SNFinLLM: Systematic and Nuanced Financial Domain Adaptation of Chinese Large Language Models
作者: Shujuan Zhao, Lingfeng Qiao, Kangyang Luo, Qian-Wen Zhang, Junru Lu, Di Yin
分类: cs.CL
发布日期: 2024-08-05
💡 一句话要点
提出SNFinLLM,针对中文金融领域进行系统且细致的领域自适应,提升金融计算和机器阅读理解能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融大语言模型 领域自适应 中文金融 监督微调 直接偏好优化 金融计算 机器阅读理解
📋 核心要点
- 现有金融LLM存在幻觉和参数训练不足的问题,导致在金融计算和机器阅读理解等任务中表现不佳。
- SNFinLLM通过收集金融数据构建高质量指令数据集,并结合持续预训练和监督微调,提升模型在金融领域的性能。
- 实验结果表明,SNFinLLM在金融基准测试和评估数据集上显著优于其他先进的金融语言模型。
📝 摘要(中文)
大型语言模型(LLMs)已成为推动金融行业自然语言处理应用的强大工具。然而,现有的金融LLM常常面临幻觉或肤浅的参数训练等挑战,导致次优的性能,尤其是在金融计算和机器阅读理解(MRC)方面。为了解决这些问题,我们提出了一种专门为中文金融领域设计的新型大型语言模型,名为SNFinLLM。SNFinLLM擅长领域特定任务,如回答问题、总结金融研究报告、分析情绪和执行金融计算。我们然后执行监督微调(SFT),以提高模型在各种金融领域的熟练程度。具体来说,我们收集了广泛的金融数据,并创建了一个由新闻文章、专业论文和金融领域研究报告组成的高质量指令数据集。利用领域特定和通用数据集,我们继续在一个已建立的开源基础模型上进行持续预训练,从而产生SNFinLLM-base。在此之后,我们进行监督微调(SFT),以增强模型在多个金融任务中的能力。至关重要的是,我们采用了一种直接偏好优化(DPO)方法,以更好地使模型与人类偏好对齐。在金融基准和我们的评估数据集上进行的大量实验表明,SNFinLLM明显优于其他最先进的金融语言模型。
🔬 方法详解
问题定义:论文旨在解决现有金融领域大语言模型在中文金融任务中表现不佳的问题,尤其是在金融计算和机器阅读理解方面。现有模型的痛点包括容易产生幻觉、参数训练不充分,以及无法很好地对齐人类偏好。
核心思路:论文的核心思路是构建一个专门针对中文金融领域进行自适应的大语言模型SNFinLLM。通过高质量的金融数据构建指令数据集,并结合持续预训练、监督微调和直接偏好优化(DPO)等方法,提升模型在金融领域的性能和对齐人类偏好的能力。
技术框架:SNFinLLM的训练框架主要包括以下几个阶段:1) 数据收集与指令数据集构建:收集广泛的金融数据,包括新闻文章、专业论文和研究报告,构建高质量的指令数据集。2) 持续预训练:在开源基础模型上,利用领域特定和通用数据集进行持续预训练,得到SNFinLLM-base。3) 监督微调(SFT):使用指令数据集对SNFinLLM-base进行监督微调,提升模型在多个金融任务中的能力。4) 直接偏好优化(DPO):使用DPO方法对模型进行优化,使其更好地与人类偏好对齐。
关键创新:论文的关键创新在于针对中文金融领域,系统性地结合了持续预训练、监督微调和直接偏好优化(DPO)等技术,构建了一个高性能的金融大语言模型SNFinLLM。此外,高质量的金融指令数据集也是一个重要的贡献。
关键设计:论文中关键的设计包括:1) 指令数据集的构建策略,如何保证数据的质量和多样性。2) 持续预训练的数据选择和训练策略。3) 监督微调的任务设置和训练细节。4) DPO方法的具体实现和参数设置。这些细节决定了模型最终的性能表现。
🖼️ 关键图片


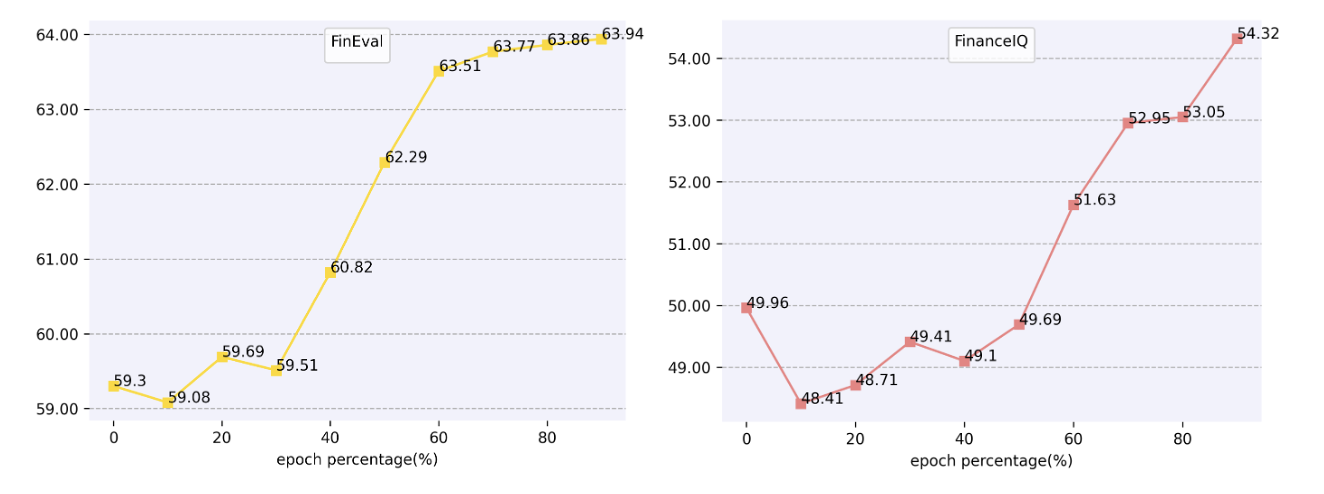
📊 实验亮点
SNFinLLM在金融基准测试和评估数据集上进行了广泛的实验,结果表明其性能显著优于其他最先进的金融语言模型。具体的性能数据和对比基线在论文中详细展示,表明SNFinLLM在金融领域的各项任务上都取得了显著的提升。
