CodeACT: Code Adaptive Compute-efficient Tuning Framework for Code LLMs
作者: Weijie Lv, Xuan Xia, Sheng-Jun Huang
分类: cs.CL, cs.LG
发布日期: 2024-08-05
💡 一句话要点
CodeACT:面向代码大模型的代码自适应计算高效微调框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大模型 高效微调 数据采样 动态填充 计算效率 开源模型 代码生成
📋 核心要点
- 现有开源代码大模型性能落后于闭源模型,且依赖大量合成数据微调,导致训练效率低下。
- CodeACT框架通过复杂性和多样性感知采样(CDAS)选择高质量训练数据,并采用动态填充策略减少计算资源消耗。
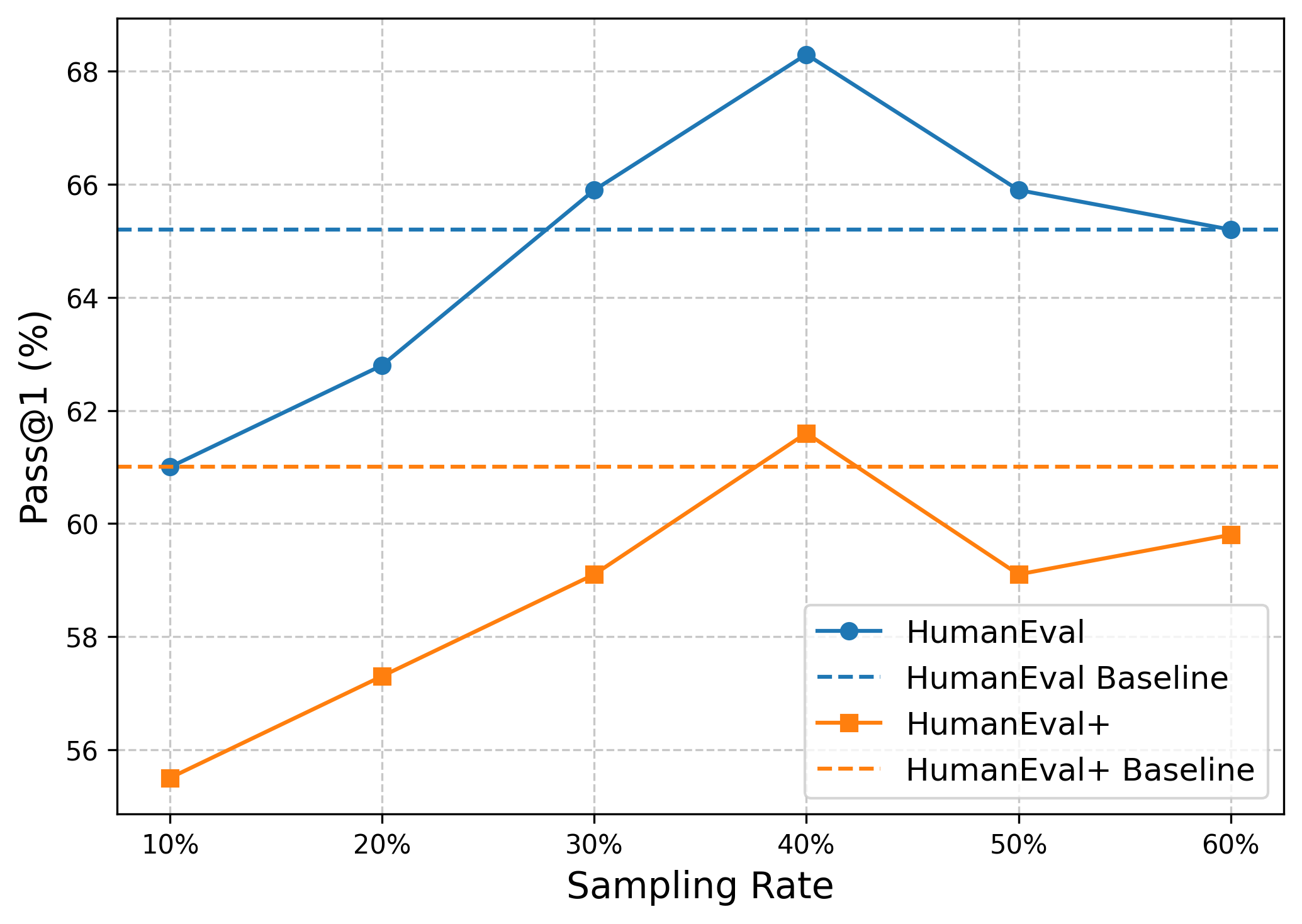
- 实验表明,CodeACT在减少训练时间和GPU内存使用的同时,显著提升了模型在HumanEval上的性能。
📝 摘要(中文)
大型语言模型(LLMs)在代码相关任务中展现出巨大潜力,但开源模型与闭源模型相比仍有差距。为了弥合这一性能差距,现有方法生成大量合成数据进行微调,导致训练效率低下。为了更有效和高效的训练,我们提出了代码自适应计算高效微调(CodeACT)框架。CodeACT引入了复杂性和多样性感知采样(CDAS)方法,以基于复杂性和多样性选择高质量的训练数据,并采用动态填充策略,通过最小化训练期间的填充token来减少计算资源的使用。实验结果表明,CodeACT-DeepSeek-Coder-6.7B仅在40%的EVOL-Instruct数据上进行微调,在HumanEval上实现了8.6%的性能提升,训练时间减少了78%,峰值GPU内存使用量减少了27%。这些发现强调了CodeACT增强开源模型性能和效率的能力。通过优化数据选择和训练过程,CodeACT提供了一种全面的方法来提高开源LLM的能力,同时显著降低计算需求,从而应对数据质量和训练效率的双重挑战,并为更具资源效率和高性能的模型铺平道路。
🔬 方法详解
问题定义:现有开源代码大模型在代码生成等任务中性能不足,与闭源模型存在差距。为了提升性能,通常采用大量合成数据进行微调,但这种方法效率低下,需要大量的计算资源,并且数据质量难以保证。因此,需要一种更高效、更经济的微调方法,能够在有限的计算资源下提升开源代码大模型的性能。
核心思路:CodeACT的核心思路是通过优化训练数据的选择和训练过程来提升模型性能和效率。具体来说,首先通过复杂性和多样性感知采样(CDAS)方法选择高质量的训练数据,减少冗余和低质量数据对训练的影响。然后,采用动态填充策略,减少训练过程中填充token的数量,从而降低计算资源的使用。
技术框架:CodeACT框架主要包含两个核心模块:复杂性和多样性感知采样(CDAS)和动态填充策略。CDAS模块负责从原始数据集中选择最具代表性和信息量的子集,用于后续的微调。动态填充策略则在训练过程中动态调整填充长度,以最小化填充token的数量,从而降低计算成本。整体流程是:原始数据集 -> CDAS采样 -> 动态填充 -> 模型微调。
关键创新:CodeACT的关键创新在于其综合考虑了数据质量和训练效率。CDAS方法能够有效地选择高质量的训练数据,避免了传统方法中大量低质量数据带来的负面影响。动态填充策略则能够显著降低训练过程中的计算资源消耗,使得在有限的计算资源下进行高效微调成为可能。与现有方法相比,CodeACT更加注重数据选择和训练过程的优化,从而在提升模型性能的同时降低了计算成本。
关键设计:CDAS方法通过计算每个样本的复杂度和与其他样本的差异性来评估其质量。复杂度可以使用代码的token数量、抽象语法树的深度等指标来衡量。差异性可以使用文本相似度、代码相似度等指标来衡量。动态填充策略则根据每个batch中样本的最大长度动态调整填充长度,避免了使用固定长度填充带来的资源浪费。损失函数采用标准的交叉熵损失函数,优化器采用AdamW。
🖼️ 关键图片


