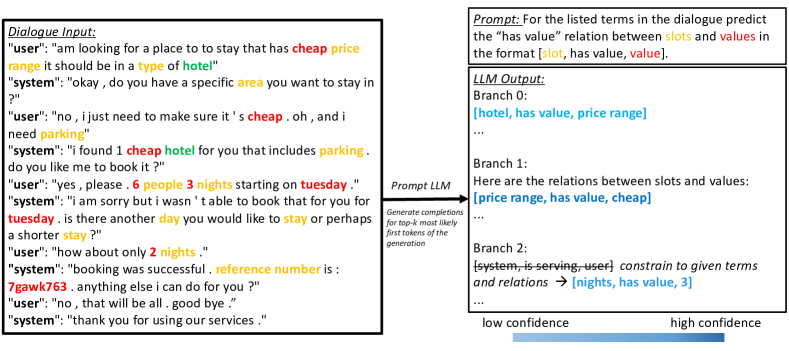
技术框架:该方法主要包含以下几个阶段:1) 输入对话文本;2) 使用大型语言模型进行CoT解码,生成多个关系抽取分支;3) 对每个分支进行本体约束,即只允许生成预定义本体中的术语和关系;4) 根据置信度阈值选择最终的关系抽取结果。整体流程旨在利用CoT的推理能力,同时通过本体约束来保证抽取结果的准确性。
关键创新:该方法最重要的创新点在于将CoT解码与本体约束相结合,用于对话本体关系抽取。与传统的CoT方法相比,该方法通过本体约束有效地减少了幻觉问题,提高了关系抽取的准确性和泛化能力。与直接使用大型语言模型进行关系抽取相比,该方法利用CoT的推理能力,能够更好地理解对话上下文,从而抽取更准确的关系。
关键设计:论文的关键设计包括:1) 使用大型语言模型作为基础模型,例如经过微调的或使用单样本提示的模型;2) 设计合适的CoT提示,引导模型进行关系推理;3) 构建本体约束机制,限制解码空间;4) 设置置信度阈值,用于选择最终的关系抽取结果。具体的参数设置和网络结构取决于所使用的大型语言模型。
🖼️ 关键图片
📊 实验亮点
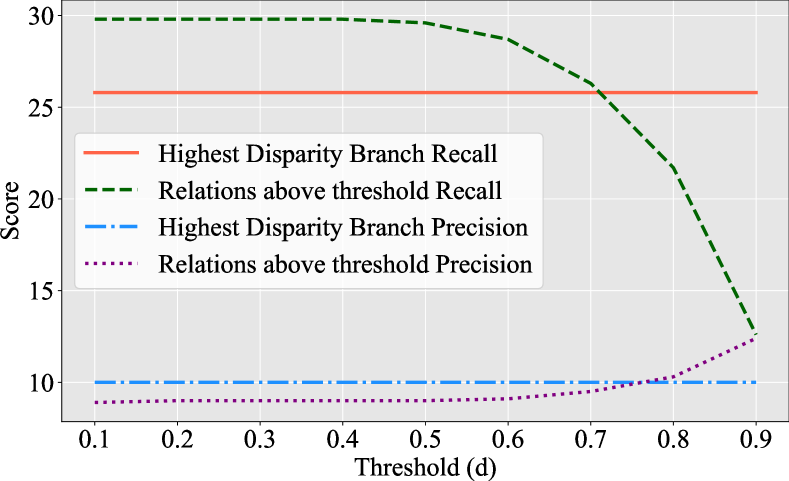
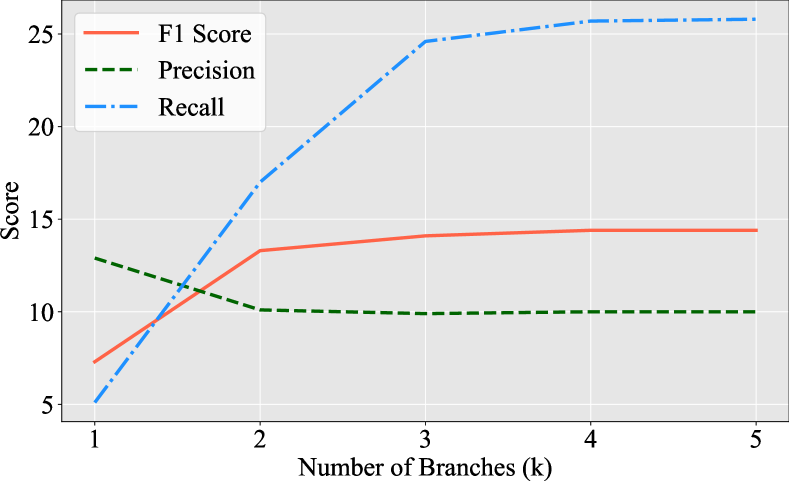
实验结果表明,该方法在两个广泛使用的数据集上取得了性能提升。具体而言,源微调和单样本提示的大型语言模型在目标本体上的关系抽取性能均有所提高,证明了该方法在提高泛化能力和减少幻觉方面的有效性。具体的性能提升幅度在论文中进行了详细的量化。
🎯 应用场景
该研究成果可应用于自动构建面向任务的对话系统本体,尤其是在缺乏标注数据的场景下。例如,可以应用于客户服务领域,自动从客户服务录音中提取知识,构建客户服务知识库,从而提高客户服务效率和质量。未来,该技术还可以扩展到其他领域,例如医疗、金融等,构建领域知识图谱。
📄 摘要(原文)
State-of-the-art task-oriented dialogue systems typically rely on task-specific ontologies for fulfilling user queries. The majority of task-oriented dialogue data, such as customer service recordings, comes without ontology and annotation. Such ontologies are normally built manually, limiting the application of specialised systems. Dialogue ontology construction is an approach for automating that process and typically consists of two steps: term extraction and relation extraction. In this work, we focus on relation extraction in a transfer learning set-up. To improve the generalisation, we propose an extension to the decoding mechanism of large language models. We adapt Chain-of-Thought (CoT) decoding, recently developed for reasoning problems, to generative relation extraction. Here, we generate multiple branches in the decoding space and select the relations based on a confidence threshold. By constraining the decoding to ontology terms and relations, we aim to decrease the risk of hallucination. We conduct extensive experimentation on two widely used datasets and find improvements in performance on target ontology for source fine-tuned and one-shot prompted large language models.