Do Large Language Models Speak All Languages Equally? A Comparative Study in Low-Resource Settings
作者: Md. Arid Hasan, Prerona Tarannum, Krishno Dey, Imran Razzak, Usman Naseem
分类: cs.CL
发布日期: 2024-08-05
💡 一句话要点
对比研究LLM在低资源语言环境下的表现,揭示其性能差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 零样本学习 情感分析 仇恨言论检测
📋 核心要点
- 现有研究对LLM在低资源语言上的表现关注不足,尤其缺乏对南亚语种的深入分析,且任务类型单一。
- 该研究通过构建多语种情感分析和仇恨言论数据集,并在多种LLM上进行零样本学习,评估模型性能。
- 实验结果表明,GPT-4在各项任务中表现最佳,但所有LLM在英语上的表现均优于低资源语言。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理(NLP)领域引起了广泛关注,尤其是在资源丰富的语言中,它们在各种下游任务中表现出色。然而,最近的研究强调了LLM在低资源语言中的局限性,主要集中在二元分类任务上,并且对南亚语言的关注较少。这些限制主要归因于数据集稀缺、计算成本以及特定于低资源语言的研究空白等因素。为了弥补这一差距,我们通过将英语翻译成孟加拉语、印地语和乌尔都语,提出了用于情感分析和仇恨言论任务的数据集,从而促进了低资源语言处理的研究。此外,我们全面地研究了在英语和广泛使用的南亚语言中使用多个LLM的零样本学习。我们的研究结果表明,GPT-4始终优于Llama 2和Gemini,并且与低资源语言相比,英语在各种任务中始终表现出卓越的性能。此外,我们的分析表明,自然语言推理(NLI)在评估的任务中表现出最高的性能,其中GPT-4表现出卓越的能力。
🔬 方法详解
问题定义:现有大型语言模型在资源丰富的语言上表现出色,但在低资源语言上的性能存在局限性。以往研究主要集中在二元分类任务,对南亚语言关注不足,并且缺乏针对情感分析和仇恨言论等任务的专门数据集。因此,需要深入评估LLM在低资源语言环境下的性能,并构建相应的数据集以促进相关研究。