🎯 应用场景
SNFinLLM可应用于多种金融场景,如智能客服、金融报告生成、金融风险评估、投资决策支持等。该研究有助于提升金融行业的智能化水平,提高工作效率,并为投资者提供更准确、更全面的信息服务。未来,该模型可以进一步扩展到其他金融领域,并与其他技术相结合,实现更高级的金融应用。
📄 摘要(原文)
Large language models (LLMs) have become powerful tools for advancing natural language processing applications in the financial industry. However, existing financial LLMs often face challenges such as hallucinations or superficial parameter training, resulting in suboptimal performance, particularly in financial computing and machine reading comprehension (MRC). To address these issues, we propose a novel large language model specifically designed for the Chinese financial domain, named SNFinLLM. SNFinLLM excels in domain-specific tasks such as answering questions, summarizing financial research reports, analyzing sentiment, and executing financial calculations. We then perform the supervised fine-tuning (SFT) to enhance the model's proficiency across various financial domains. Specifically, we gather extensive financial data and create a high-quality instruction dataset composed of news articles, professional papers, and research reports of finance domain. Utilizing both domain-specific and general datasets, we proceed with continuous pre-training on an established open-source base model, resulting in SNFinLLM-base. Following this, we engage in supervised fine-tuning (SFT) to bolster the model's capability across multiple financial tasks. Crucially, we employ a straightforward Direct Preference Optimization (DPO) method to better align the model with human preferences. Extensive experiments conducted on finance benchmarks and our evaluation dataset demonstrate that SNFinLLM markedly outperforms other state-of-the-art financial language models. For more details, check out our demo video here: https://www.youtube.com/watch?v=GYT-65HZwus.