📊 实验亮点
CodeACT-DeepSeek-Coder-6.7B模型仅使用40%的EVOL-Instruct数据进行微调,在HumanEval上取得了8.6%的性能提升。同时,训练时间减少了78%,峰值GPU内存使用量减少了27%。这些结果表明,CodeACT能够在显著提升模型性能的同时,大幅降低计算资源的需求,具有很强的实用价值。
🎯 应用场景
CodeACT框架可应用于各种代码相关的任务,例如代码生成、代码补全、代码翻译和代码修复等。通过高效的微调,可以提升开源代码大模型在这些任务中的性能,使其能够更好地服务于软件开发人员,提高开发效率,降低开发成本。此外,CodeACT的资源高效性也使其能够在资源受限的环境下进行模型训练和部署,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) have shown great potential in code-related tasks, yet open-source models lag behind their closed-source counterparts. To bridge this performance gap, existing methods generate vast amounts of synthetic data for fine-tuning, leading to inefficiencies in training. Motivated by the need for more effective and efficient training, we propose the Code Adaptive Compute-efficient Tuning (CodeACT) framework. CodeACT introduces the Complexity and Diversity Aware Sampling (CDAS) method to select high-quality training data based on complexity and diversity, and the Dynamic Pack padding strategy to reduce computational resource usage by minimizing padding tokens during training. Experimental results demonstrate that CodeACT-DeepSeek-Coder-6.7B, fine-tuned on only 40% of the EVOL-Instruct data, achieves an 8.6% performance increase on HumanEval, reduces training time by 78%, and decreases peak GPU memory usage by 27%. These findings underscore CodeACT's ability to enhance the performance and efficiency of open-source models. By optimizing both the data selection and training processes, CodeACT offers a comprehensive approach to improving the capabilities of open-source LLMs while significantly reducing computational requirements, addressing the dual challenges of data quality and training efficiency, and paving the way for more resource-efficient and performant models.