核心思路:该研究的核心思路是通过构建英-孟加拉语、英-印地语和英-乌尔都语的情感分析和仇恨言论数据集,并在这些数据集上评估多个LLM的零样本学习性能。通过对比不同LLM在不同语言上的表现,揭示LLM在低资源语言环境下的性能瓶颈。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据集构建:将英文情感分析和仇恨言论数据集翻译成孟加拉语、印地语和乌尔都语。2) 模型选择:选择GPT-4、Llama 2和Gemini等多个LLM进行评估。3) 零样本学习:在构建的数据集上进行零样本学习,评估模型在不同语言上的性能。4) 性能评估:使用准确率等指标评估模型在不同任务和语言上的性能。
关键创新:该研究的关键创新在于:1) 构建了用于情感分析和仇恨言论任务的英-孟加拉语、英-印地语和英-乌尔都语数据集,为低资源语言处理研究提供了资源。2) 对比了多个LLM在英语和多种南亚语言上的零样本学习性能,揭示了LLM在低资源语言环境下的性能差异。
关键设计:该研究的关键设计包括:1) 数据集翻译方法:采用高质量的翻译方法,确保翻译数据集的质量。2) 模型评估指标:选择准确率等常用的评估指标,客观评估模型性能。3) 实验设置:采用零样本学习设置,评估模型在没有特定语言训练数据的情况下,对低资源语言的泛化能力。
🖼️ 关键图片
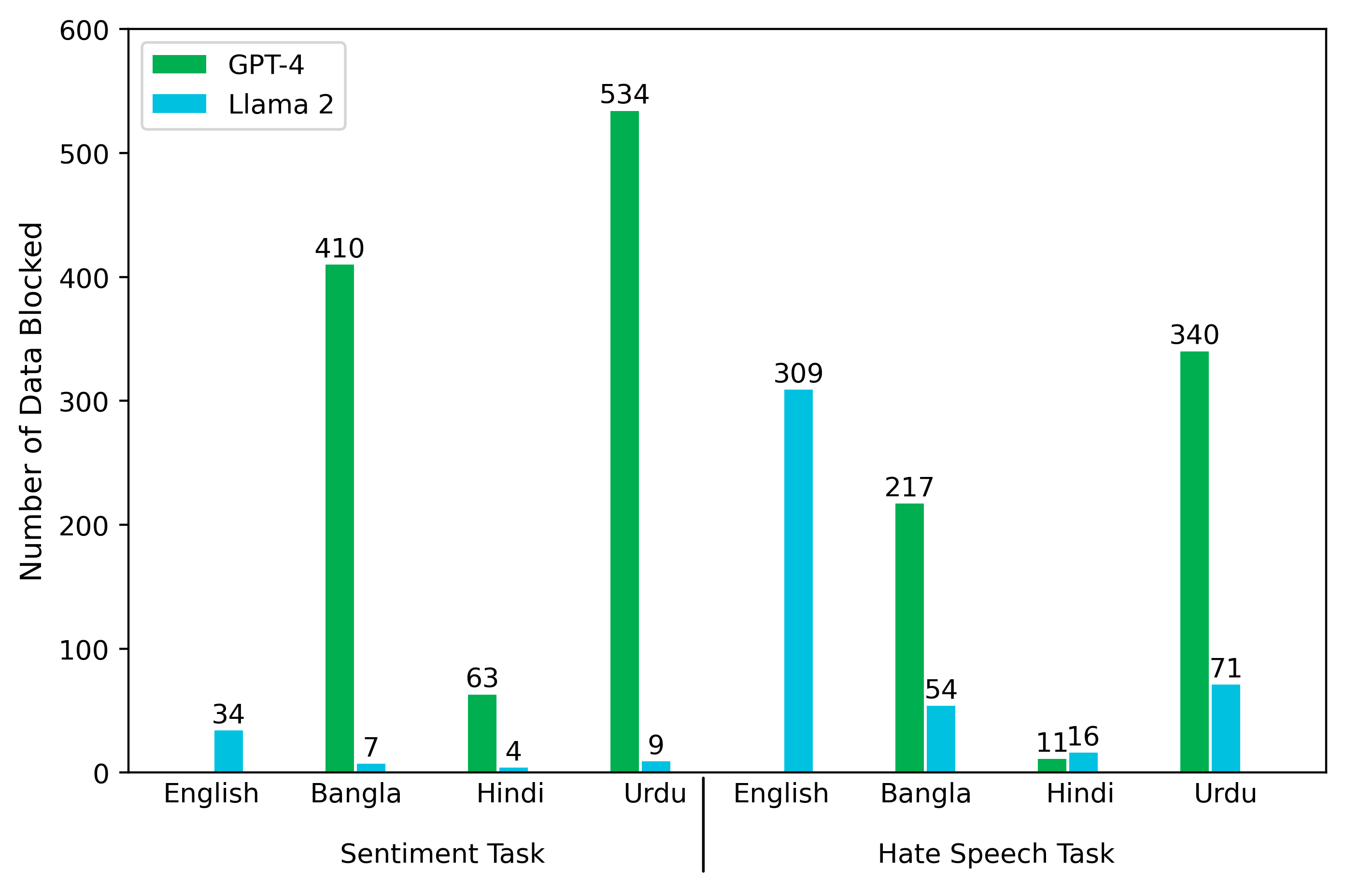
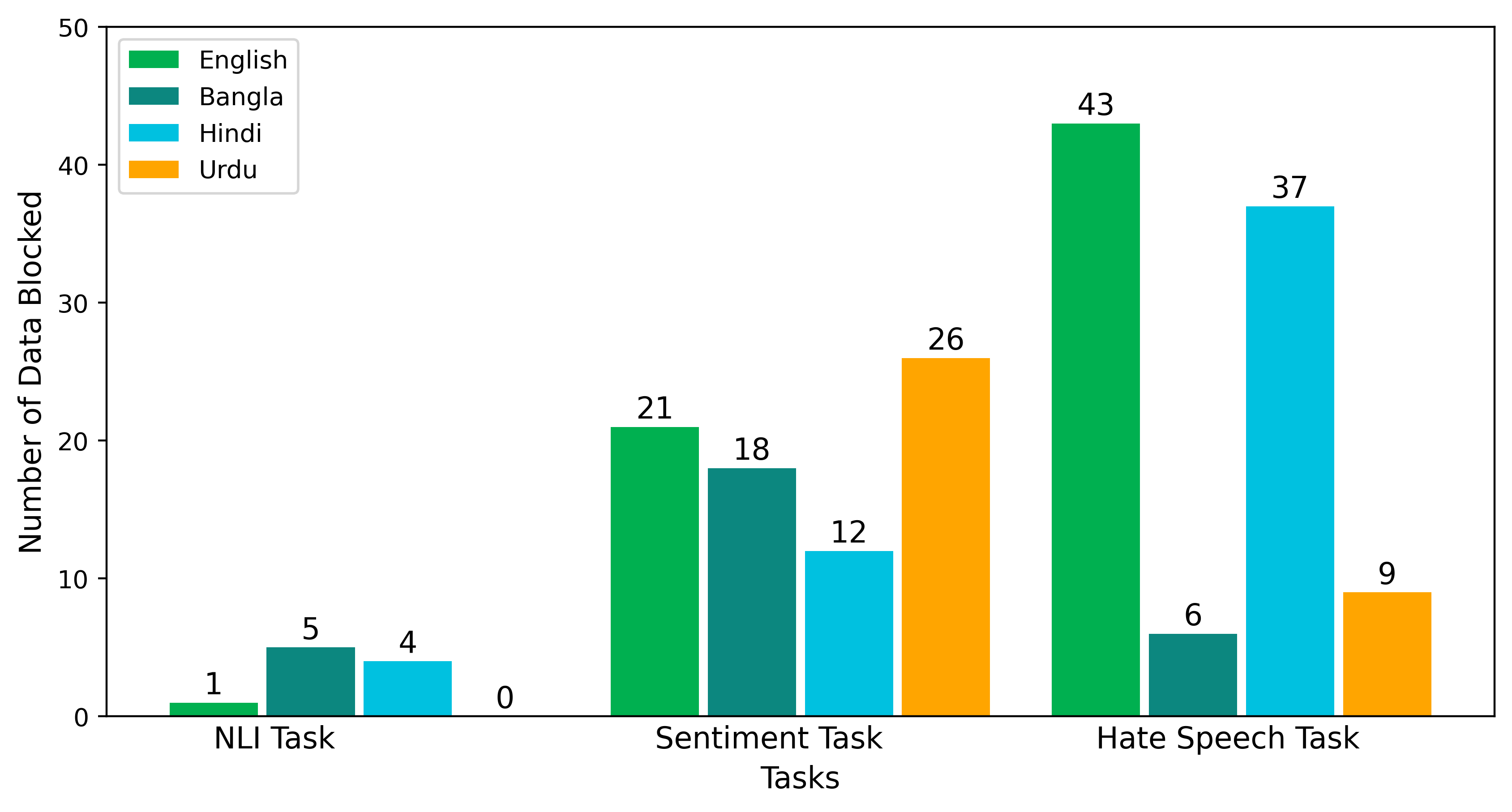
📊 实验亮点
实验结果表明,GPT-4在所有任务和语言上的表现均优于Llama 2和Gemini。然而,所有LLM在英语上的表现始终优于低资源语言,表明LLM在低资源语言处理方面仍存在挑战。自然语言推理(NLI)任务表现最佳,GPT-4在该任务上表现出卓越的能力。
🎯 应用场景
该研究成果可应用于多语言情感分析、舆情监控、仇恨言论检测等领域。通过提升LLM在低资源语言上的性能,可以更好地服务于全球用户,促进文化交流和理解,并为相关政策制定提供数据支持。未来,该研究可扩展到更多低资源语言和任务,进一步提升LLM的通用性和鲁棒性。
📄 摘要(原文)
Large language models (LLMs) have garnered significant interest in natural language processing (NLP), particularly their remarkable performance in various downstream tasks in resource-rich languages. Recent studies have highlighted the limitations of LLMs in low-resource languages, primarily focusing on binary classification tasks and giving minimal attention to South Asian languages. These limitations are primarily attributed to constraints such as dataset scarcity, computational costs, and research gaps specific to low-resource languages. To address this gap, we present datasets for sentiment and hate speech tasks by translating from English to Bangla, Hindi, and Urdu, facilitating research in low-resource language processing. Further, we comprehensively examine zero-shot learning using multiple LLMs in English and widely spoken South Asian languages. Our findings indicate that GPT-4 consistently outperforms Llama 2 and Gemini, with English consistently demonstrating superior performance across diverse tasks compared to low-resource languages. Furthermore, our analysis reveals that natural language inference (NLI) exhibits the highest performance among the evaluated tasks, with GPT-4 demonstrating superior capabilities.